湖仓一体电商项目(二十三):离线业务 统计每天用户商品浏览所获积分

【摘要】 统计每天用户商品浏览所获积分一、业务需求使用Iceberg构建湖仓一体架构进行数据仓库分层,通过Flink操作各层数据同步到Iceberg中做到的离线与实时数据一致,当项目中有一些离线临时性的需求时,我们可以基于Iceberg各层编写SQL进行数据查询,针对Iceberg DWS层中的数据我们可以编写SQL进行离线数据指标分析。当前离线业务根据Iceberg-DWS层中商品浏览宽表数据“D...
统计每天用户商品浏览所获积分
一、业务需求
使用Iceberg构建湖仓一体架构进行数据仓库分层,通过Flink操作各层数据同步到Iceberg中做到的离线与实时数据一致,当项目中有一些离线临时性的需求时,我们可以基于Iceberg各层编写SQL进行数据查询,针对Iceberg DWS层中的数据我们可以编写SQL进行离线数据指标分析。
当前离线业务根据Iceberg-DWS层中商品浏览宽表数据“DWS_BROWSE_INFO”进行查询每天每个用户商品浏览所获积分信息。
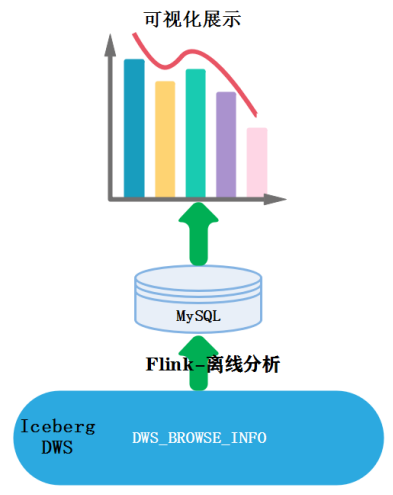
二、业务流程图
这里通过Flink代码读取Iceberg-DWS层宽表数据,编写SQL进行指标分析,将分析结果存储在MySQL中,此业务流程图如下所示:
三、业务实现
1、代码编写
此业务代码详细如下:
object UserPointsAnls {
def main(args: Array[String]): Unit = {
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val tblEnv: StreamTableEnvironment = StreamTableEnvironment.create(env)
import org.apache.flink.api.scala._
//1.创建Catalog
tblEnv.executeSql(
"""
|create catalog hadoop_iceberg with (
| 'type'='iceberg',
| 'catalog-type'='hadoop',
| 'warehouse'='hdfs://mycluster/lakehousedata'
|)
""".stripMargin)
//2.使用当前Catalog
tblEnv.useCatalog("hadoop_iceberg")
//3.使用数据库
tblEnv.useDatabase("icebergdb")
val userPointTbl :Table = tblEnv.sqlQuery(
"""
| select log_time as dt,user_id,product_name,sum(cast(obtain_points as int)) as total_points from DWS_BROWSE_INFO
| group by log_time,user_id,product_name
""".stripMargin)
val userPointDS: DataStream[(Boolean, Row)] = tblEnv.toRetractStream[Row](userPointTbl)
/**
* 4.需要在MySQL resultdb 中创建表 user_points
* create database resultdb;
* create table user_points (log_time varchar(255),user_id varchar(255),product_name varchar(255),total_points bigint);
*/
val jdbcOutput: JdbcOutputFormat = JdbcOutputFormat.buildJdbcOutputFormat().setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://node2:3306/resultdb?user=root&password=123456")
.setQuery("insert into user_points values (?,?,?,?)")
