ABAP 调用第三方 API,遇到乱码该怎么办?

这是 Jerry 2022 年第二篇原创文章,也是本公众号第 370 篇原创文章。
之前有一个朋友在知乎上向我咨询过这个问题,我觉得很有代表性,所以专门用一篇文章来讲述一些相关知识点。
先看这位朋友遇到的具体问题。
用 Postman 调用第三方接口,里面的中文字符能够正常显示。
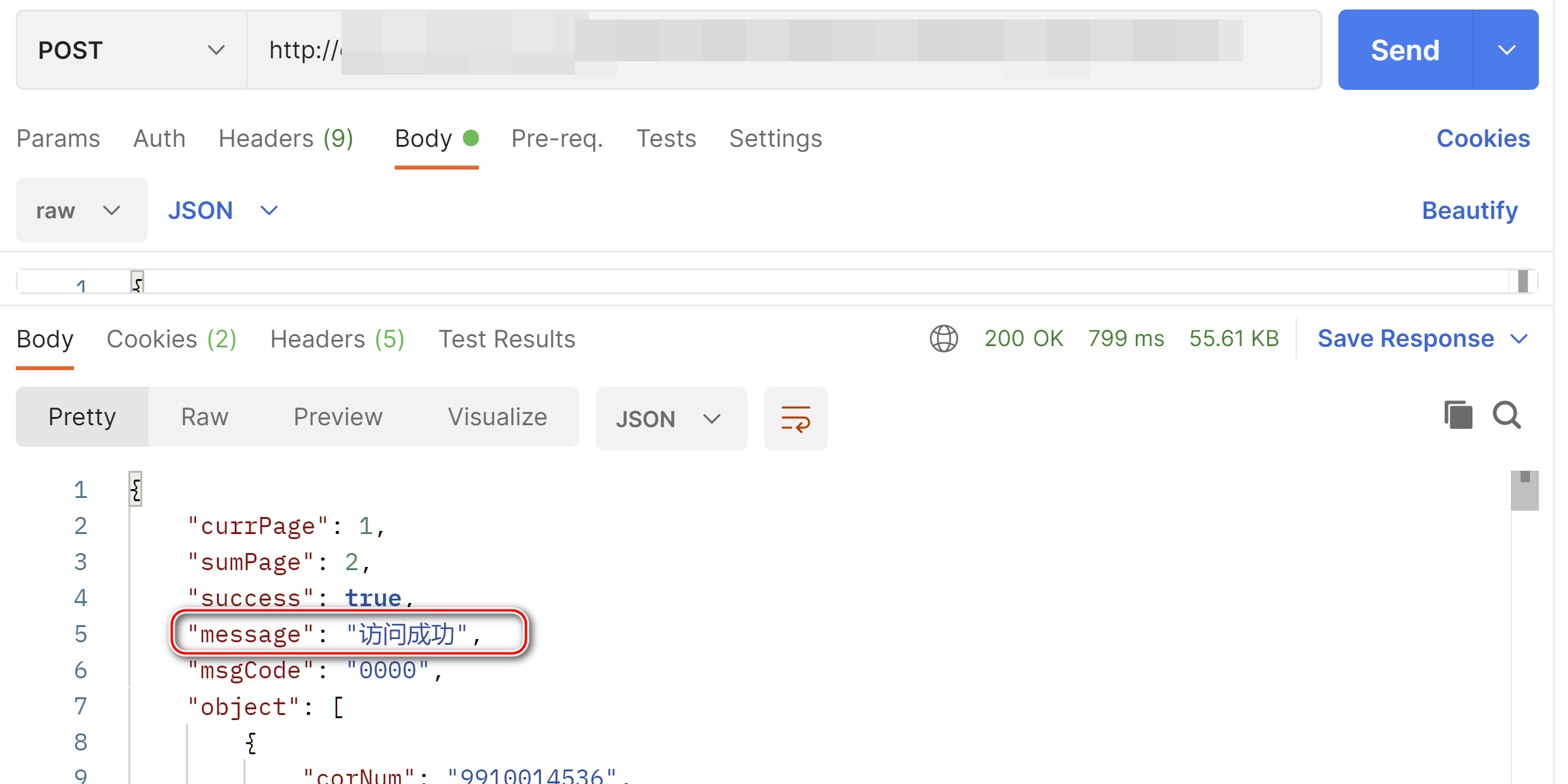
然而当用 ABAP 的 HTTP 工具类 CL_HTTP_CLIENT 的 response->get_data( ) 读取响应之后,发现里面的中文字符,例如 “访问成功” 是乱码:
