mindspore两日集训营202209-金箍棒应用

pip install https://ms-release.obs.cn-north-4.myhuaweicloud.com/1.8.0/GoldenStick/any/mindspore_gs-0.1.0-py3-none-any.whl --trusted-host ms-release.obs.cn-north-4.myhuaweicloud.com -i https://pypi.tuna.tsinghua.edu.cn/simple
- 1
- 2
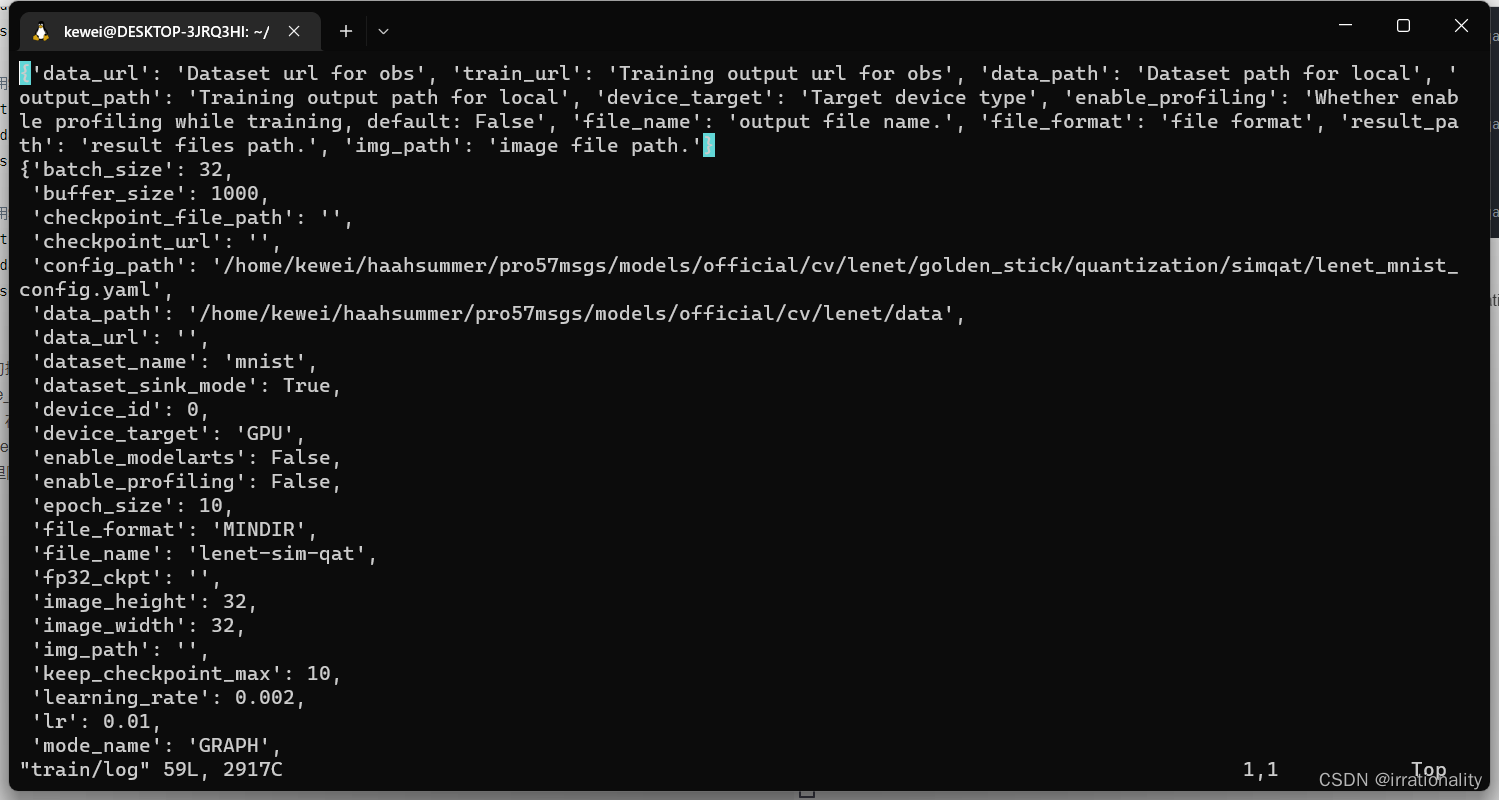
cd ./golden_stick/scripts/
bash run_standalone_train_gpu.sh ../quantization/simqat/ ../quantization/simqat/lenet_mnist_config.yaml ../../data/
- 1
- 2
出现了这样一句报错
run_standalone_train_gpu.sh: line 76: ulimit: max user processes: cannot modify limit: Operation not permitted
正确的做法是,在root下执行命令,
ulimit -u unlimited
然后把sh文件里同样的这句话注释掉
然后就跑起来了,很快的
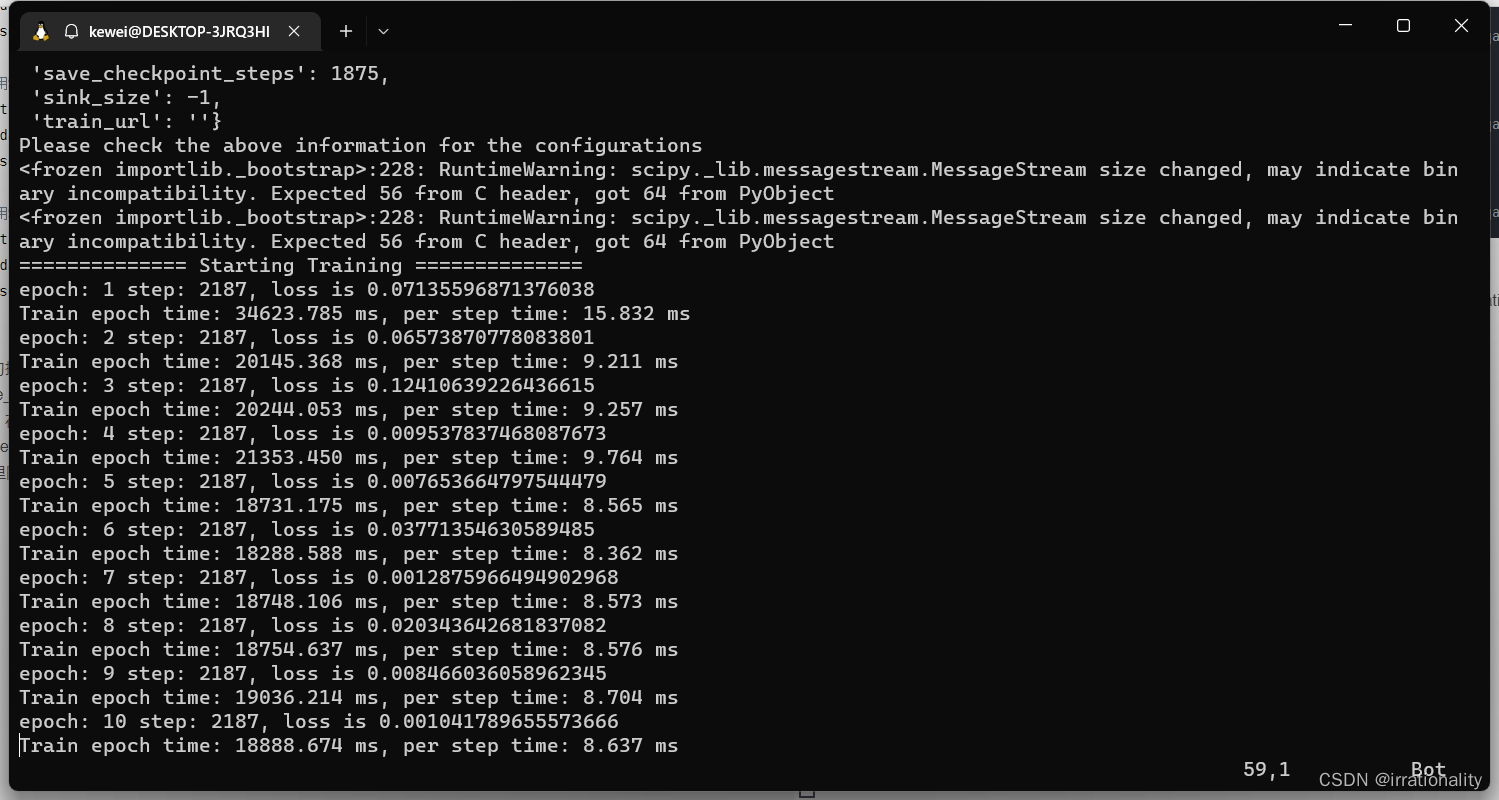
获得的ckpt比一般的要小
打印网络结构非常简单,直接print(network)
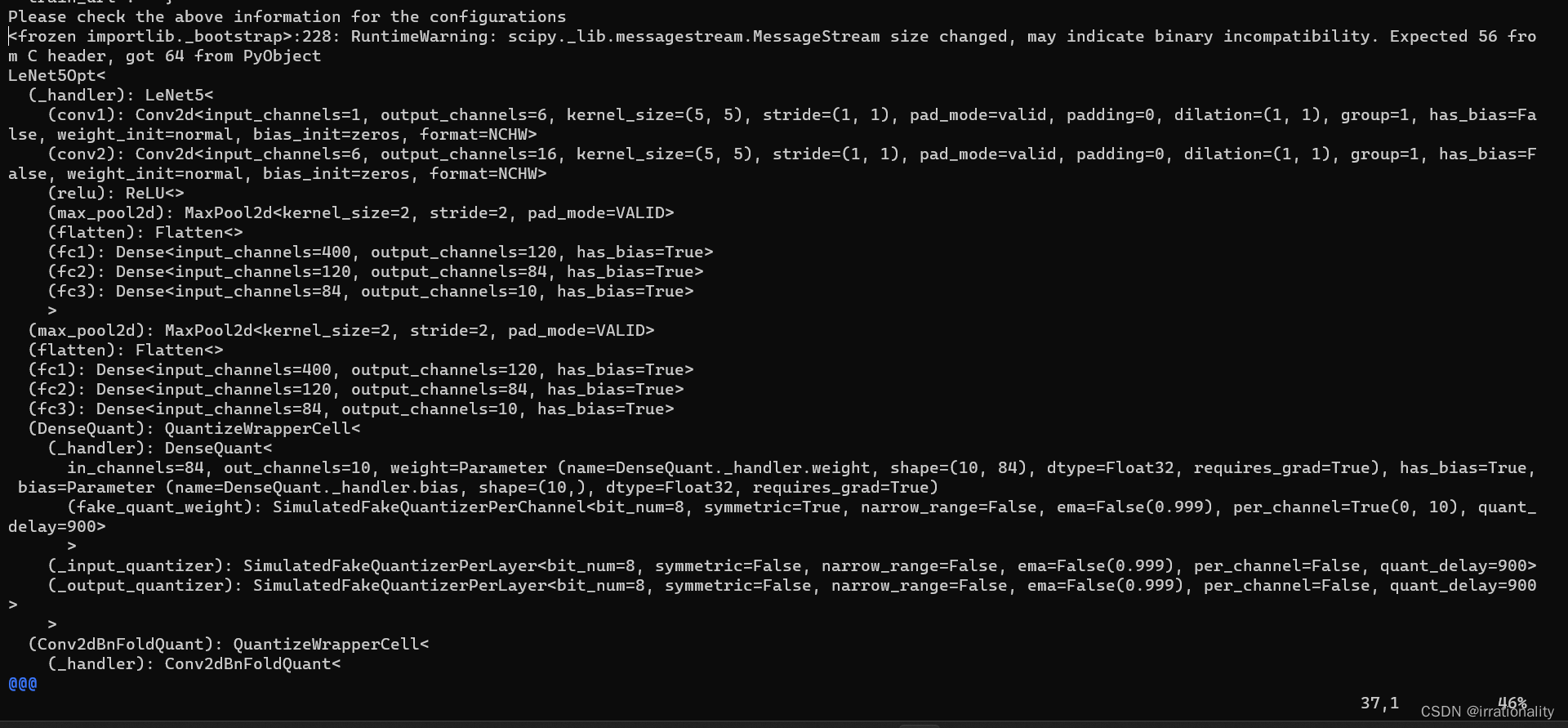
LeNet5Opt<
(_handler): LeNet5<
