爬虫实例——爬取豆瓣网 top250 电影的信息

本节通过一个具体的实例来看下编写爬虫的具体过程。以爬取豆瓣网 top250 电影的信息为例,top250 电影的网址为:https://movie.douban.com/top250。在浏览器的地址栏里输入 https://movie.douban.com/top250,我们会看到如下内容:
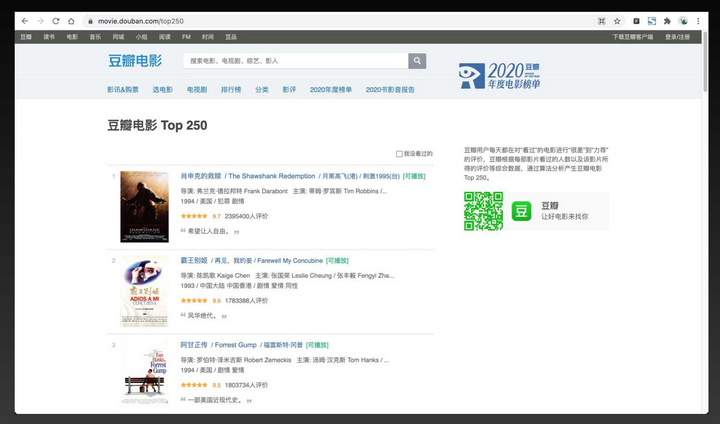
对于每一部电影需要爬取的内容如下图所示:

如上图所示,爬取的内容包括电影排名、电影名称、电影评分、电影属于哪个国家、电影类型、电影的上映时间以及电影的导演、主演。了解了要爬取哪些内容之后,接下来需要知道这些内容对应的 html 内容。