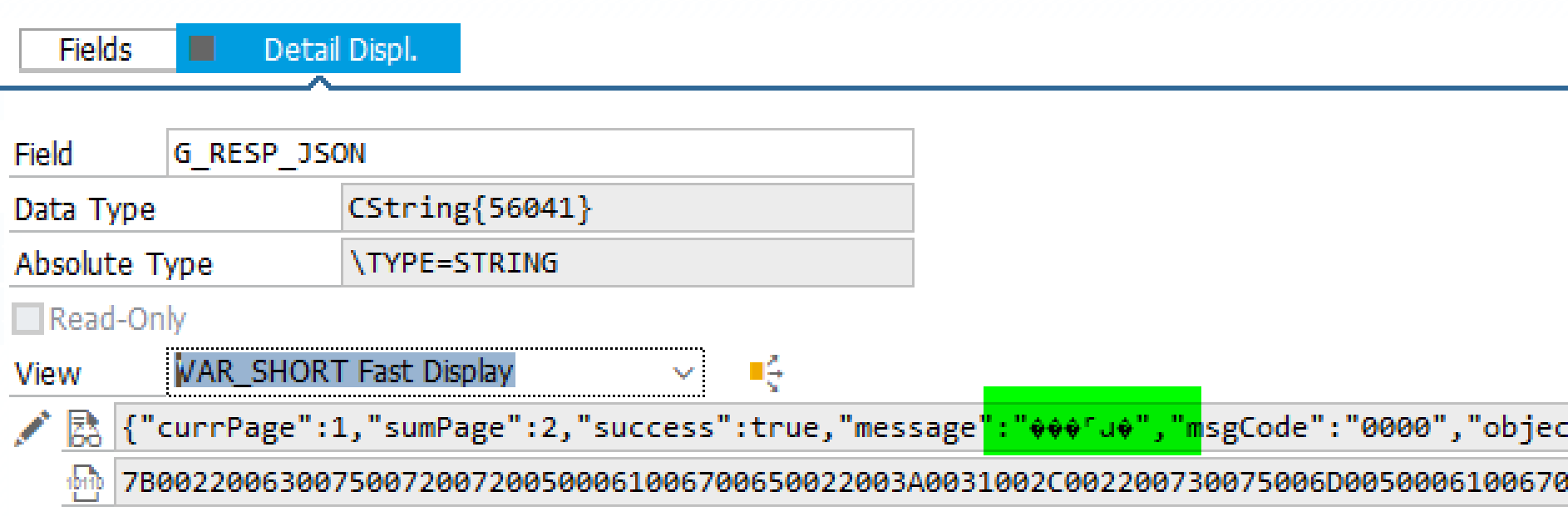
首先明确一点,既然 Postman 能正确显示响应数据中的中文内容,说明 API provider 是不存在问题的,这个乱码问题出现在接收方,即 ABAP 代码的编程实现需要调整。
我们只要弄清楚出现乱码的原因,就能有的放矢进行修复了。
上个世纪 60 年代,美国制定了一套字符编码,定义了英文字符与二进制位之间的一一映射关系,称为 ASCII 码。将一个符号的图形显示,关联到其二进制存储位的这种行为,就称之为字符编码。ASCII 就是一种最简单的字符集和字符编码方式。
一个字节有 8 位,2 的 8 次方为 256,因此 1 个字节只能表示 256 种符号,而汉字的总数超过了 10 万个,显然无法用 1 个字节来存储。
