聊聊Redis的数据热点问题

前两天,我们使用的某云厂商服务挂了,而且一挂就是挂大半天,我们的服务强依赖于他们,所以我们也跟着一起挂。然而我们却无能为力,只能等他们恢复。事故原因中听他们提到Redis有个热key,正好我在上家公司负责过部门Redis集群,也处理过很多起Redis数据热点的问题,接下来就一起聊聊什么是Redis热点?Redis热点问题为什么会极大地影响整个集群的性能?如何避免Redis数据热点?热点问题如何排查?热点问题如何解决?
什么是Redis热点?
我曾在我过往的博文中多次提到了局部性一词(关于局部性可以看下我之前的博文 局部性原理),数据热点就是数据访问局部性的体现,具体表现就是Redis中某个Key的访问频次远大于其他剩余的Key,我们也有一句俗语来形容这种现象旱的旱死,涝的涝死。
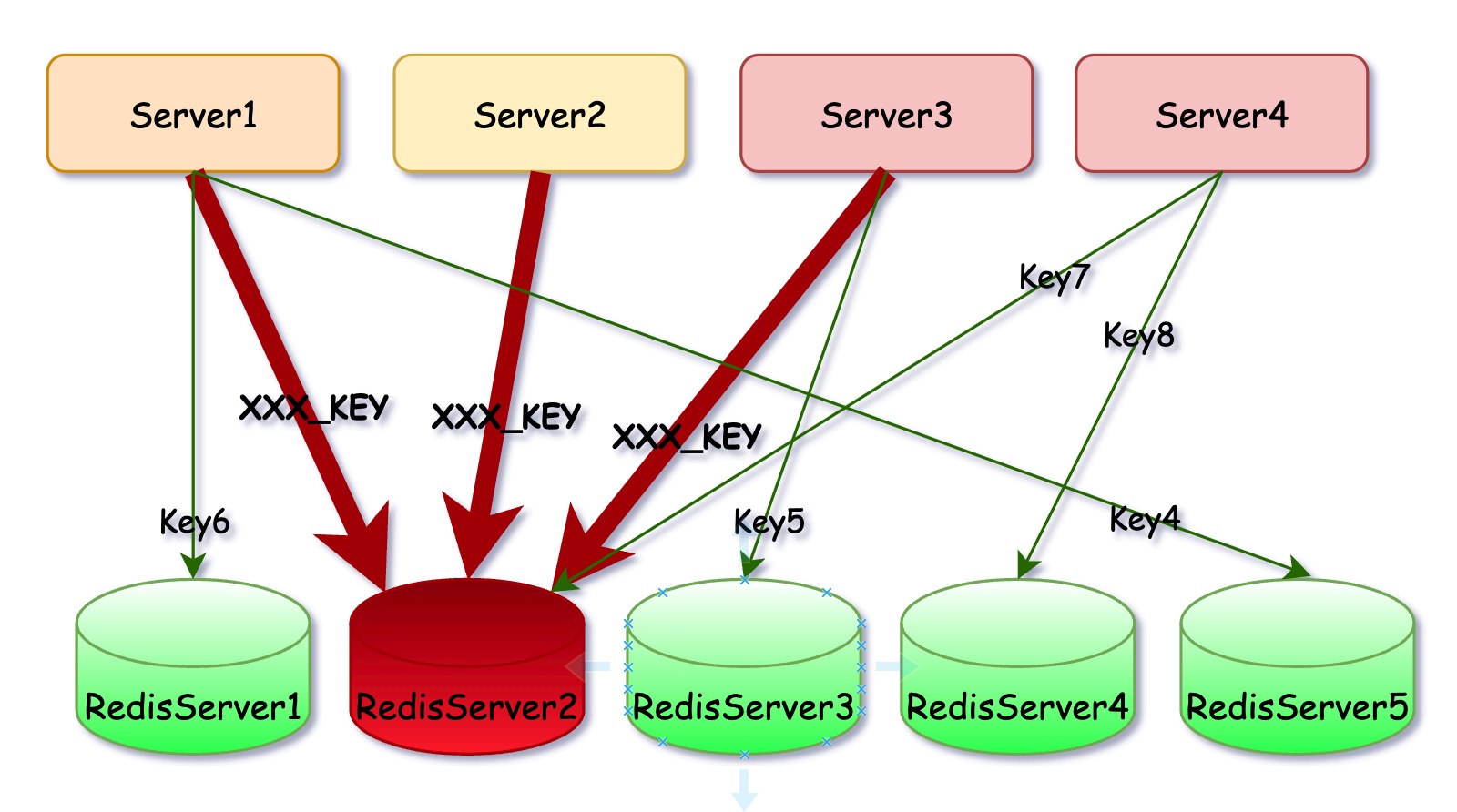
为什么Redis会有热点问题?这就得从Redis的原理说起了。众所周知,Redis中存储的是K-V数据,在集群模式下,Redis会将所有数据按Key的CRC64值分配到16384个数据槽(slot)中,并将这16384个数据槽分配到集群中各个机器上,尽可能实现数据在各个机器上的均匀存储。