Excel 文件的读取

1. 打开Excel 文档
Excel 文档创建完成后,为了读取 Excel 文档。首先需要打开 Excel 文档。代码如下:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)在上面的代码中,首先导入第三方库 openpyxl。接着使用 load_workbook 方法来读取 Excel 文档,在使用 load_workbook 时,只需要向 load_workbook 方法传入要打开文档的名称即可。最后,可以通过 type 函数查看打开的文档的类型。文档 example.xlsx 的内容如下所示:

2. 从工作簿取得工作表
从工作簿中取得工作表之前,首先看下工作簿中包含哪些工作表,接上面的代码,添加如下代码:wb.sheetnames 上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames从输出结果中看到,工作簿总共包含了三个工作表,分别是:Sheet1、Sheet2、Sheet3。接着上面的代码,添加如下代码:
ws = wb['Sheet3']
ws.title上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames
ws = wb['Sheet3']
ws.title上面代码中,通过object[name]的方式来获取工作表,想要获取哪个工作表,只需要传入工作表的名称即可。另外,我们还可以通过对象的 active 属性来获取当前活跃的工作表。接着上面的代码,添加如下代码:
ws = wb.active
ws.title上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames
ws = wb['Sheet3']
ws.title
ws = wb.active
ws.title这样便通过对象的 active 属性获取到当前活跃的工作表。
3. 从工作表中取得单元格
上面讲到了从工作簿中获取工作表,下面来讲从工作表中获取单元格。接着上面的代码,添加如下代码:
ws = wb['Sheet1']
wc = ws['A1']
wc.value上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames
ws = wb['Sheet3']
ws.title
ws = wb.active
ws.title
ws = wb['Sheet1']
wc = ws['A1']
wc.value上面添加的代码首先获取工作表 Sheet1,然后通过object[name]的方式工作表中的单元格。这样便获取到了单元格 A1,并通过单元格的属性 value 获取到了单元格中所包含的值。当列数较小时,使用字母来指定某个列并没有太多不方便,但是当列数逐渐增加,特别是在 Z 列之后,列开始使用两个字母 AA、AB、AC 等,这时候再通过字母来指定列时,便有诸多不便。这时候可以使用 cell() 方法来获取工作表中的单元格,在调用 cell() 方法时,传入参数 row 和 column。接着上面的代码,添加如下代码:
ws = wb['Sheet1']
wc = ws.cell(row=1, column=2)
wc.value上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames
ws = wb['Sheet3']
ws.title
ws = wb.active
ws.title
ws = wb['Sheet1']
wc = ws['A1']
wc.value
ws = wb['Sheet1']
wc = ws.cell(row=1, column=2)
wc.value上面添加的代码获取了 B1 单元格。在使用方法 cell() 方法获取单元格时,列和行的序号都是从 1 开始的。有了 cell() 方法,可以很方便地通过循环一次获取多个单元格。接着上面的代码,添加如下代码:
for i in range(1, 8, 2):
print(ws.cell(row=i, column=2).value)上述代码添加后的完整代码为:
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
type(wb)
wb.sheetnames
ws = wb['Sheet3']
ws.title
ws = wb.active
ws.title
ws = wb['Sheet1']
wc = ws['A1']
wc.value
ws = wb['Sheet1']
wc = ws.cell(row=1, column=2)
wc.value
for i in range(1, 8):
print(ws.cell(row=i, column=2).value)添加的代码获取到了第二列从第一行到第七行的单元格的值。
4. 列字母和数字之间的转换
由于 Excel 文档中的列名是使用字母来表示的,当别数较大时,通过字母不能很方便的得出是第几行。不过,openpyxl 模块提供了 column_index_from_string() 方法,使用此方法可以很方便的得出字母列所对应的列数。举例代码如下:
from openpyxl.utils import column_index_from_string
column_index_from_string('A')
column_index_from_string('AA')
column_index_from_string('AHP')上面的代码得到了列 A、AA、AHP 所对应的列数分别为 1、27、900。
5. 遍历行和列
5.1 遍历所有行的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for row in ws.rows:
for item in row:
print(item.value)
print('--- END OF ROW ---')上面代码我们以行的方向遍历了所有的单元格。使用了二层循环,第一次循环获取所有的行,第二层循环获取每行中的每个单元格。
5.2 遍历所有列的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for col in ws.columns:
for item in col:
print(item.value)
print('--- END OF COL ---')上面代码我们以列的方向遍历了所有的单元格。使用了二层循环,第一次循环获取所有的列,第二层循环获取每列中的每个单元格。
5.3 遍历单行的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for cell in ws[2]:
print(cell.value)上面代码获取了第二行的所有单元格。
5.4 遍历单列的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for cell in ws['B']:
print(cell.value)5.5 遍历多行的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for row in ws[1:3]:
for cell in row:
print(cell.value)
print('--- END OF ROW ---')上述代码获取了第一行到第三行的所有单元格。
5.6 遍历多列的单元格
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for col in ws['A':'C']:
for cell in col:
print(cell.value)
print('--- END OF COL ---')上述代码获取了第一列到第三列的所有单元格。
5.7 遍历一个区域内的单元格
5.7.1 行优先
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for row in ws.iter_rows(min_row=4,max_row=5,min_col=2,max_col=3):
for cell in row:
print(cell.value)上面代码遍历的单元格如下图所示:
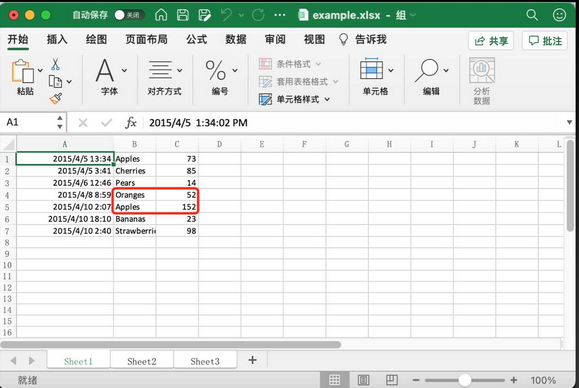
5.7.2 列优先
import openpyxl
wb = openpyxl.load_workbook("example.xlsx")
ws = wb['Sheet1']
for col in ws.iter_cols(min_row=4,max_row=5,min_col=2,max_col=3):
for cell in col:
print(cell.value)上面代码遍历的单元格如下图所示:
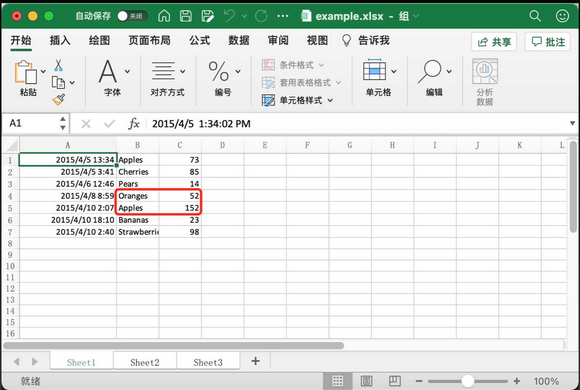

- 点赞
- 收藏
- 关注作者
评论(0)