湖仓一体电商项目(十八):业务实现之编写写入DWD层业务代码

【摘要】 业务实现之编写写入DWD层业务代码一、代码编写Flink读取Kafka topic “KAFKA-ODS-TOPIC” 数据写入Iceberg-DWD层也是复用第一个业务代码,这里只需要在代码中加入写入Iceberg-DWD层代码即可,代码如下://插入 iceberg - dwd 层 会员浏览商品日志信息 :DWD_BROWSELOGtblEnv.executeSql( s""" ...
业务实现之编写写入DWD层业务代码
一、代码编写
Flink读取Kafka topic “KAFKA-ODS-TOPIC” 数据写入Iceberg-DWD层也是复用第一个业务代码,这里只需要在代码中加入写入Iceberg-DWD层代码即可,代码如下:
//插入 iceberg - dwd 层 会员浏览商品日志信息 :DWD_BROWSELOG
tblEnv.executeSql(
s"""
|insert into hadoop_iceberg.icebergdb.DWD_BROWSELOG
|select
| log_time,
| user_id2,
| user_ip,
| front_product_url,
| browse_product_url,
| browse_product_tpcode,
| browse_product_code,
| obtain_points
| from ${table} where iceberg_ods_tbl_name = 'ODS_BROWSELOG'
""".stripMargin)另外,在Flink处理此topic中每条数据时都有获取对应写入后续Kafka topic信息,本业务对应的每条用户日志数据写入的kafka topic为“KAFKA-DWD-BROWSE-LOG-TOPIC”,所以代码可以复用。
二、创建Iceberg-DWD层表
代码在执行之前需要在Hive中预先创建对应的Iceberg表,创建Icebreg表方式如下:
1、在Hive中添加Iceberg表格式需要的包
启动HDFS集群,node1启动Hive metastore服务,在Hive客户端启动Hive添加Iceberg依赖包:
#node1节点启动Hive metastore服务
[root@node1 ~]# hive --service metastore &
#在hive客户端node3节点加载两个jar包
add jar /software/hive-3.1.2/lib/iceberg-hive-runtime-0.12.1.jar;
add jar /software/hive-3.1.2/lib/libfb303-0.9.3.jar;2、创建Iceberg表
这里创建Iceberg-DWD表有“DWD_BROWSELOG”,创建语句如下:
CREATE TABLE DWD_BROWSELOG (
log_time string,
user_id string,
user_ip string,
front_product_url string,
browse_product_url string,
browse_product_tpcode string,
browse_product_code string,
obtain_points string
)STORED BY 'org.apache.iceberg.mr.hive.HiveIcebergStorageHandler'
LOCATION 'hdfs://mycluster/lakehousedata/icebergdb/DWD_BROWSELOG/'
TBLPROPERTIES ('iceberg.catalog'='location_based_table',
'write.metadata.delete-after-commit.enabled'= 'true',
'write.metadata.previous-versions-max' = '3'
);三、代码测试
以上代码编写完成后,代码执行测试步骤如下:
1、在Kafka中创建对应的topic
#在Kafka 中创建 KAFKA-DWD-BROWSE-LOG-TOPIC topic
./kafka-topics.sh --zookeeper node3:2181,node4:2181,node5:2181 --create --topic KAFKA-DWD-BROWSE-LOG-TOPIC --partitions 3 --replication-factor 3
#监控以上topic数据
[root@node1 bin]# ./kafka-console-consumer.sh --bootstrap-server node1:9092,node2:9092,node3:9092 --topic KAFKA-DWD-BROWSE-LOG-TOPIC2、将代码中消费Kafka数据改成从头开始消费
代码中Kafka Connector中属性“scan.startup.mode”设置为“earliest-offset”,从头开始消费数据。
这里也可以不设置从头开始消费Kafka数据,而是直接启动向日志采集接口模拟生产日志代码“RTMockUserLogData.java”,需要启动日志采集接口及Flume。
3、执行代码,查看对应结果
以上代码执行后在,在对应的Kafka “KAFKA-DWD-BROWSE-LOG-TOPIC” topic中都有对应的数据。在Iceberg-DWD层中对应的表中也有数据。
Kafka中结果如下:

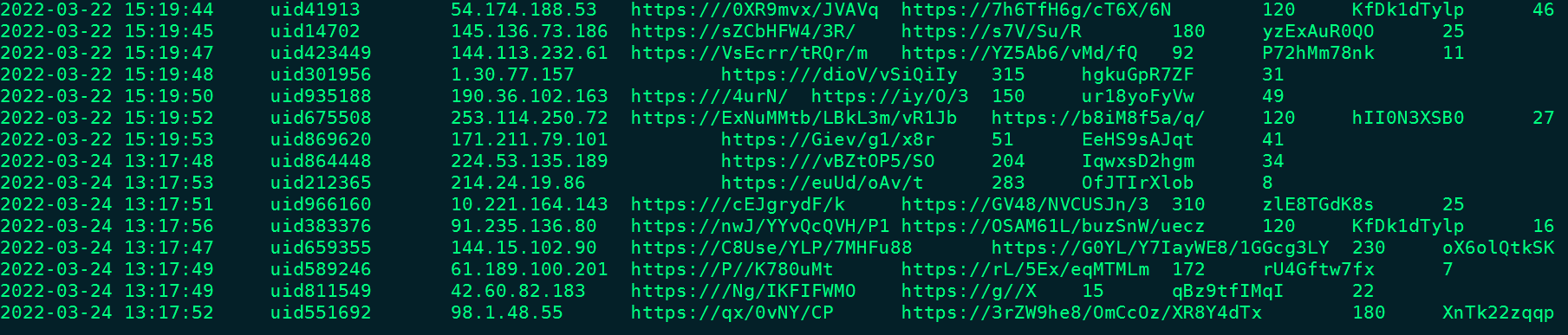
Iceberg-DWD层表”DWD_BROWSELOG”中的数据如下:

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)