但均匀存储并不意味着均匀访问,有时候某个Key的请求会占到总请求的很大一部分,这就会导致请求集中在某个Redis实例上,将该Redis实例的承载能力耗尽,所有存储在这个实例上的其他数据也就无法正常访问了,这就意味着所有依赖于这些数据的服务都会出问题。
这里的出问题并不是说Redis会直接宕机,众所周知Redis的核心流程是单线程模式,这就意味着Redis是串行处理所有请求的,当请求过多时,请求就会拥堵起来,从应用层的视角来看,就是请求Redis的耗时会特别特别高。因为应用层使用Redis都是作为缓存,都是同步请求,所以会间接导致应用层的请求处理也会特别耗时,从而导致应用层请求也逐渐拥堵,最终整体不可用。
我们来举个简单的例子,相信大家都在微博上吃过瓜,当有大瓜出现时,微博上会迅速涌入一批用户检索相关信息,疯狂访问同一份微博(数据),这种情况下这份数据就是热点数据,如果数据太“热”最终会导致微博挂掉,实际上微博挂掉的情况已经出现很多次了,不是因为微博技术不行,而是因为热点问题太可怕。
Redis热点是如何拖垮其他服务的?
Redis的热点并不仅仅会导致单个服务异常,而是会导致所有依赖于此Redis集群的所有服务异常。