除了大家熟悉的英文字符和汉字外,还有很多历史更悠久的文字,比如埃及象形文字:
以及周杰伦《爱在西元前》里提到的楔形文字:

有没有这样一种计算机编码方式,能够将这些稀奇古怪的符号都纳入其中呢?有,这就是 Unicode,正如其命名暗示的,Unicode 将世界各种语言的每个字符都分配了一个唯一的编码,以满足跨语言、跨平台的文本信息转换。
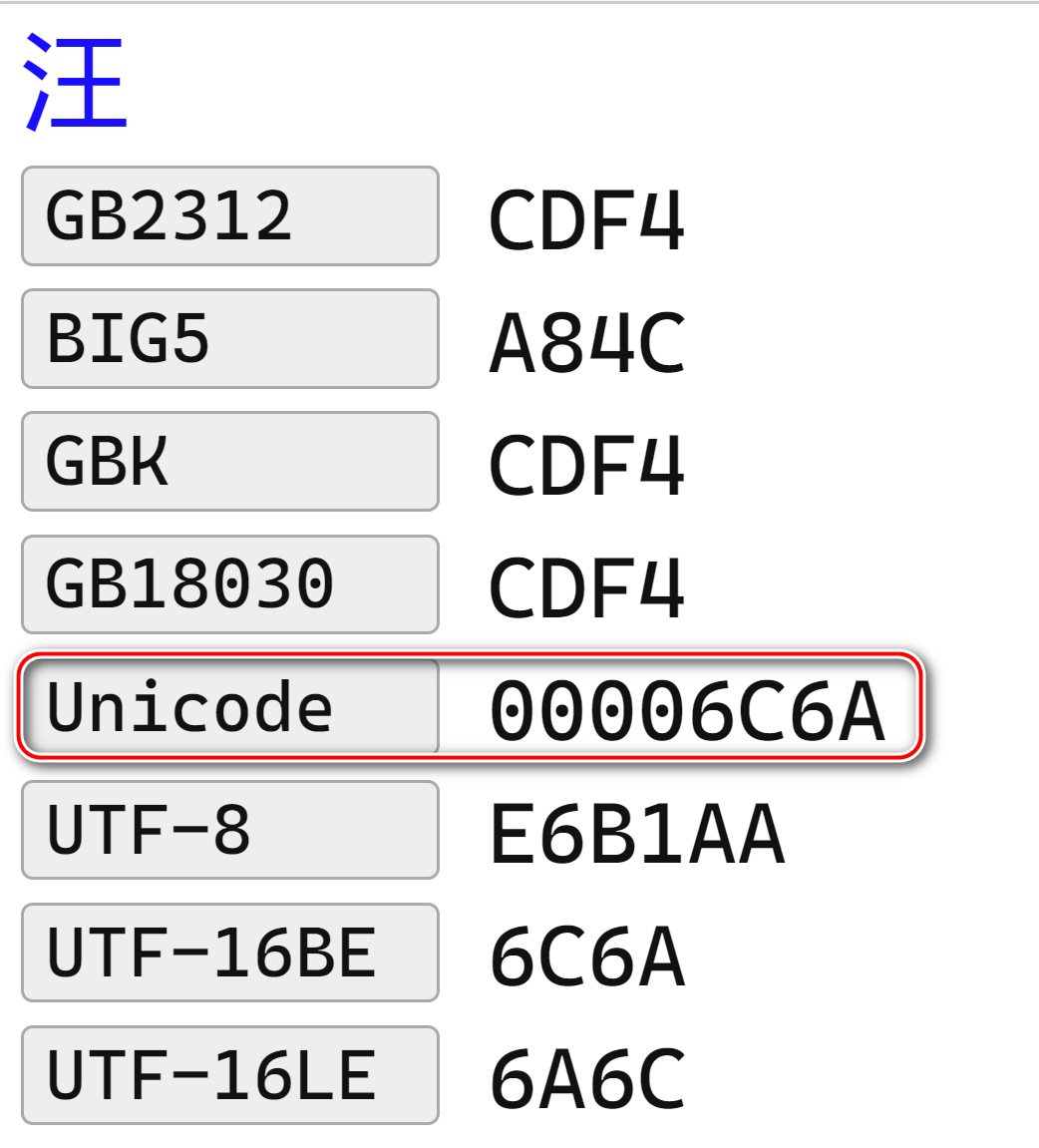
我们根据 Unicode 编码表,就能查到一个字符对应的 Unicode 编码,比如汉字 "汪"对应的 Unicode 编码为 00006C6A.
