大数据ClickHouse进阶(二十):MaterializeMySQL物化引擎深入了解

MaterializeMySQL物化引擎深入了解
在ClickHouse基础课程中我们知道可以使用两种方式通过ClickHouse可以操作MySQL数据库,分别使用使用 MySQL数据库引擎和MySQL表引擎。
一、MySQL数据库引擎
使用MySQL数据库引擎将远程MySQL服务器的表映射到ClickHouse中,允许对表进行Insert插入和Select查询,方便ClickHouse与MySQL之间进行数据交换。MySQL数据库引擎不会将MySQL的数据真正同步到ClickHouse存储中,ClickHouse就像一个壳子,可以将MySQL的表映射成ClickHouse表,使用ClickHouse查询MySQL中的数据,在MySQL中进行的CRUD操作,可以同时映射到ClickHouse中。
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,因此可以执行诸如SHOW TABLES或SHOW CREATE TABLE之类的操作,但是不允许创建表、修改表、删除数据、重命名操作。
MySQL数据库引擎语法如下:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MySQL('host:port', ['database' | database], 'user', 'password')二、MySQL表引擎
ClickHouse MySQL数据库引擎可以将MySQL某个库下的表映射到ClickHouse中,使用ClickHouse对数据进行操作。ClickHouse同样支持MySQL表引擎,即映射一张MySQL中的表到ClickHouse中,使用ClickHouse进行数据操作,与MySQL数据库引擎一样,这里映射的表只能做查询和插入操作,不支持删除和更新操作。
MySQL表引擎语法如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);实际上以上两种方式都是将ClickHouse中的SQL转换为MySQL语法并发送到MySQL服务器中执行,数据也没有存储在ClickHouse中。
三、MaterializeMySQL物化引擎
ClickHouse在20.8.2版本之后增加了MaterializeMySQL物化引擎,该引擎可以将MySQL中某个库下的所有表数据全量及增量实时同步到ClickHouse中,通过ClickHouse对MySQL中的数据进行高效的OLAP数据分析,降低线上MySQL的负载,将OLTP与OLAP业务完美结合。
MaterializeMySQL物化引擎实时同步MySQL中数据原理是将ClickHouse作为MySQL副本,读取MySQL binlog日志实时物化MySQL数据,在ClickHouse中会针对MySQL映射库下的每一张表都会创建一张ReplacingMergeTree表引擎。
MaterializeMySQL物化引擎特点如下:
- 支持MySQL库级别的数据同步,不支持表级别。
- MySQL库映射到ClickHouse中自动创建ReplacingMergeTree引擎表。
- 支持全量和增量同步,首次创建数据库引擎时进行一次全量复制,之后通过监控binlog变化进行增量数据同步。
- 支持MySQL5.6、5.7、5.8版本。
- 兼容支持MySQL中Insert、update、delete、alter、create、drop、truncate等大部分常用的DDL操作,不支持修改表名、修改列操作。支持添加列、删除列。
- 支持MySQL复制为GTID操作。从MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式。通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力。
1、开启MySQL binlog
使用MaterializeMySQL物化引擎首先需要开启MySQL binlog,开启步骤如下:
1.1、登录mysql查看MySQL是否开启binlog日志
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%'; ;
;
1.2、开启mysql binlog日志
在/etc/my.cnf文件中[mysqld]下写入以下内容:
[mysqld]
#随机指定一个不能和其他集群中机器重名的字符串
server-id=123
#配置binlog日志目录,配置后会自动开启binlog日志,并写入该目录
