使用 Scrapy 框架来爬取数据

1.创建项目
创建一个 Scrapy 项目,项目文件可以直接用 scrapy 命令生成,命令如下所示:scrapy startproject doubanmovie250 这个命令可以在任意文件夹运行。如果提示权限问题,可以加 sudo 运行该命令。这个命令将会创建一个名为 doubanmovie250 的文件夹,文件夹结构如下所示:

2.创建Spider
Spider 是自己定义的类,Scrapy 用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法。也可以使用命令行创建一个Spider。比如要生成 doubanmovie250 这个 Spider,可以执行如下命令:scrapy genspider doubanmovie250 douban.com,进入刚才创建的 doubanmovie250 文件夹,然后执行 genspider 命令。第一个参数是 Spider 的名称,第二个参数是网站域名。执行完毕后,spiders 文件夹中多了一个 doubanmovie250.py,它就是刚刚创建的 Spider,内容如下所示:
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'doubanmovie250'
allowed_domains = ['douban.com']
start_urls = ['http://douban.com/']
def parse(self, response):
pass这里有三个属性————name、allowed_domains 和 start_urls,还有一个方法 parse。
-
name,它是每个项目唯一的名字,用来区分不同的 Spider。
-
allowed_domains,它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
-
start_urls,它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
-
parse,它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。由于我们要爬取的是top250电影信息,所以需要将 start_urls 修改为
['https://movie.douban.com/top250']修改后的代码如下所示:
import scrapy
class DoubanSpider(scrapy.Spider):
name = 'doubanmovie250'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
pass3.创建 Item
Item 是保存爬取数据的容器,它的使用方法和字典类似。创建 Item 需要继承 scrapy.Item 类,并且定义类型为 scrapy.Field 的字段,我们可以获取到的内容有rank、title、rating、country、genre、release_time 和 director_actor。将 items.py 修改如下:
import scrapy
class Doubanmovie250Item(scrapy.Item):
# define the fields for your item here like:
rank = scrapy.Field()
title = scrapy.Field()
rating = scrapy.Field()
country = scrapy.Field()
genre = scrapy.Field()
release_time = scrapy.Field()
director_actor = scrapy.Field()这里定义了七个字段,接下来爬取时我们会使用到这个 Item。
4.解析 Response
前面我们看到,parse() 方法的参数 response 是 start_urls 里面的连接爬取后的结果。所以在 parse() 方法中,我们可以直接对 response 变量包含的内容进行解析。解析的方法使用的是第 6 节中的方法,所不同的是将解析的结果赋值给 Item 的每个字段。代码如下:
def parse(self, response):
item = Doubanmovie250Item()
soup = BeautifulSoup(response.text, 'lxml')
ol = soup.ol
all_li = ol.find_all('li')
for li in all_li:
item['rank'] = li.find('em', class_="").string
item['title'] = li.find('span', class_="title").string
item['rating'] = li.find('span', class_="rating_num").string
info = li.find('div', class_="bd").p.get_text().strip()
item['country'] = info.split('/')[-2]
item['genre'] = info.split('/')[-1]