上图中Server2、Server、Server3频繁访问XXX_KEY,导致RedisServer2实例不可用,因为Server4依赖于RedisServer2上的Key7,即便是RedisServer1 3 4 5 都正常服务,Server4也无法对外提供正常的服务。
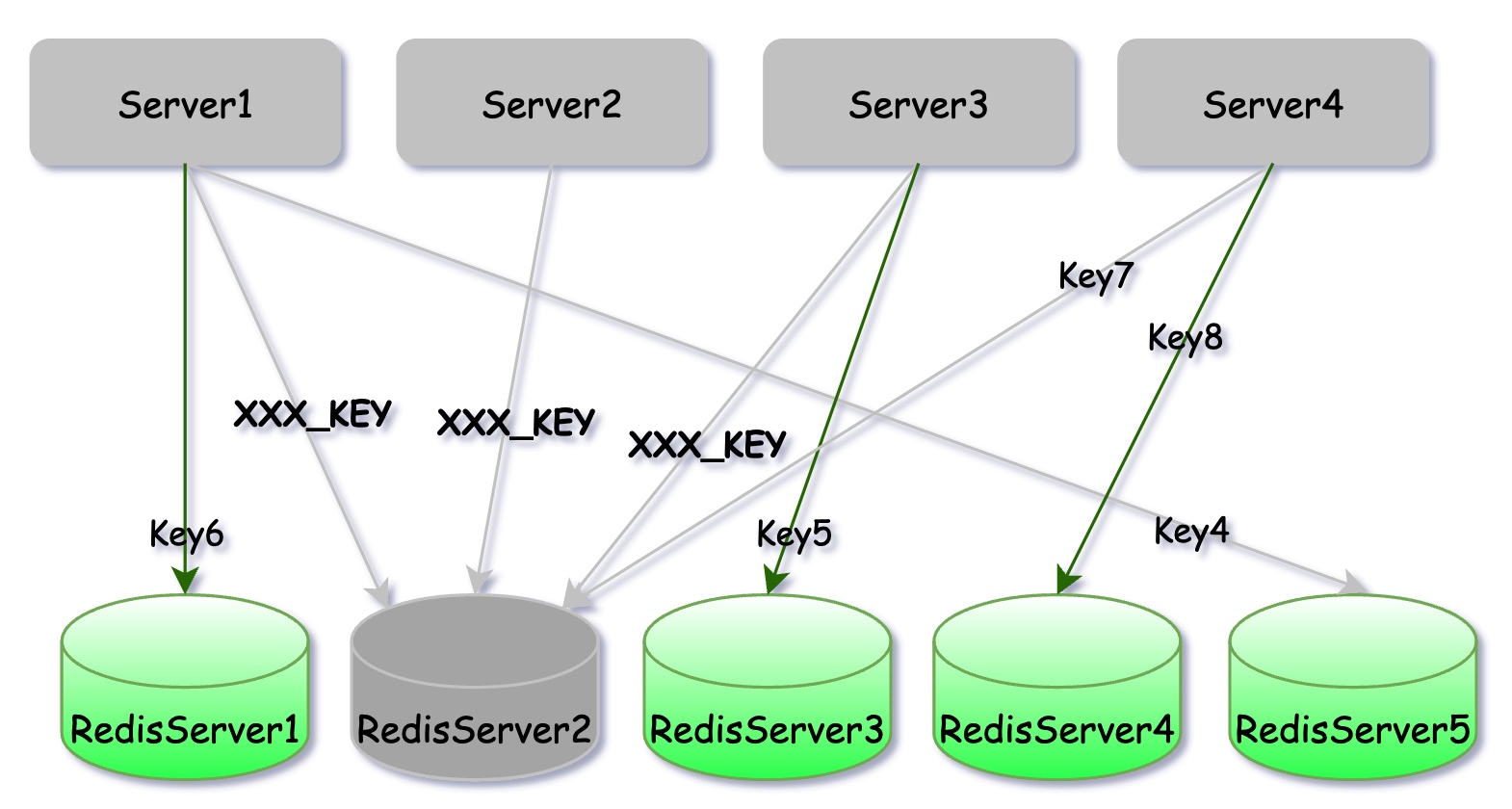
是不是有人会问RedisServer2挂了,不能把它下掉,换一个新的机器上去吗? 其实在Redis集群模式下,某个实例宕机Redis集群会自动将其替换。但现在的情况是,即便是替换了新实例,大量的请求也会一下子涌进来将其压挂。所以面对Redis热点问题,重启之类的手段是无效的,只能从请求端解决问题。
其实这就是一个很明显的 木桶模型, 一个木桶所能装水的多少取决于木桶上最短的那块木板,当应用使用Redis集群时,Redis集群的性能上限并不完全等于单实例上限乘以实例个数。 但当Redis集群中任一实例有问题,上层感知到的就是整个Redis集群有问题。
Redis热点如何避免?
上文也说到,热点问题其实是局部性问题,而局部性问题的避免其实非常难,任何分布式系统几乎都会受局部性的影响。面对这种问题,说实话没有绝对可以避免的方式,只能提前通过分析数据的特性,做好相应的措施。说白了就是靠经验,不知道大家有啥其他好的思路,可以在评论区探讨下。
热点问题如何排查?
