requests的介绍

自动化获取页面的 HTML 代码所需要的第三方库 requests。
1.安装 requests
如果安装了 Anaconda,requests 就已经可用了。否则,需要在命令行下通过 pip 安装:pip install requests。
2.使用 requests
2.1 GET 方法
现在我们使用 requests 的 GET 方法来访问豆瓣网的主页。
import requests
response = requests.get('https://www.douban.com/')
print(response.status_code)在执行上述代码后,我们发现打印出的状态码为 418。我们都知道状态码为 200 的时候才是正确的,那么为什么返回了 418 呢?返回 418 是因为我们被识别为爬虫程序。解决的办法是在使用 GET 方法请求的时候添加 headers 信息。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
response = requests.get('https://www.douban.com/', headers=headers)
print(response.status_code)在添加头信息之后,我们发现状态码变成了 200,这说明响应是成功的。响应成功后,可以通过响应对象的属性或方法来得到响应对象的一些信息。
如果想以字节的方式查看响应的内容,可以使用响应对象的 content 属性。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
response = requests.get('https://www.douban.com/', headers=headers)
print(response.content)如果我们想将响应对象的内容转换成以 UTF-8 编码的字符串,可以使用响应对象的 text 属性。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
response = requests.get('https://www.douban.com/', headers=headers)
print(response.text)在将响应对象的内容转换成字符串时,需要指定编码,当我们没有明确指定编码时,requests 会根据响应对象的头来猜测编码,当然,我们也可以明确指定编码。例如:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
response = requests.get('https://www.douban.com/', headers=headers)
response.encoding = 'utf-8'
print(response.text)上面,我们得到了不同格式的响应内容。同样的,我们还可以获取响应的头。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
response = requests.get('https://www.douban.com/', headers=headers)
print(response.headers)
print(response.headers['Content-Type'])2.2 带参数的 GET 方法
对于 GET 请求,如果要附加额外的信息,一般怎样添加呢?比如现在想添加两个参数,其中 cat 是 1019,q 是 python。要构造这个请求链接,是不是要直接写成:response = requests.get(‘https://www.douban.com/search?cat=1019&q=python’)这样也可以,但是是不是有点不人性化呢?一般情况下,这种信息数据会用字典来存储。那么,怎么来构造这个链接呢?我们可以使用 params 参数。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51'
}
data = {
'cat': 1019,
'q': 'python'
}
response = requests.get('https://www.douban.com/search', headers=headers, params=data)
print(response.url)可以发现通过设置参数 params 而请求的 URL 和 https://www.douban.com/search?cat=1019&q=python 是相同的。
2.3 使用 Cookie 保持登录态
前面的课程中我们讲到,为了保持用户的登录状态,使用了 Cookie 技术。下面我们就来看下,如何在 GET 方法中使用 Cookie 来保持登录状态。首先,登录豆瓣,获取到 Cookie。
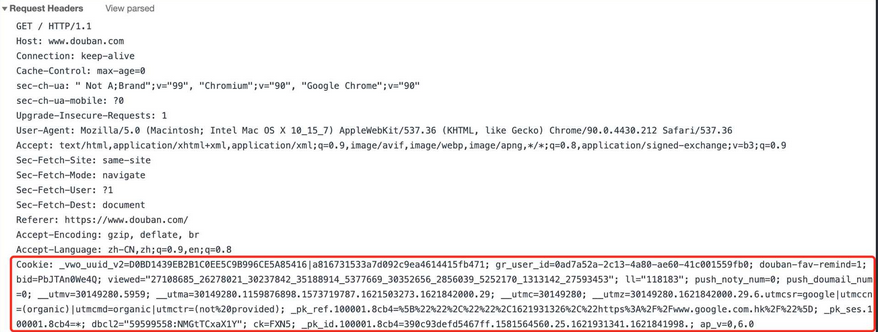
在 Request Headers 里便可以拿到 Cookie。下面将得到的 Cookie 放到 GET 方法中使用。
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51',
'Cookie': '_vwo_uuid_v2=D0BD1439EB2B1C0EE5C9B996CE5A85416|a816731533a7d092c9ea4614415fb471; gr_user_id=0ad7a52a-2c13-4a80-ae60-41c001559fb0; douban-fav-remind=1; bid=PbJTAn0We4Q; viewed="27108685_26278021_30237842_35188914_5377669_30352656_2856039_5252170_1313142_27593453"; ll="118183"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.5959; __utma=30149280.1159876898.1573719787.1621503273.1621842000.29; __utmc=30149280; __utmz=30149280.1621842000.29.6.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1621931326%2C%22https%3A%2F%2Fwww.google.com.hk%2F%22%5D; _pk_ses.100001.8cb4=*; dbcl2="59599558:NMGtTCxaX1Y"; ck=FXN5; _pk_id.100001.8cb4=390c93defd5467ff.1581564560.25.1621931341.1621841998.; ap_v=0,6.0'
}
response = requests.get('https://www.douban.com/', headers=headers)
print(response.text)从响应的内容来看,包含了登录后的结果。
2.4 代理设置
对于某些网站,在测试的时候请求几次,可以正常获取内容。但是一旦开始大规模爬取,对于大规模且频繁的请求,网站可能会弹出验证码,或者跳转到登录验证页面,更甚者可能会直接封禁客户端的 IP,导致一段时间内无法访问。为了防止这种情况的发生,需要设置代理来解决这个问题,这就需要用到 proxies 参数。可以如下设置:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36 Edg/90.0.818.51',
'Cookie': '_vwo_uuid_v2=D0BD1439EB2B1C0EE5C9B996CE5A85416|a816731533a7d092c9ea4614415fb471; gr_user_id=0ad7a52a-2c13-4a80-ae60-41c001559fb0; douban-fav-remind=1; bid=PbJTAn0We4Q; viewed="27108685_26278021_30237842_35188914_5377669_30352656_2856039_5252170_1313142_27593453"; ll="118183"; push_noty_num=0; push_doumail_num=0; __utmv=30149280.5959; __utma=30149280.1159876898.1573719787.1621503273.1621842000.29; __utmc=30149280; __utmz=30149280.1621842000.29.6.utmcsr=google|utmccn=(organic)|utmcmd=organic|utmctr=(not%20provided); _pk_ref.100001.8cb4=%5B%22%22%2C%22%22%2C1621931326%2C%22https%3A%2F%2Fwww.google.com.hk%2F%22%5D; _pk_ses.100001.8cb4=*; dbcl2="59599558:NMGtTCxaX1Y"; ck=FXN5; _pk_id.100001.8cb4=390c93defd5467ff.1581564560.25.1621931341.1621841998.; ap_v=0,6.0'
}
http_proxy = "http://10.10.1.10:3128"
https_proxy = "https://10.10.1.11:1080"
ftp_proxy = "ftp://10.10.1.10:3128"
proxyDict = {
"http": http_proxy,
"https": https_proxy,
"ftp": ftp_proxy
}
response = requests.get('https://www.douban.com/',
headers=headers, proxies=proxyDict)当然,上述代码中的代理无效的,如果想要上述代码能够运行,需要换成自己的有效的代理。
本节中介绍了 requests 的 GET 方法,包括如何附加参数、如何设置 headers、如何保持登录状态以及如何设置代理。

- 点赞
- 收藏
- 关注作者
评论(0)