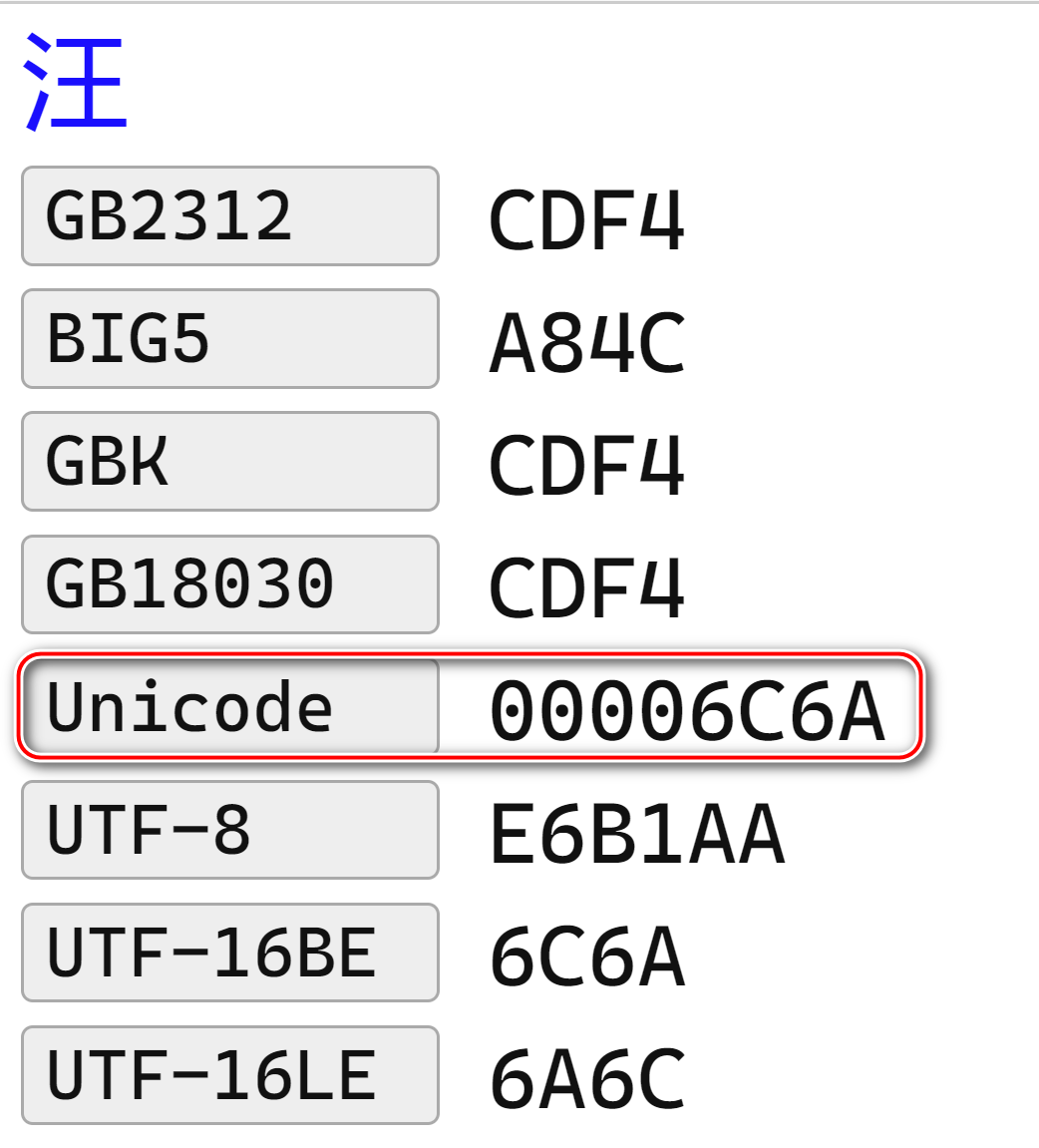
6C6A 的二进制表示为 0110 1100 0110 1010,需要两个字节进行存储。表示其他的符号,可能需要三个甚至四个字节存储。

另一方面,对于原本就存在于 ASCII 编码表中的英文字符,仅需 1 个字节就能存储。如果 Unicode 强制要求每个字符按照最大需要的存储空间,即 4 字节进行存储,显然对于英文字符来说,意味着极大的空间浪费。
因此,Unicode 仅仅定义字符到其编码的映射关系。而这些编码到底采取多少个字节进行存储,由 Unicode 具体的实现方式,比如 UTF-8,UTF16 等来决定。
UTF-8 是一种变长的编码方式,使用 1 到 4 个字节表示一个字符,符号不同,用于存储的字节长度也不同。比如 “汪” 的 UTF-8 码值为 E6B1AA,需要三个字节存储。
根据 SAP 帮助文档,ABAP 采用 UCS-2 编码方式,可以看成 UTF-16 的子集,因为 UCS-2 不支持 UTF-16 的 surrogates 区间内定义的一些特殊符号。