.finish()
userPointDS.map(_._2).writeUsingOutputFormat(jdbcOutput)
env.execute()
}
}2、代码执行
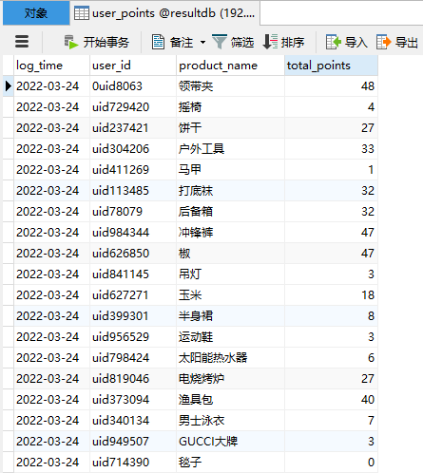
代码执行之前,我们需要登录MySQL创建库“resultdb”以及表user_points:
#在node2节点上执行如下命令
[root@node2 ~]# mysql -u root -p123456
mysql> create database resultdb;
mysql> use resultdb;
mysql> create table user_points(log_time varchar(255),user_id varchar(255),product_name varchar(255),total_points bigint);创建完成之后,可以直接执行以上代码,代码执行完成之后,在mysql表“resultdb.user_points”中可以查看对应的结果:
四、数据发布接口
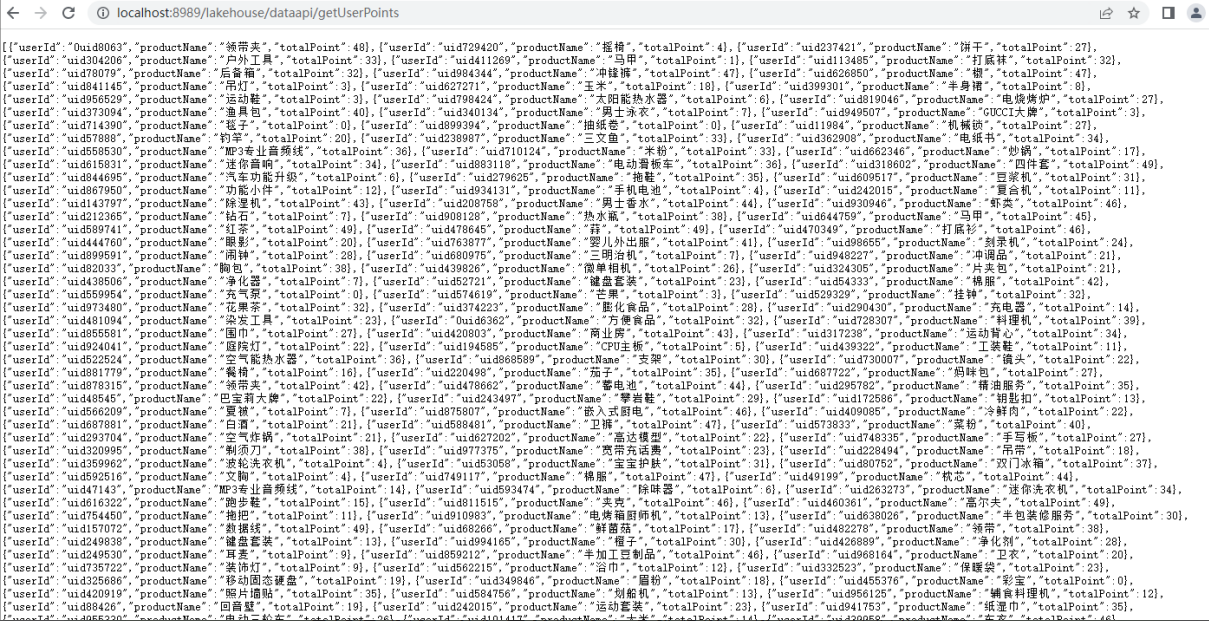
此离线业务对应的接口在数据发布接口项目“LakeHouseDataPublish”,对应的数据发布接口为:”localhost:8989/lakehouse/dataapi/getUserPoints”,启动数据发布接口,查询结果如下:
五、数据可视化
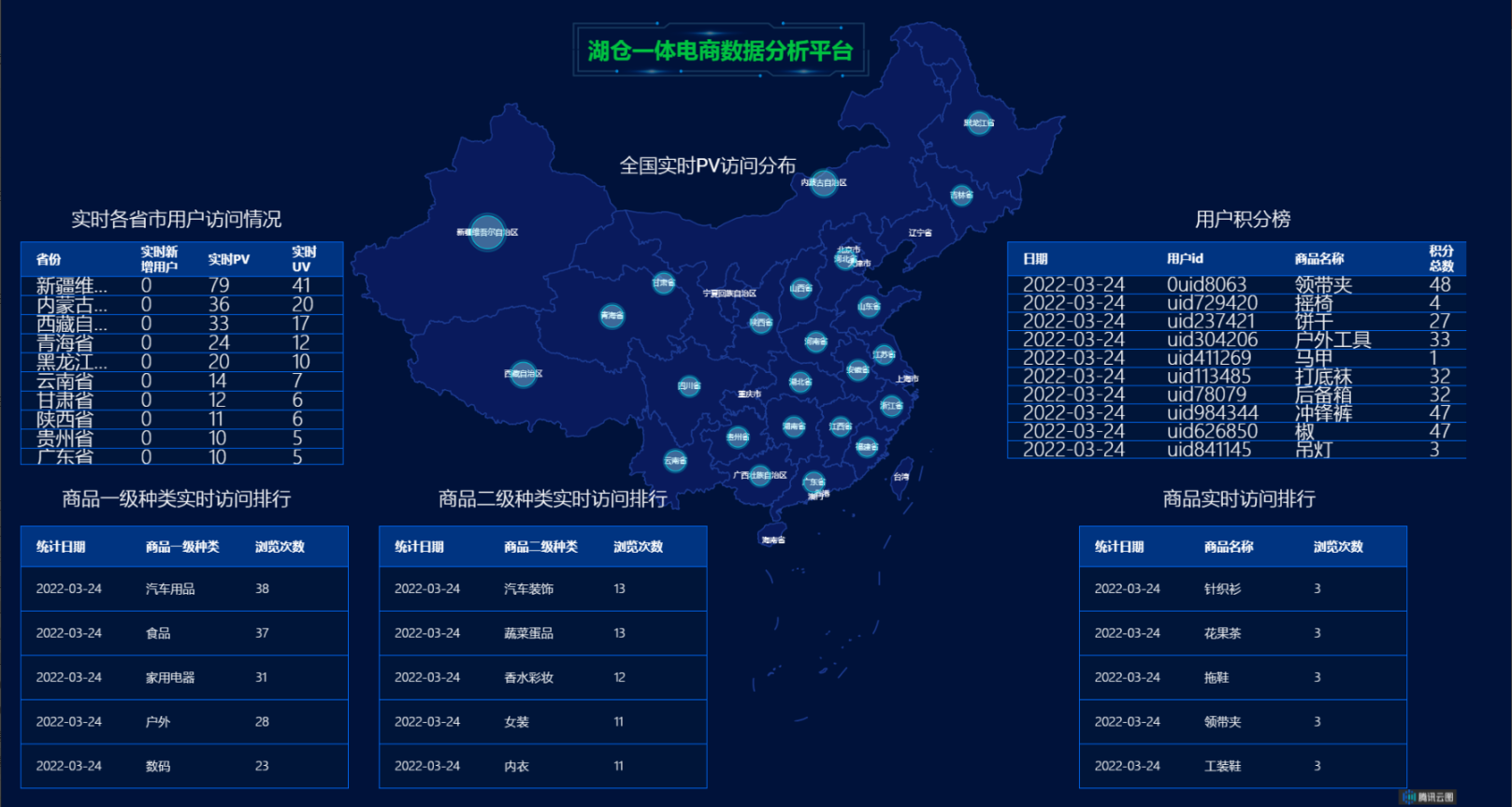
首先启动内网穿透工具映射本地数据发布接口,打开腾讯云图https://console.cloud.tencent.com/tcv,新建大屏,添加接口及对应数据,设计组织以下大屏结果:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)