(conv1): Conv2d<input_channels=1, output_channels=6, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False, weight_init=normal, bias_init=zeros, format=NCHW>
(conv2): Conv2d<input_channels=6, output_channels=16, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, has_bias=False, weight_init=normal, bias_init=zeros, format=NCHW>
(relu): ReLU<>
(max_pool2d): MaxPool2d<kernel_size=2, stride=2, pad_mode=VALID>
(flatten): Flatten<>
(fc1): Dense<input_channels=400, output_channels=120, has_bias=True>
(fc2): Dense<input_channels=120, output_channels=84, has_bias=True>
(fc3): Dense<input_channels=84, output_channels=10, has_bias=True>
>
(max_pool2d): MaxPool2d<kernel_size=2, stride=2, pad_mode=VALID>
(flatten): Flatten<>
(fc1): Dense<input_channels=400, output_channels=120, has_bias=True>
(fc2): Dense<input_channels=120, output_channels=84, has_bias=True>
(fc3): Dense<input_channels=84, output_channels=10, has_bias=True>
(DenseQuant): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=84, out_channels=10, weight=Parameter (name=DenseQuant._handler.weight, shape=(10, 84), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant._handler.bias, shape=(10,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 10), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dBnFoldQuant): QuantizeWrapperCell<
(_handler): Conv2dBnFoldQuant<
in_channels=1, out_channels=6, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, fake=True, freeze_bn=10000000, momentum=0.997
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 6), quant_delay=900>
(batchnorm_fold): BatchNormFoldCell<>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dBnFoldQuant_1): QuantizeWrapperCell<
(_handler): Conv2dBnFoldQuant<
in_channels=6, out_channels=16, kernel_size=(5, 5), stride=(1, 1), pad_mode=valid, padding=0, dilation=(1, 1), group=1, fake=True, freeze_bn=10000000, momentum=0.997
