湖仓一体电商项目(二十四):合并Iceberg小文件

合并Iceberg小文件
Iceberg表每次commit都会生成一个parquet数据文件,有可能一张Iceberg表对应的数据文件非常多,那么我们通过Java Api 方式对Iceberg表可以进行数据文件合并,数据文件合并之后,会生成新的Snapshot且原有Snap快照数据并不会被删除,如果要删除对应的数据文件需要通过“Expire Snapshots来实现”。
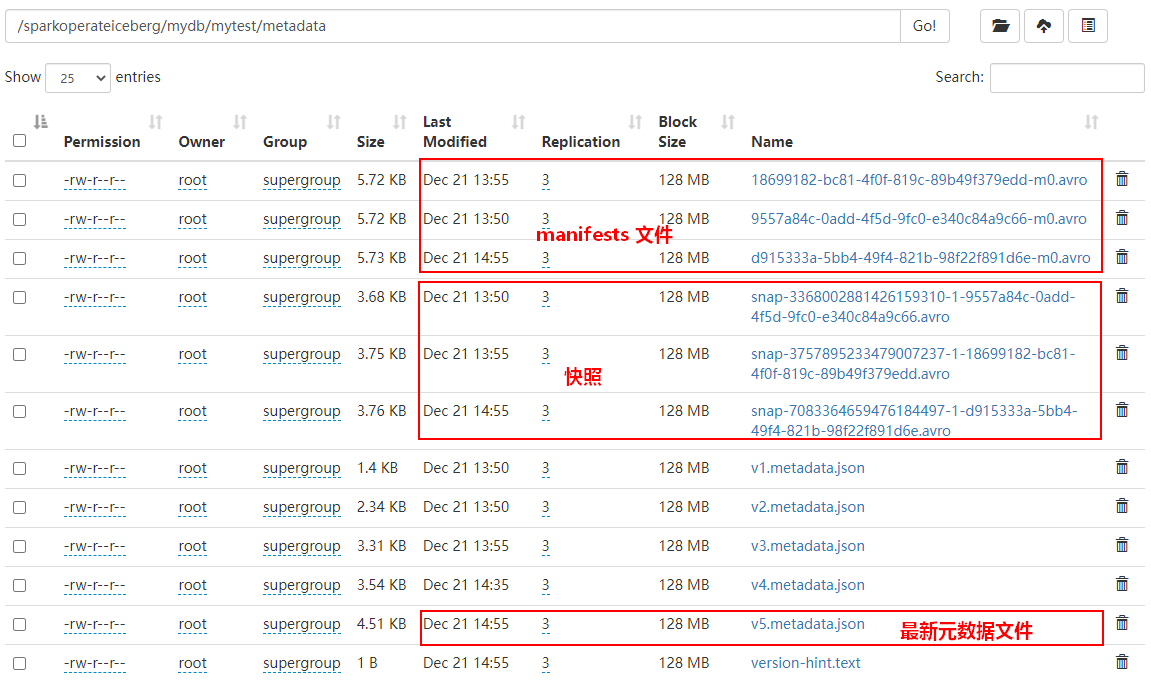
编辑我们可以通过Java Api 删除历史快照Snap-*.avro,可以通过指定时间戳,当前时间戳之前的所有快照都会被删除,如果指定时间比最后一个快照时间还大,会保留最新快照数据。
在删除快照时,数据data目录中过期的数据parquet文件也会被删除(例如:快照回滚后不再需要的文件),到底哪些parquet文件数据被删除决定于最后的“snap-xx.avro”中对应的manifest list数据对应的parquet数据。随着不断删除snapshot,在Iceberg表不再有manifest文件对应的parquet文件也会被删除。
每次Commit生成对应的Snapshot之外,还会有一份元数据文件“vX-metadata.json”文件产生,我们可以在创建Iceberg表时执行对应的属性决定Iceberg表保留几个元数据文件,属性如下:
|
Property |
Description |
|---|---|
|
write.metadata.delete-after-commit.enabled |
每次表提交后是否删除旧的元数据文件 |
|
write.metadata.previous-versions-max |
要保留旧的元数据文件数量 |
例如,在Spark中创建表 test ,指定以上两个属性,建表语句如下:
CREATE TABLE ${CataLog名称}.${库名}.${表名} (
id bigint,
name string
) using iceberg
PARTITIONED BY (
loc string
) TBLPROPERTIES (
'write.metadata.delete-after-commit.enabled'= true,
'write.metadata.previous-versions-max' = 3
)此项目中我们可以定期执行如下代码来删除Iceberg中过多的快照文件和数据文件,代码如下:
object CombinSnapAndRemoveOldSnap {
def main(args: Array[String]): Unit = {
val conf = new Configuration()
val catalog = new HadoopCatalog(conf,"hdfs://mycluster/lakehousedata")
/**
* 1.准备Iceberg表
*/
val table1: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_BROWSELOG"))
val table2: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_MEMBER_ADDRESS"))
val table3: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_MEMBER_INFO"))
val table4: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_PRODUCT_CATEGORY"))
val table5: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_PRODUCT_INFO"))
val table6: Table = catalog.loadTable(TableIdentifier.of("icebergdb","ODS_USER_LOGIN"))
val table7: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWD_BROWSELOG"))
val table8: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWD_USER_LOGIN"))
val table9: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWS_BROWSE_INFO"))
val table10: Table = catalog.loadTable(TableIdentifier.of("icebergdb","DWS_USER_LOGIN"))
/**
* 2.合并小文件数据,Iceberg合并小文件时并不会删除被合并的文件,Compact是将小文件合并成大文件并创建新的Snapshot。
* 如果要删除文件需要通过Expire Snapshots来实现,targetSizeInBytes 指定合并后的每个文件大小
*/
Actions.forTable(table1).rewriteDataFiles().execute()
Actions.forTable(table2).rewriteDataFiles().execute()
Actions.forTable(table3).rewriteDataFiles().execute()
Actions.forTable(table4).rewriteDataFiles().execute()
Actions.forTable(table5).rewriteDataFiles().execute()
Actions.forTable(table6).rewriteDataFiles().execute()
Actions.forTable(table7).rewriteDataFiles().execute()
Actions.forTable(table8).rewriteDataFiles().execute()
Actions.forTable(table9).rewriteDataFiles().execute()
Actions.forTable(table10).rewriteDataFiles().execute()
/**
* 3.删除历史快照,历史快照是通过ExpireSnapshot来实现的,设置需要删除多久的历史快照 snap-*.avro文件
*/
table1.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table2.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table3.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table4.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table5.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table6.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table7.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table8.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table9.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
table10.expireSnapshots().expireOlderThan(System.currentTimeMillis()).commit()
}
}
- 点赞
- 收藏
- 关注作者
评论(0)