Redis的热点的问题其实算是很好查的,就是靠监控数据,监控Redis各个实例的CPU使用率、QPS 数据,如果你看到redis集群中某些实例负载和QPS特别高,但其他实例负载很低,不用问肯定是出现热点问题了,接下来你需要做的就是找出具体的热点key,并且找出数据访问的来源。
找出热点Key其实也很简单,抓部分访问日志,然后统计下很容易就看出来了。但比较难的是找出数据访问的来源,像我之前所在的公司,同一个Redis集群是被很多业务所共享的,但Redis的访问并为被纳入到全链路监控的数据中,所以找出访问来源最直接的方式就是在群里面问,听起挺原始的,但也没有其他方法。
热点问题如何解决?
虽然解决问题最好的方式是避免问题的发生,但我刚才也说了,Redis热点其实很难避免,任何业务中热点一定有,但不一定会造成灾难而已。 热点的发现不一定非得是事故引出的,我们也可以在日常工作中定期巡检,一有发现热点的苗头,直接将其扼杀。
对于发现热点后如何解决,我这里提供两个我的解决思路,大家可以探讨下:
应用层Cache
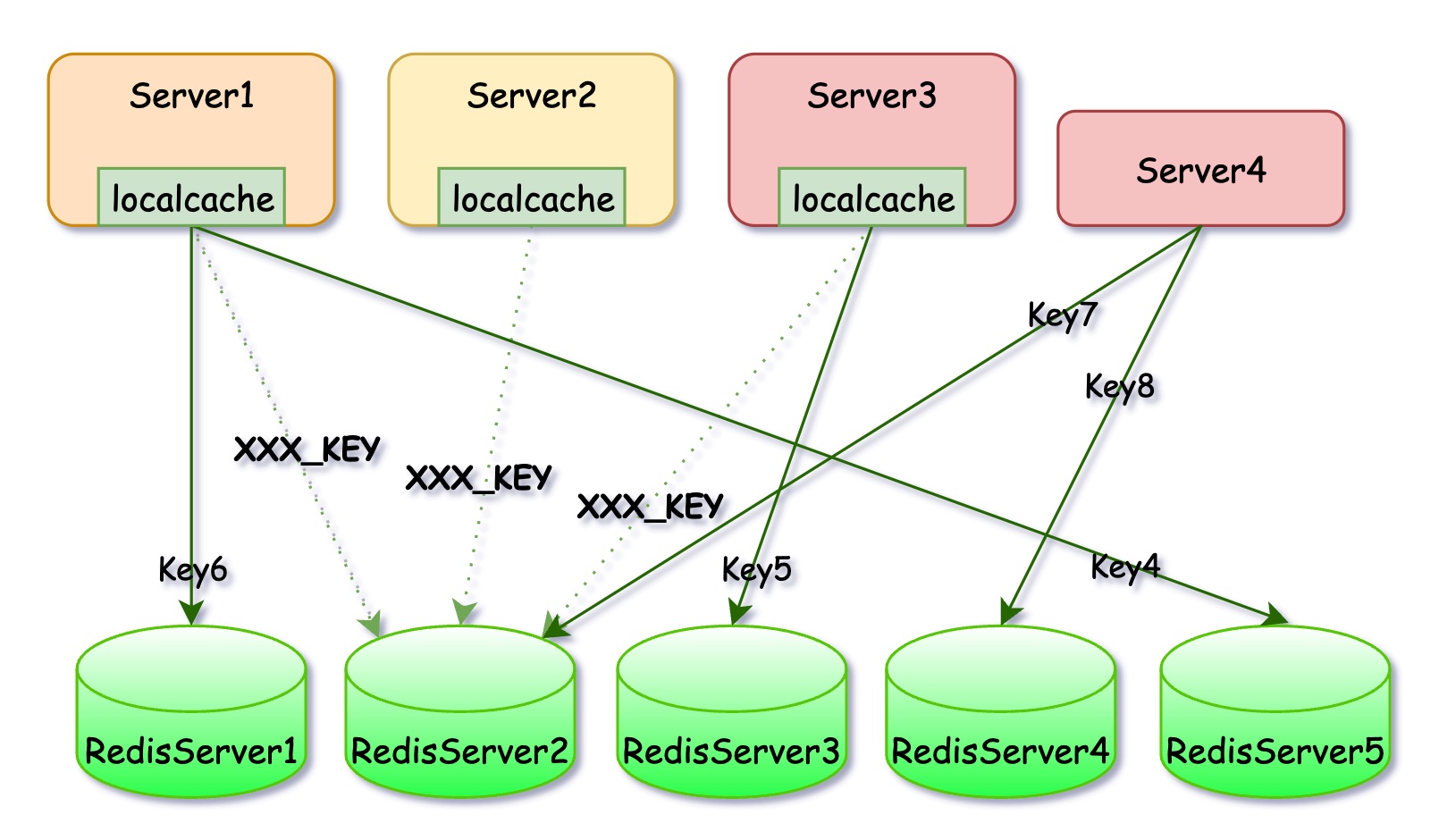
常用的实现方式就是在应用里实现本地缓存(LocalCache),就相当于是对Redis数据又加了一层Cache,对于那些非常热的热点数据,应用层有极大的概率能在本地缓存中找到数据,只有极小部分LocalCache数据过期时的请求会漏到下面,这样热点数据的请求在应用层内部就能消化,从而极大减少对Redis的压力。