所谓 UTF-16,就是所有字符固定都用两个字节表示。
从下面这张表格能够看出,UTF-16 又分 UTF-16BE 和 UTF-16LE 两种实现方式。以汉字 “汪” 的 Unicode 编码值 6C6A 为例,如果 6C 存储在内存低位地址,6A 存储在内存高位地址,这就是 Big Endian 即大尾序(有时也译作大头,大端)存储方式,反之则为 Little Endian 即小尾序存储方式。
这两个名称来自英国讽刺寓言作家斯威夫特的《格列佛游记》。书中的小人国爆发了内战,战争起因竟然是人们争论吃鸡蛋时究竟应该从大头(Big Endian)一端敲开,还是从小头(Little Endian)敲开。
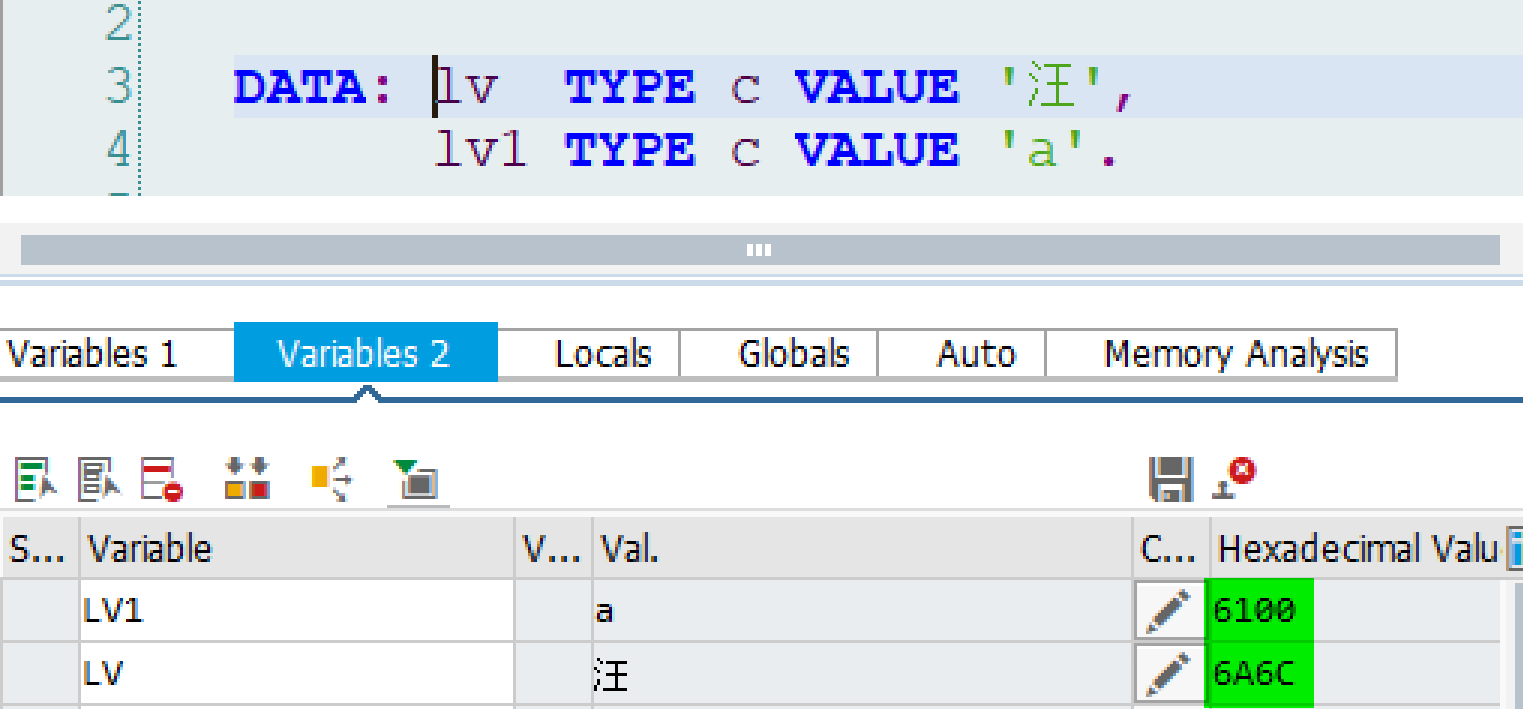
那么 ABAP 的 UCS-2(UTF-16 的子集), 到底是 BE 存储还是 LE 存储?一试便知。
在我的系统里,答案是 UTF-16LE.