item['release_time'] = info.split('\n')[1].split('/')[0].replace(" ", "")
item['director_actor'] = li.find('div', class_="bd").p.next_element.replace(
"\n", "").replace(" ", "")
yield item如此一来,首页的所有内容被解析出来,并被赋值成了一个个 Doubanmovie250Item。
5.后续 Request
上面的操作实现了从初始页面抓取内容。那么,下一页的内容该如何抓取?这就需要我们从当前页面中找到信息来生成下一个请求,然后在下一个请求的页面里找到信息再构造下一个请求。这样循环往复迭代,从而实现整站的爬取。通过分析页面我们发现,可以通过解析后页这个标签的内容来获取下一个要爬取的链接,如下图所示:
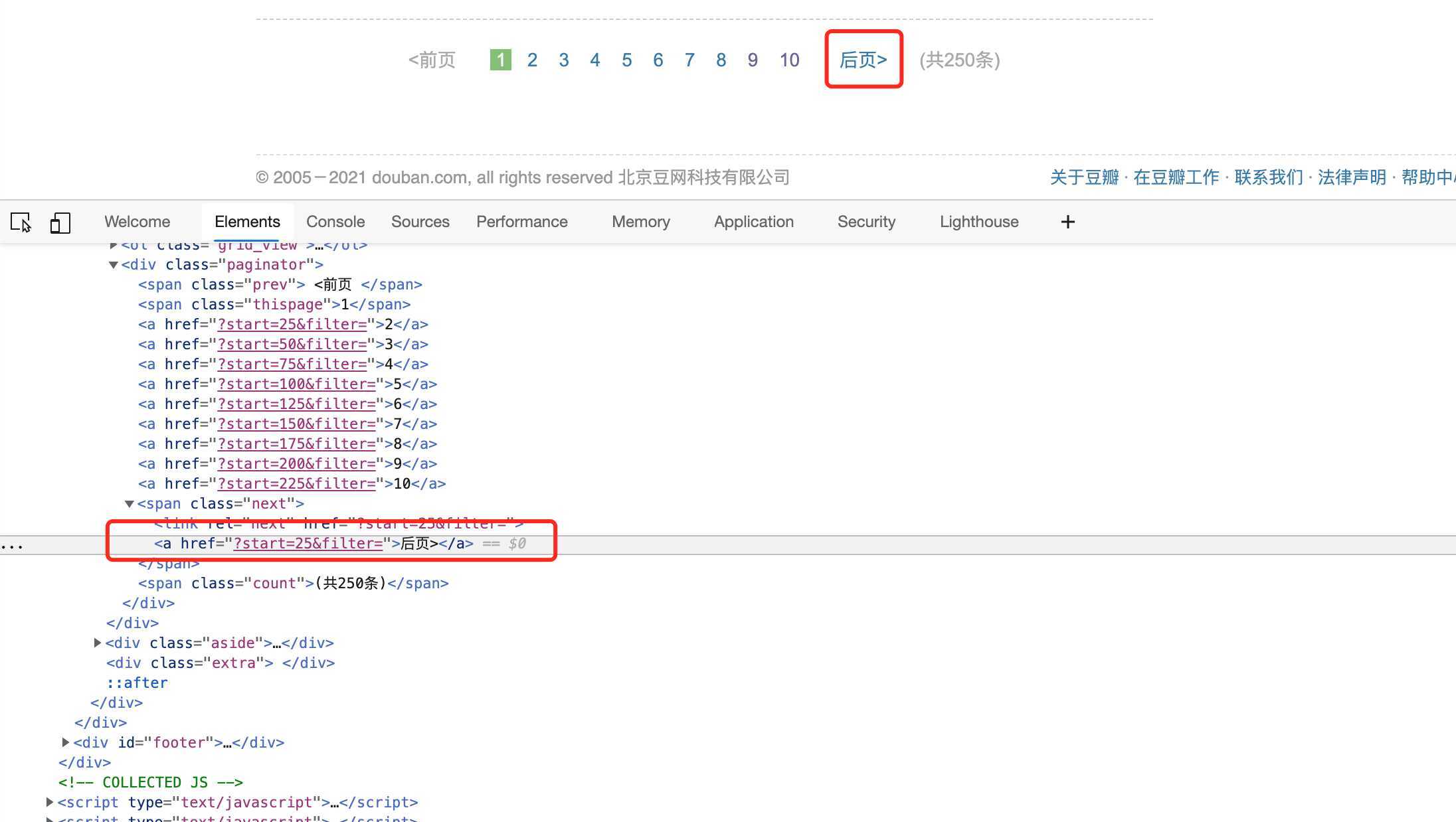
代码如下:
next = soup.find('span', class_='next').a
if next:
href = soup.find('span', class_='next').a['href']
url = 'https://movie.douban.com/top250' + href
yield scrapy.Request(url, callback=self.parse)和解析代码合并后的完整代码如下所示:
def parse(self, response):
item = Doubanmovie250Item()
soup = BeautifulSoup(response.text, 'lxml')
ol = soup.ol
all_li = ol.find_all('li')
for li in all_li:
item['rank'] = li.find('em', class_="").string
item['title'] = li.find('span', class_="title").string
item['rating'] = li.find('span', class_="rating_num").string
info = li.find('div', class_="bd").p.get_text().strip()
item['country'] = info.split('/')[-2]
item['genre'] = info.split('/')[-1]
item['release_time'] = info.split('\n')[1].split('/')[0].replace(" ", "")
item['director_actor'] = li.find('div', class_="bd").p.next_element.replace(
"\n", "").replace(" ", "")
yield item
next = soup.find('span', class_='next').a
if next:
href = soup.find('span', class_='next').a['href']
url = 'https://movie.douban.com/top250' + href
yield scrapy.Request(url, callback=self.parse)6.内容保存
由于我们想把爬取到的内容保存到 csv 文件,需要在 pipelines.py 文件中进行保存的操作。代码如下:
from itemadapter import ItemAdapter
import csv
class Doubanmovie250Pipeline:
def open_spider(self, spider):
self.file = open('top250.csv', 'w')
self.writer = csv.writer(self.file, delimiter=',')
self.writer.writerow(["排名", "名称", "评分", "国家", "类型", "上映时间", "导演&主演"])
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
self.writer.writerow([
item['rank'],
item['title'],
item['rating'],
item['country'],
item['genre'],
item['release_time'],
item['director_actor']
])
return item上面代码在 open_spider 方法中打开一个文件,在 close_spider 方法中关闭打开的文件,并在 process_item 方法中进行数据的写文件操作。
7.运行
接下来,进入目录,运行如下命令:scrapy crawl doubanmovie250就可以看到 scrapy 的运行结果了。保存后的 csv 文件如下所示:

本篇文章只是通过一个实例了解使用 Scrapy 框架爬取数据的整个过程。当然,这只是 Scrapy 强大功能的冰山一角,更多的强大功能还需要小伙伴自己在实践中逐步掌握。

- 点赞
- 收藏
- 关注作者
评论(0)