log-bin=/var/lib/mysql/mysql-bin
#设置binglog格式为Row
binlog_format=ROW
#开启GTID
gtid-mode=on
#设置为主从强一致性
enforce-gtid-consistency=11.3、重启mysql 服务,重新查看binlog日志情况
[root@node2 ~]# service mysqld restart
[root@node2 ~]# mysql -u root -p123456
mysql> show variables like 'log_%';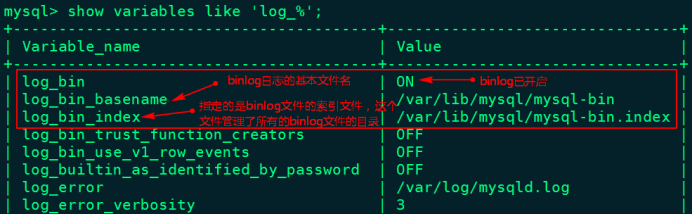 ;
;
2、使用MaterializedMySQL物化引擎
MaterializedMySQL物化引擎使用语法如下:
CREATE DATABASE [IF NOT EXISTS] db_name [ON CLUSTER cluster]
ENGINE = MaterializedMySQL('host:port', ['database' | database], 'user', 'password') [SETTINGS ...]以上参数解释如下:
- host:port:MySQL服务器的端口。
- database:MySQL数据库名称。
- user:登录MySQL用户名。
- password:登录MySQL密码。
使用MaterializeMySQL物化引擎步骤如下:
2.1、在MySQL中创建表person_info并插入数据
#创建数据库 ck_db并使用
mysql> create database ck_db;
mysql> use ck_db;
#创建表person_info,必须指定主键,否则后期无法映射物化表
mysql> create table person_info(id int,name varchar(255),age int,primary key (id));
#插入以下数据
mysql> insert into person_info values (1,"zs",18),(2,"ls",19),(3,"ww",20);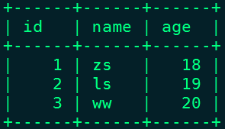 ;
;
2.2、在ClickHouse中开启Mysql物化引擎
由于MySQL物化引擎目前是实验阶段,在目前的ClickHouse版本中想要使用MySQL物化引擎,必须先设置参数开启。
set allow_experimental_database_materialized_mysql=1;2.3、在ClickHouse中创建MySQL物化引擎
#创建MaterializeMySQL物化引擎
CREATE DATABASE mysql_ck_db ENGINE = MaterializedMySQL('node2:3306', 'ck_db', 'root', '123456')
#在ClickHouse中使用mysql_ck_db库,并查询表
node1 :) use mysql_ck_db;
node1 :) show tables;
┌─name────────┐
│ person_info │
└─────────────┘
node1 :) select * from person_info;
┌─id─┬─name─┬─age─┐
│ 1 │ zs │ 18 │
└────┴──────┴─────┘
┌─id─┬─name─┬─age─┐
│ 2 │ ls │ 19 │
│ 3 │ ww │ 20 │
└────┴──────┴─────┘
node1 :) show create table person_info;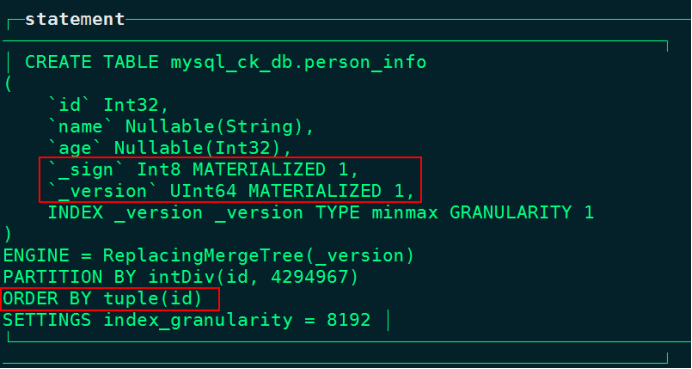 ;
;
注意:以上partition id按照长度为4294967进行分段分区。
测试向mysql表person_Info中插入数据
当向mysql表person_info中插入数据时,MaterializeMySQL物化引擎同步数据,操作如下:
#向mysql 表person_info中插入如下数据
mysql> insert into person_info values (4,"a1",21),(5,"a2",22),(6,"a3",23);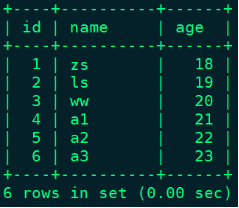 ;
;
#在ClickHouse中查询物化表person_info数据,数据实时变化
node1 :) select * from person_info;
┌─id─┬─name─┬─age─┐
│ 1 │ zs │ 18 │