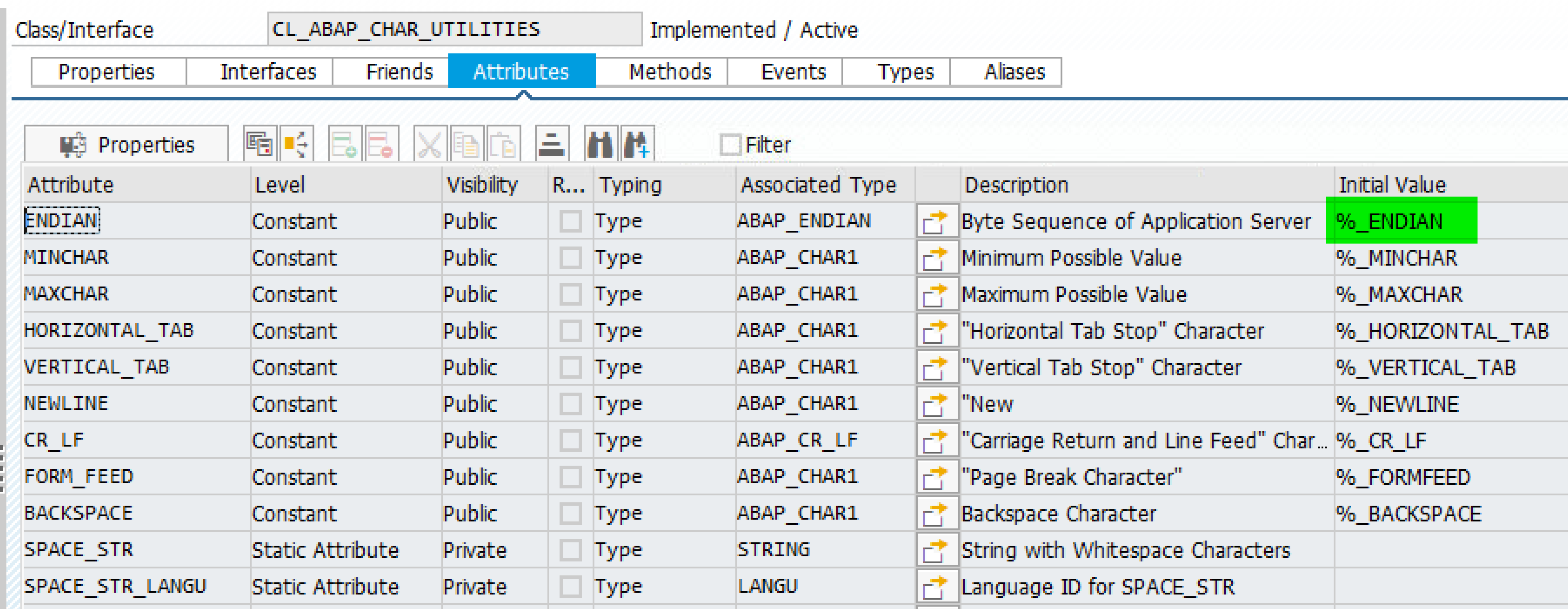
另一种方式,直接检查系统类 CL_ABAP_CHAR_UTILITIES 的属性 ENDIAN. 在 Jerry 的系统里,该属性的值为 L,代表 Little Endian:
我们了解了这些知识,再来修复文章开头描述的乱码问题。
仔细观察 Postman 调用 API 的返回结果,发现还有一条重要信息:charset=GB18030,意思是 API 响应数据采取 GB18030 字符集编码。
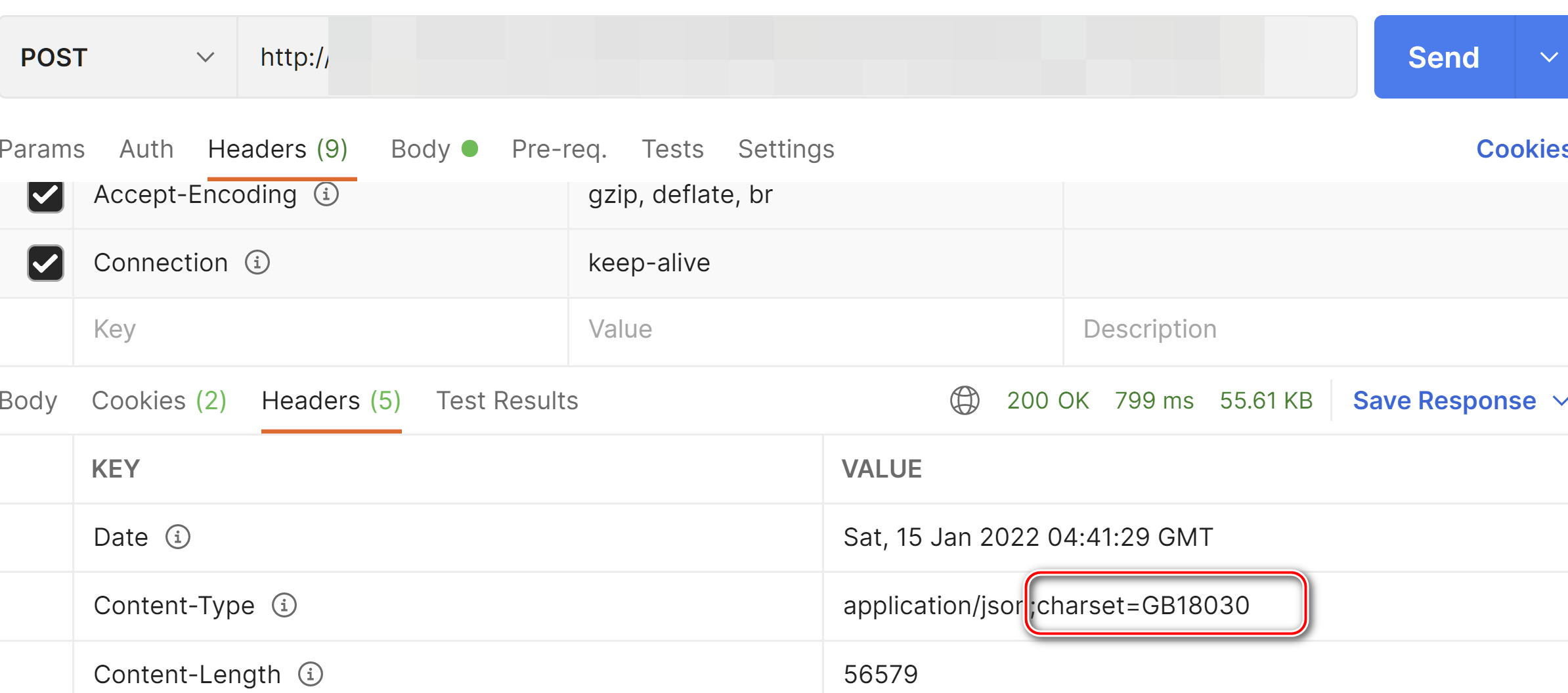
汉字 “访” 的 GB18030 编码值为 B7C3,完全不等同于 UTF-16LE 中的编码值 BF8B.