这种实现方法的话,仅需要数据读取端做改造,数据写入端完全不需要改造。然而缺点的话也很明显:
- 需要各端自行实现,会增加应用层开发和维护成本。
- 会额外浪费各端的存储空间。
- 需要针对性开发,不适合大范围推广。
增加数据副本
既然热点问题是因为某个Key被大量访问导致的,那我们将这个Key的请求做下拆分不就行了。例如,原始的热点Key叫做XXX_KEY,我们在数据写入的时候,可以用不同的Key重复写10份,比如 XXX_KEY_01, XXX_KEY_02……XXX_KEY_10, 访问的时候在原始Key上随机凭接一个1-10之间的后缀即可,这样就能实现数据请求的分散,如果想让请求更分散,可以存储更多的副本。
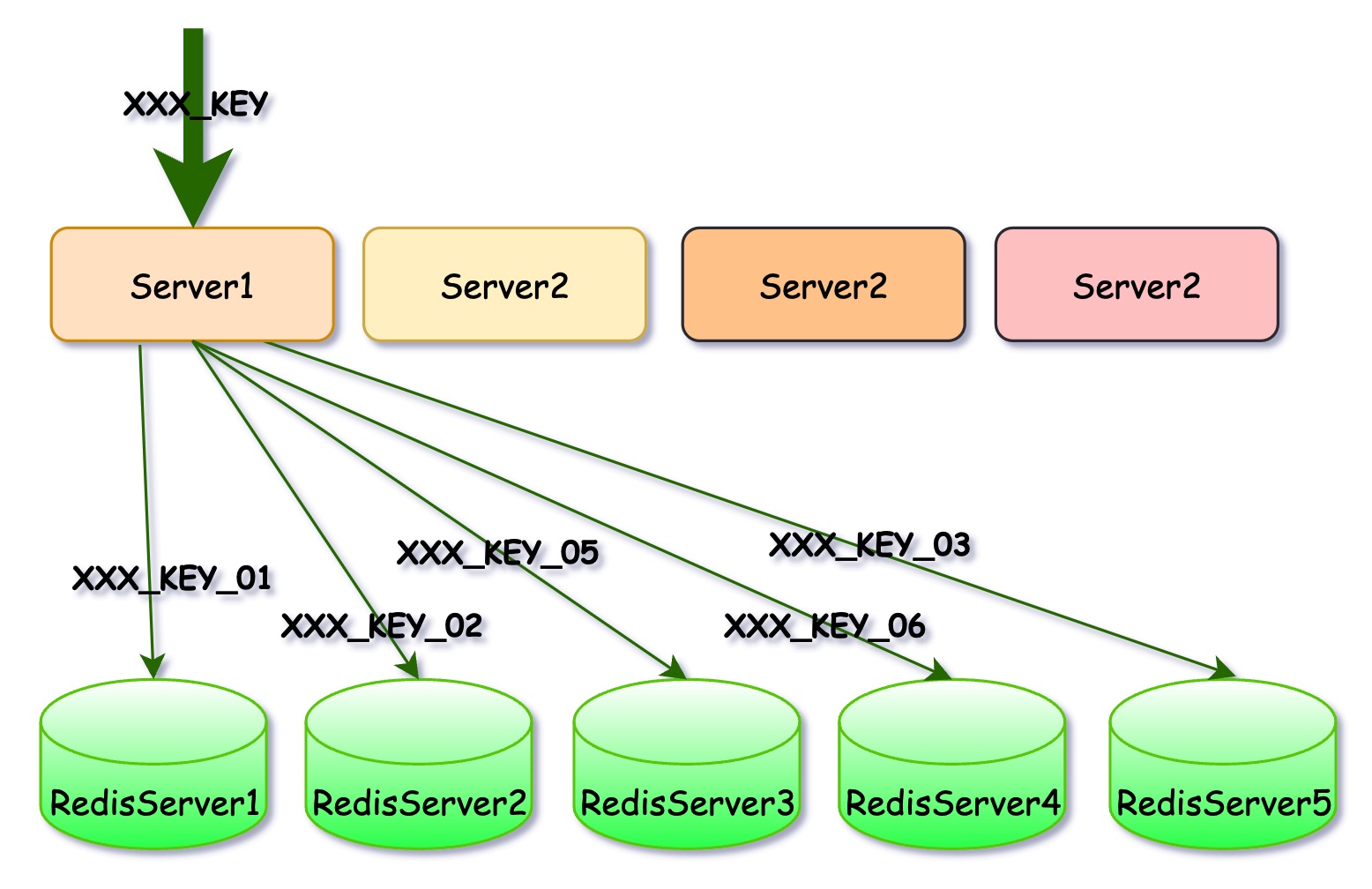
这种方案的优点就是数据读取端实现成本较低(也不是完全没有),但对数据写入端的要求就高多了。不仅要写入多份,而且还得考虑数据写入后一致性的问题。这种方法要求两端都得改,貌似更麻烦了,你是不是觉得还不如第一种方案?实则不然,一般来说读取端会很多且很分散,改造的成本会非常高,频繁变动更是不太可能,所以有些工作不得不放置到比较集中的端上。
