极限熵和冗余度
信息冗余度(多余度、剩余度)
在信息论中,信息冗余是传输消息所用数据位的数目与消息中所包含的实际信息的数据位的数目的差值。数据压缩是一种用来消除不需要的冗余的方法,校验和是在经过有限信道容量的噪声信道中通信,为了进行错误校正而增加冗余的方法。信息冗余度一译"信息剩余度"。是指一定数量的信号单元可能有的最大信息量与其包含的实际信息量之差。通常用R表示。为信号的实际信息量,Imax为同样数量的信号单元可能有的最大信息量。会使传信绩效降低,但能提高通讯的抗干扰能力。
-
表示信源在实际发出消息时所包含的多余信息。
-
冗余度:
-
信源符号间的相关性。
-
信源符号分布的不均匀性。
-
log2N=H0(X)≥H1(X)≥H2(X)≥⋯≥H∞(X)
N=H0(X):等概率分布时信源熵
N=H1(X):相互独立
N=H1(X):两者有关系
对于有记忆信源, 极限熵为
H∞(X)=limN→∞H(XN/X1⋯XN−1)=limN→∞N1H(X1⋯XN)
这就是说需要传送某一信源的信息, 理论上只需要传送
H∞(X) 即可。但这必须掌握信源全部概率统计特性, 这显然是不现实的。实际上,只能算出
Hm(X) 。那么与理论极限值相比,就要多传送
Hm(X)−H∞(X)
为了定量地描述信源的有效性, 定义: 信息效率
η=Hm(X)H∞(X)
冗余度
γ=1−η=1−Hm(X)H∞(X)
冗余度
由于信源存在冗余度,即存在一些不必要传送的信息,因此信源也就存在进一步压缩其信息率的可能性。
信源冗余度越大,其进一步压缩的潜力越大。这是信源编码与数据压缩的前提与理论基础。
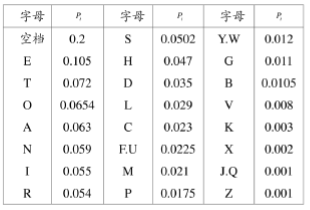
例:英文字母:
英文字母出现的概率如下表(含空格)
英文字母出现概率

若各个字母独立等概, 则信息熵
H0=log227=4.76bit/sym
按照表计算独立不等概的信息熵
H1=−∑i=127pilogpi=4.03bit/sym
若只考虑一维相关性, 有
H2=3.32bit/sym , 进一步考虑二维相关性
, 有
H3=3.01bit/sym …
香农推断:
H∞≅1.4bit/sym
- 从而:
η=29%,γ=71%
总结
信源模型:记忆离散无记忆信源的数学模型。
自信息:会计算。
信息熵、联合熵、条件熵:会计算,能够分析并计算离散信源的信息速率。
列举信息熵、联合熵、条件熵直接的关系。
【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com



评论(0)