如果我们在 ABAP 代码里,按照默认的 UTF-16LE 的方式去读取一个根据 GB18030 编码的符号,当然不会得到期望的结果。这种张冠李戴的解码方式见下图第 55 行的 get_cdata 方法,最后就会出现乱码。

正确的方式,采取第 57 行 get_data,返回一个 16 进制数据流,类型为 xstring:
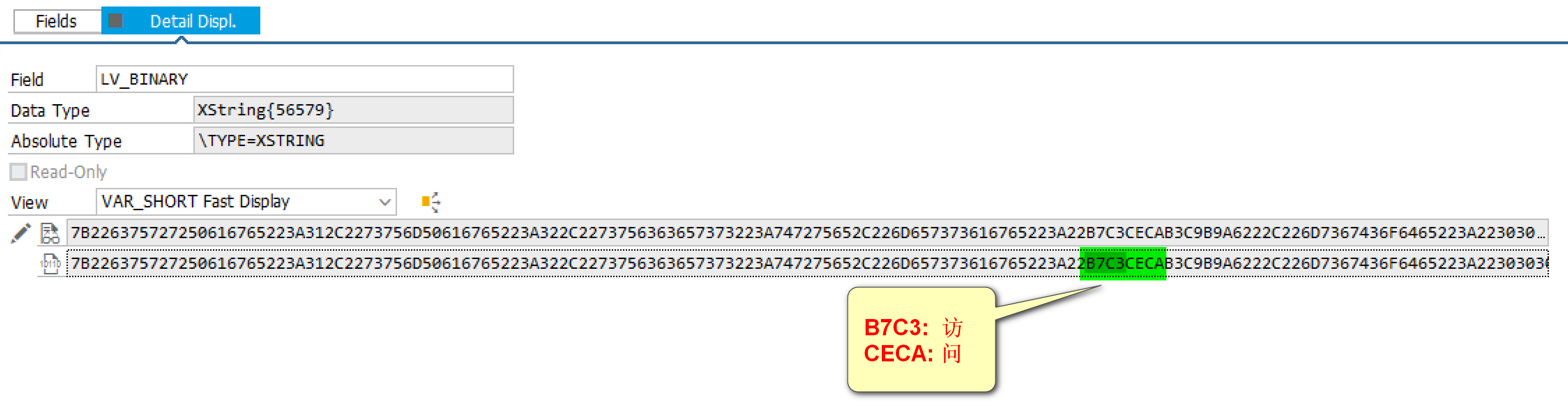
在这个16 进制数据流里,我们已经看到了汉字 “访” 和 “问” 对应的 GB18030 编码值。
剩下的事情就容易了,使用字符集 GB18030 对这段数据流进行解码。
