通过在操作系统中实际操作,学习和理解 Unicode 编码相关知识

我们通过在操作系统里进行一些简单的联系,可以加深对 Unicode 编码这些基础知识的理解和记忆。
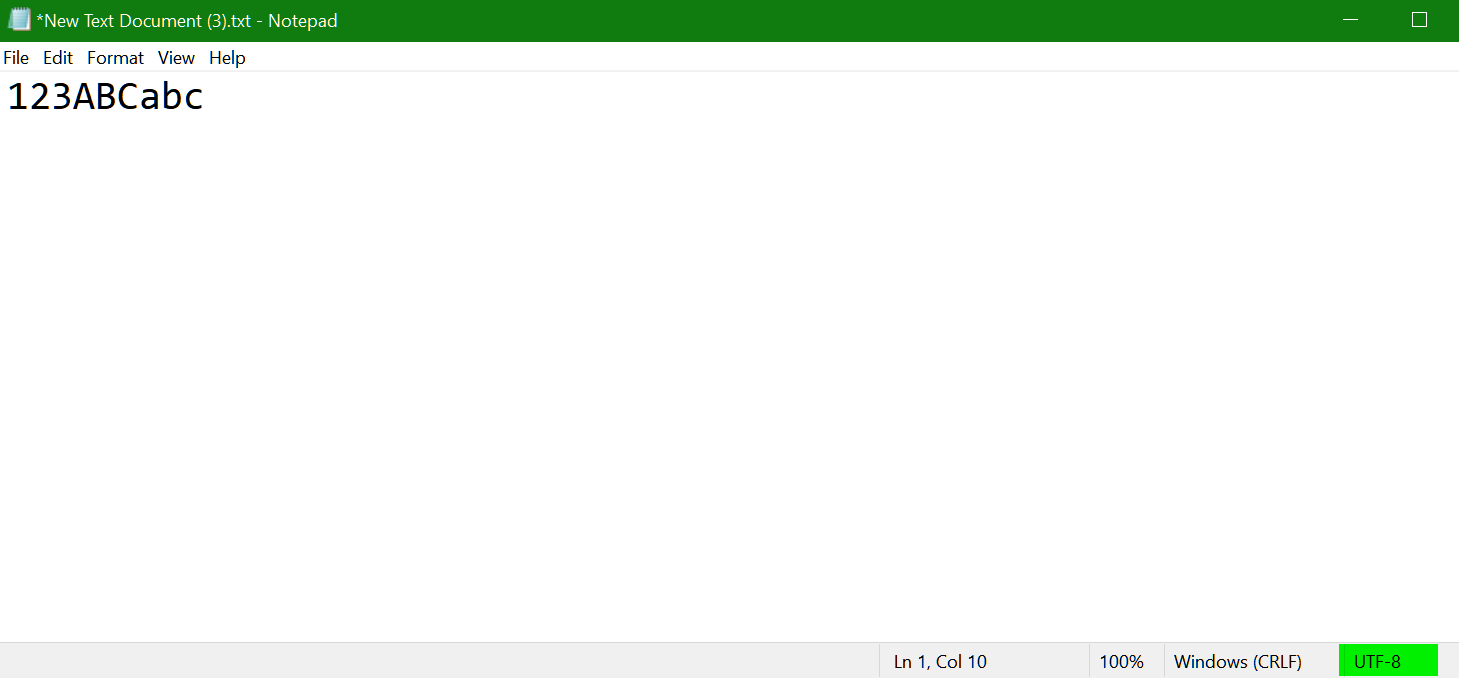
Windows10 操作系统下,新建一个记事本文件,输入 123ABCabc
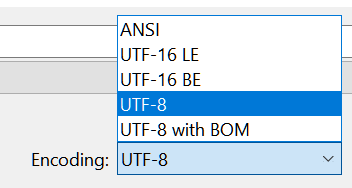
默认的 encoding 格式为 UTF8:
使用 winhex 这款 16进制文件编辑器打开该记事本文件:

看到正文区域的 31 32 33 41 42 43 61 62 63。这些数字代表什么含义?
UTF8 (Universal Character Set/Unicode Transformation Format) 是针对 Unicode 的一种可变长度字符编码。它可以用来表示 Unicode 标准中的任何字符,而且其编码中的第一个字节仍与 ASCII 相容,使得原来处理 ASCII 字符的软件无须或只进行少部分修改后,便可继续使用。
ASCII 是美国标准信息交换代码(American Standard Code for Information Interchange)的缩写, 为美国英语通信所设计。它由 128 个字符组成,包括大小写字母、数字0-9、标点符号、非打印字符(换行符、制表符等4个)以及控制字符(退格、响铃等)组成。
ascii 对照表可以从这个链接获得。
其中数字 1,2,3 的 UTF8(ASCII) 编码分别为 31,32和33:
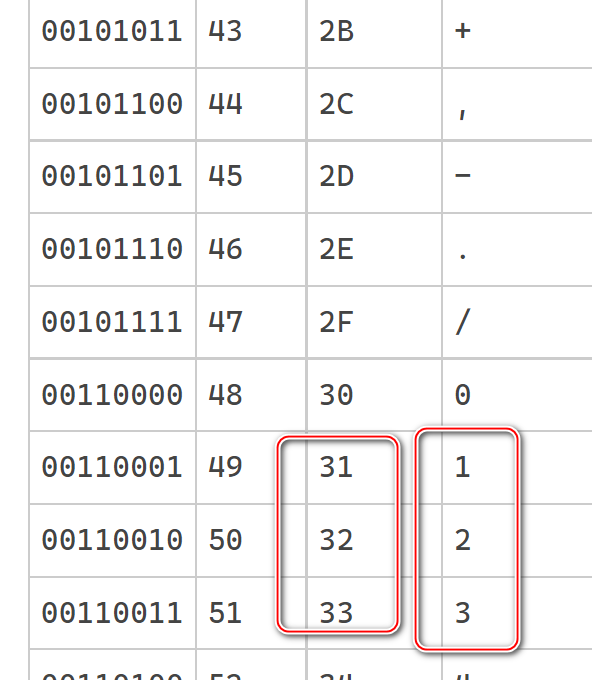
大写的 A B C 的 UTF8(ANSI) 编码为 41 42 43,小写字母为 61 62 63:

ENCODING 改成 ANSI:

winhex 中的内容不变。
记事本的 Encoding 改成 UTF8 with bom 之后:
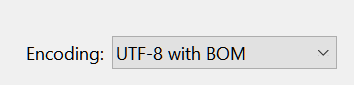
winhex 文件内容的前部,多了三个EF BB BF

首先,BOM 的含义是 byte order mark,BOM(byte order mark)是为 UTF-16 和 UTF-32 准备的,用于标记字节序(byte order)。微软在 UTF-8 中使用 BOM 是因为这样可以把 UTF-8 和 ASCII 等编码明确区分开。
可以把这个 EF BB BF 理解成一种特殊的标记符,用于显式表明该文件的编码为 UTF-8:
https://en.wikipedia.org/wiki/Byte_order_mark#Byte_order_marks_by_encoding
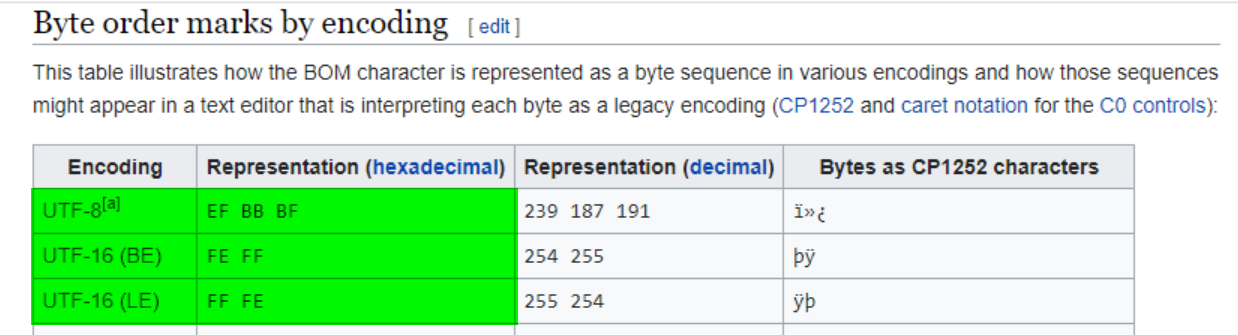
相应的,在记事本里将 encoding 改成 UTF-16(BE) 之后,文件头就变成了 FE FF,并且以前的 31 32 33 变成了双字节 00 31 00 32 00 33:

下面再试试中文。
在记事本里输入一个中文“汪”:
汪 UTF8

E6 B1 AA 这是汉字 汪 的三字节 Unicode 编码,来自网站。
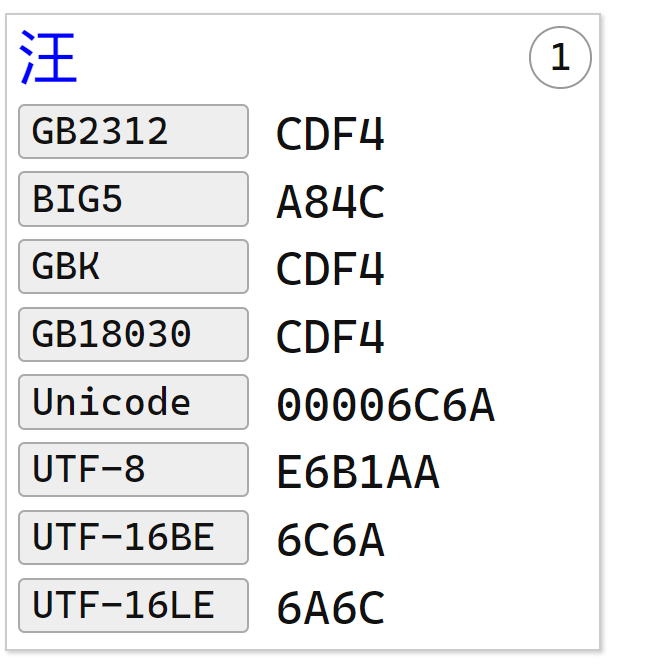
AA 占一个字节,8位:1010 1010

UTF16-LE 6A6C

3A 代表冒号:

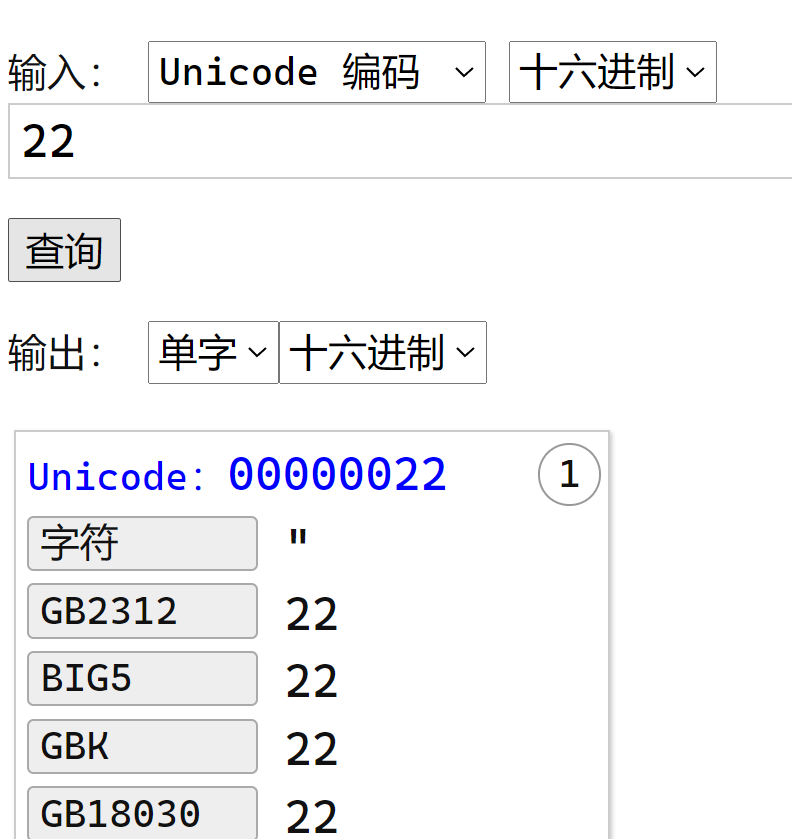
22 代表引号:

- 点赞
- 收藏
- 关注作者
评论(0)