│ 4 │ a1 │ 21 │
│ 5 │ a2 │ 22 │
└────┴──────┴─────┘
┌─id─┬─name─┬─age─┐
│ 2 │ ls │ 19 │
│ 3 │ ww │ 20 │
│ 6 │ a3 │ 23 │
└────┴──────┴─────┘- 测试更新mysql表数据
当对mysql表person_info进行修改时,MaterializeMySQL物化引擎同步数据,操作如下:
#更新mysql表中id=1对应的“zs”为“zhangsan”
mysql> update person_info set name = "zhangsan" where id =1;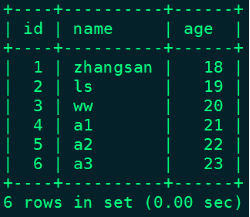 ;
;
#在ClickHouse中查询物化表person_info数据,数据实时更新
node1 :) select * from person_info;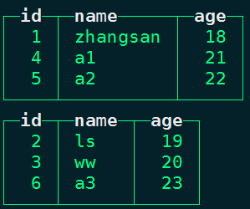 ;
;
- 测试删除mysql表数据
当对mysql表person_info进行删除时,MaterializeMySQL物化引擎同步数据,操作如下:
#删除mysql表中id=6对应的数据
mysql> delete from person_info where id =6; ;
;
#在ClickHouse中查询物化表person_info数据,数据实时更新
node1 :) select * from person_info; ;
;
- 测试删除、增加列
当对mysql表person_info增加和删除列时,MaterializeMySQL物化引擎同步列信息,操作如下:
#将mysql中person_info列age删除,增加score列
mysql> alter table person_info drop column age;
mysql> alter table person_info add column score int; ;
;
#在ClickHouse中查询person_info物化表
node1 :) select * from person_info;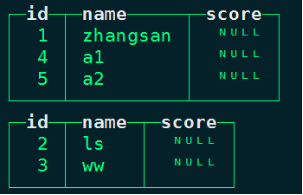 ;
;
- 测试删除表
当对mysql表person_info进行删除时,MaterializeMySQL物化引擎同步删除,操作如下:
#将mysql中person_info表删除
mysql> drop table person_info;
#在ClickHouse中默认也删除了person_info通过以上测试我们发现,在mysql中对表的增、删、改、删除等操作在ClickHouse中是实时同步的,本质原因是MaterializedMySQL物化引擎会默认为每一张表生成ReplacingMergeTree引擎表,这个引擎表中实际上还有2个额外字段“_sign”和“_version”,当ClickHouse遇到删除数据的binlog操作时,在ClickHouse对应的ReplacingMergeTree引擎表中只是标记性删除,并非物理上的实际删除,随着删除日志的增多,查询过滤会有一定的负担。
对以上内容操作如下:
#创建表person_info
mysql> create table person_info(id int,name varchar(255),age int,primary key (id));
#插入以下数据
mysql> insert into person_info values (1,"zs",18),(2,"ls",19),(3,"ww",20);
#在mysql中对id=1的数据进行删除,对id=2的数据进行修改
mysql> delete from person_info where id=1;
mysql> update person_info set name = "a1" where id=2;
#在ClickHouse中查询对应的person_info物化视图表
node1 :) select id,name,age,_sign,_version from person_info;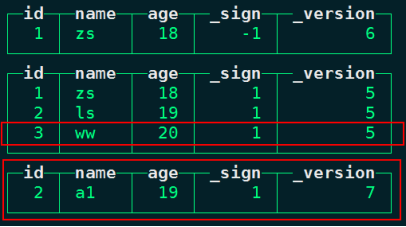 ;
;
注意:对MaterializedMySQL物化引擎表进行查询时,底层实际上是对对应的ReplacingMergeTree表进行查询,不需要指定额外的final修饰符,实际上查询直接过滤出“_sign”不等于-1且“_version”最大的结果数据。

- 点赞
- 收藏
- 关注作者
评论(0)