我们首先打开数据库表 TCP00, 根据关键词 18030 查询表字段 CPCOMMENT:
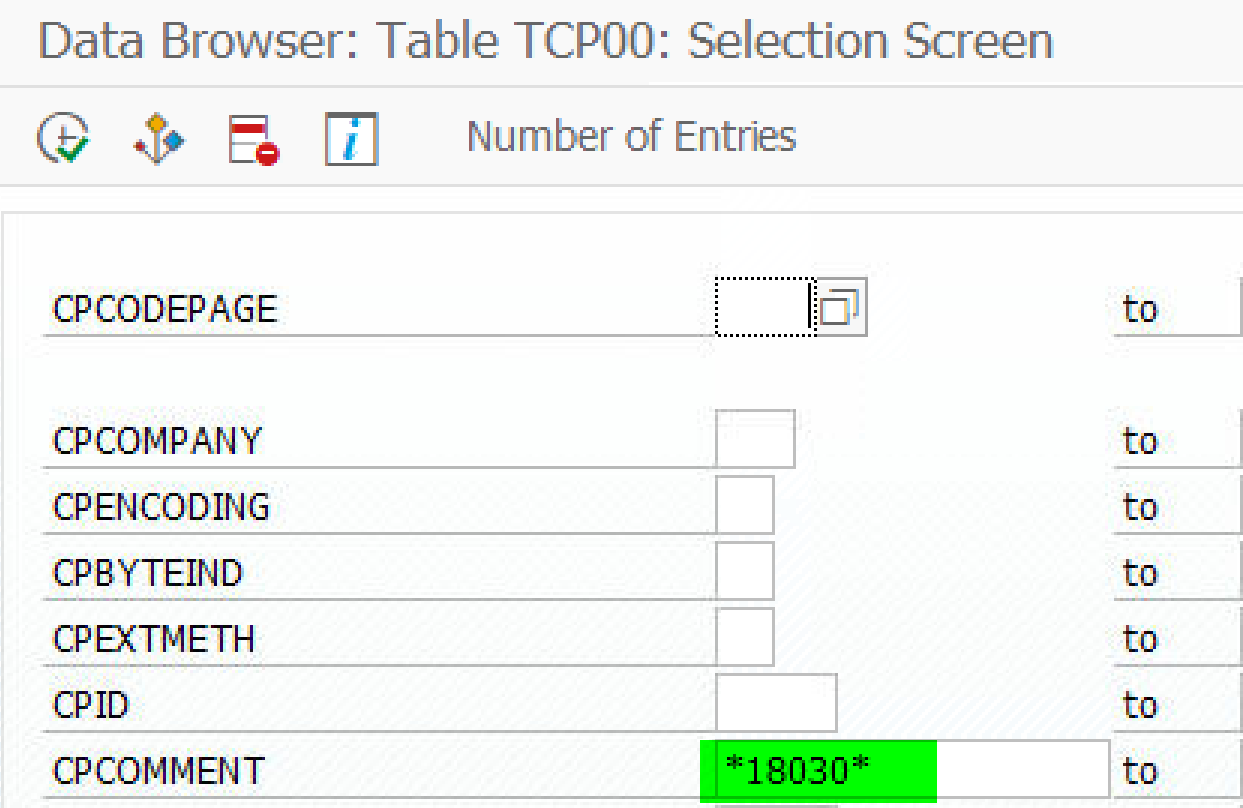
得到 GB18030 对应的 SAP Code Page 为 8401:

在下面这段代码中,传入 8401,变量 lv_binary 存储的是 16 进制数据流,变量 lv_text 存放的就是基于 GB18030 的 API 响应内容:

可以看到乱码已经消失了,在 ABAP 程序里显示的内容已经和 Postman 里观察到的完全一致了。

希望本文介绍的这个例子,能对大家在 ABAP 里处理中文乱码问题有所启发,感谢阅读。

- 点赞
- 收藏
- 关注作者
评论(0)