以上两种方案其实都是通过存储来换性能,主要差异点就在于由谁来做而已。前者是客户端来做,后者是服务端来做,各有优缺点。 有没有可能对外提供纯粹的Redis协议,但可以解决数据热点的问题?。鲁迅……David Wheeler曾经说过,计算机科学的如何问题都可以通过增加一层来解决,热点的问题也不例外。我们可以在应用和Redis之间加一层中间层,这层中间层可以是真实的服务,比如数据统一访问层。也可以是特制的Redis客户端。
中间层可以对特定的Key加本地Cache,就可以保证热点不会出现在Redis上。至于对哪些Key加本地Cache,中间层可以实时去分析近期请求热点数据,自行决定。其实最简单的方式就是开个LRU或者LFU的Cache。
另外,像第二种增加数据副本的方案,也完全可以由中间层去实现。当我们发现有数据热点时,让中间层主动将热点数据复制,拦截并改写所有对热点数据的请求,将其分散开来。 当然,如果中间层更智能的化,这些完全都可以实现自动化,从热点的发现到解决,完全不需要人参与。
今天的文章就到这了,大家觉得有用请点赞,喜欢请关注。关于Redis热点的问题,大家有啥看法或者经验可以在评论区留言讨论。
文章来源: xindoo.blog.csdn.net,作者:xindoo,版权归原作者所有,如需转载,请联系作者。
原文链接:xindoo.blog.csdn.net/article/details/126802164

- 点赞
- 收藏
- 关注作者
评论(0)