知道了对应的 html 内容之后,接下来就是解析 html,获取我们想要的内容。下面我们就逐步介绍爬取的过程:
1.获取 html
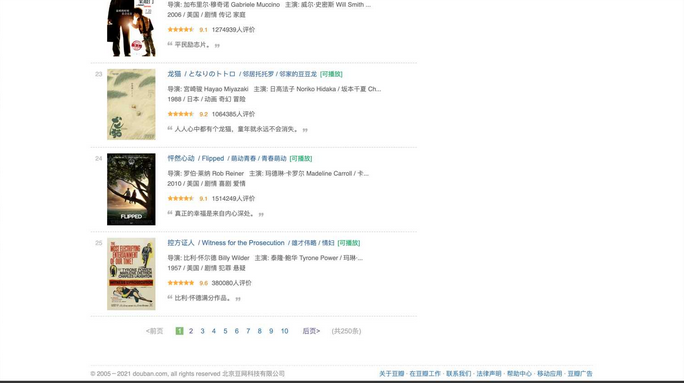
如上图所示,由于每页只展示 25 个电影的信息,要想获取所有电影的信息,需要通过一个循环来获取全部 10 页的内容。
1.1 导入所需的第三方库
import requests
from bs4 import BeautifulSoup
import time
import csv1.2 发送请求
1.2.1 设置 headers
由于豆瓣网会有反扒的机制,所以在请求网页的时候,需要设置headers。headers 的内容如下:
headers = {
'User-Agent': ******,
'Cookie': ******
}在实际运行时,需要将 ** 改成真实的 User-Agent 和 Cookie。
1.2.2 生成 url
第一页的 url 为:https://movie.douban.com/top250?start=0&filter=。第二页的 url 为:https://movie.douban.com/top250?start=25&filter=。第三页的 url 为:https://movie.douban.com/top250?start=50&filter=。从上面三个 url 的组成可以看出,只有 start 后面的数字在变,其他的都不变。我们可以根据这个规律来获取所有的 url。
1.2.3 发送请求获取响应
for i in range(10):
response = requests.get(
'https://movie.douban.com/top250?'+'start='+str(25*i)+'&filter=', headers=headers)2.解析 html
2.1 响应解析
soup = BeautifulSoup(response.text, 'lxml')
ol = soup.ol
all_li = ol.find_all('li')
for li in all_li:
rank = li.find('em', class_="").string
title = li.find('span', class_="title").string
rating = li.find('span', class_="rating_num").string
info = li.find('div', class_="bd").p.get_text().strip()
country = info.split('/')[-2]
genre = info.split('/')[-1]
release_time = info.split('\n')[1].split('/')[0].replace(" ", "")
director_actor = li.find('div', class_="bd").p.next_element.replace(
"\n", "").replace(" ", "")
ranks.append(rank)
titles.append(title)
ratings.append(rating)
countrys.append(country)
genres.append(genre)
release_times.append(release_time)
director_actors.append(director_actor)由上面的 html 内容可以看到,每部电影的信息处于<li></li>标签内,而所有的<li></li>标签又位于<ol></ol>标签内。于是,首先获取 ol 标签的内容,然后再获取所有的 li 标签的内容。获取到所有的 li 标签之后,对每个 li 标签进行遍历,获取我们想要的内容。在所有的内容获取完成后,将内容加入到相应的存储列表中。
3.存储内容
在获取我们想要的内容之后,将内容存储到 csv 文件。代码如下:
with open('top250.csv', 'w') as file:
writer = csv.writer(file, delimiter=',')
writer.writerow(["排名", "名称", "评分", "国家", "类型", "上映时间", "导演&主演"])
for i in range(250):
writer.writerow([
ranks[i],
titles[i],
ratings[i],
countrys[i],
genres[i],
release_times[i],
director_actors[i]
])4.完整代码
综合上面每一步的代码之后,便可以得到完整的代码:
import requests
from bs4 import BeautifulSoup
import time
import csv
headers = {
'User-Agent': ******,
'Cookie': ******
}
ranks = []
titles = []
ratings = []
inqs = []
countrys = []
genres = []
release_times = []
director_actors = []
for i in range(10):
response = requests.get(
'https://movie.douban.com/top250?'+'start='+str(25*i)+'&filter=', headers=headers)
soup = BeautifulSoup(response.text, 'lxml')
ol = soup.ol
all_li = ol.find_all('li')
for li in all_li:
rank = li.find('em', class_="").string
title = li.find('span', class_="title").string
rating = li.find('span', class_="rating_num").string
info = li.find('div', class_="bd").p.get_text().strip()
country = info.split('/')[-2]
genre = info.split('/')[-1]
release_time = info.split('\n')[1].split('/')[0].replace(" ", "")
director_actor = li.find('div', class_="bd").p.next_element.replace(
"\n", "").replace(" ", "")
ranks.append(rank)
titles.append(title)
ratings.append(rating)
countrys.append(country)
genres.append(genre)
release_times.append(release_time)
director_actors.append(director_actor)
time.sleep(3)
with open('top250.csv', 'w') as file:
writer = csv.writer(file, delimiter=',')
writer.writerow(["排名", "名称", "评分", "国家", "类型", "上映时间", "导演&主演"])
for i in range(250):
writer.writerow([
ranks[i],
titles[i],
ratings[i],
countrys[i],
genres[i],
release_times[i],
director_actors[i]
])5.结果
将获取到的内容存储到 csv 文件中。csv 文件的部分内容如下图所示:
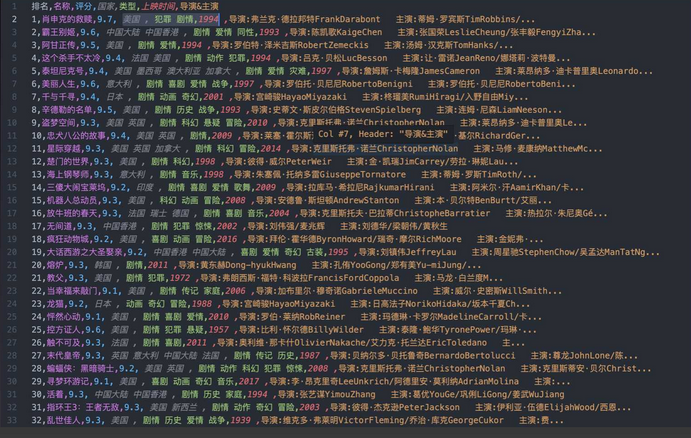
这样我们便完成了豆瓣 top250 电影信息的爬取。

- 点赞
- 收藏
- 关注作者
评论(0)