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 16), quant_delay=900>
(batchnorm_fold): BatchNormFoldCell<>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(DenseQuant_1): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=400, out_channels=120, weight=Parameter (name=DenseQuant_1._handler.weight, shape=(120, 400), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_1._handler.bias, shape=(120,), dtype=Float32, requires_grad=True), activation=ReLU<>
(activation): ReLU<>
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 120), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(DenseQuant_2): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=120, out_channels=84, weight=Parameter (name=DenseQuant_2._handler.weight, shape=(84, 120), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_2._handler.bias, shape=(84,), dtype=Float32, requires_grad=True), activation=ReLU<>
(activation): ReLU<>
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 84), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
这样就可以了。
然后评估
bash run_eval_gpu.sh ../quantization/simqat/ ../quantization/simqat/lenet_mnist_config.yaml ../../data/ ./train/ckpt/checkpoint_lenet-10_2187.ckpt
- 1
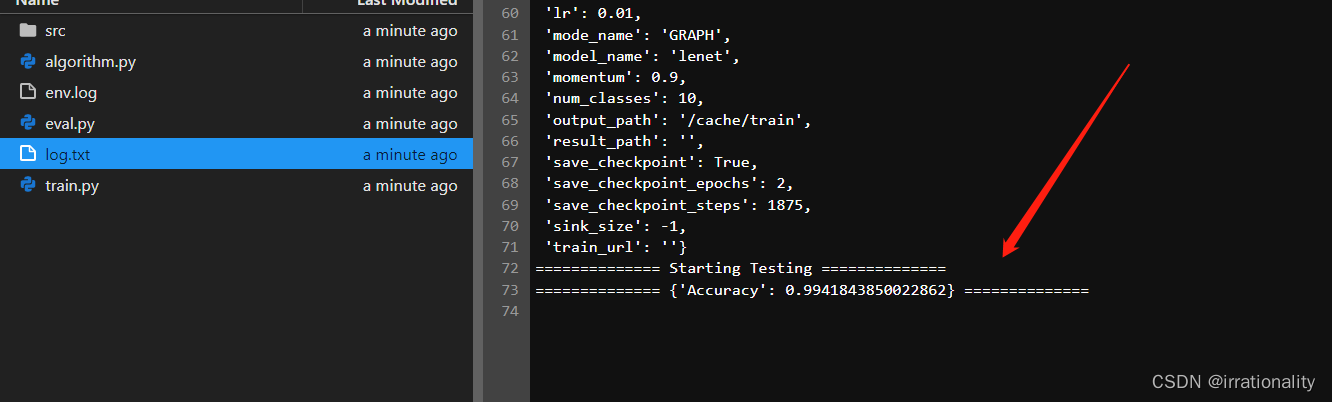
精度非常高的。
第一个作业完成了。
然后是第二个作业。
alexnet
先把全精度跑通
bash run_standalone_train_gpu.sh cifar10 ~/haahsummer/pro57msgs/models/official/cv/alexnet/data/cifar-10-batches-bin ckpt
- 1
- 2
30轮有点太久,跑了4~5个小时。一个模型427.9M
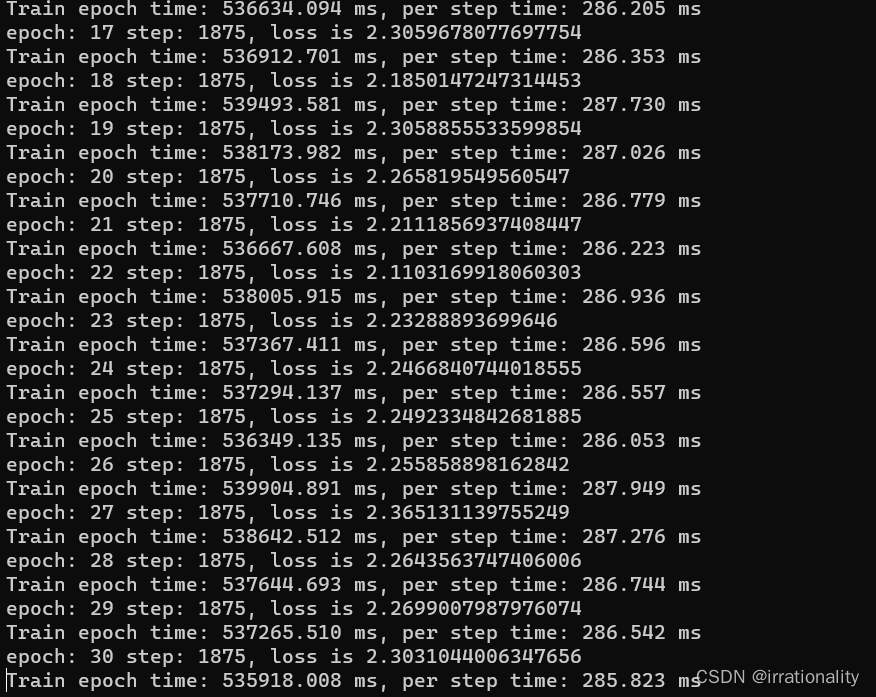
然后是测试
bash run_standalone_eval_gpu.sh cifar10 ~/haahsummer/pro57msgs/models/official/cv/alexnet/data/cifar-10-batches-bin ckpt/checkpoint_alexnet-30_1875.ckpt 0
- 1
- 2
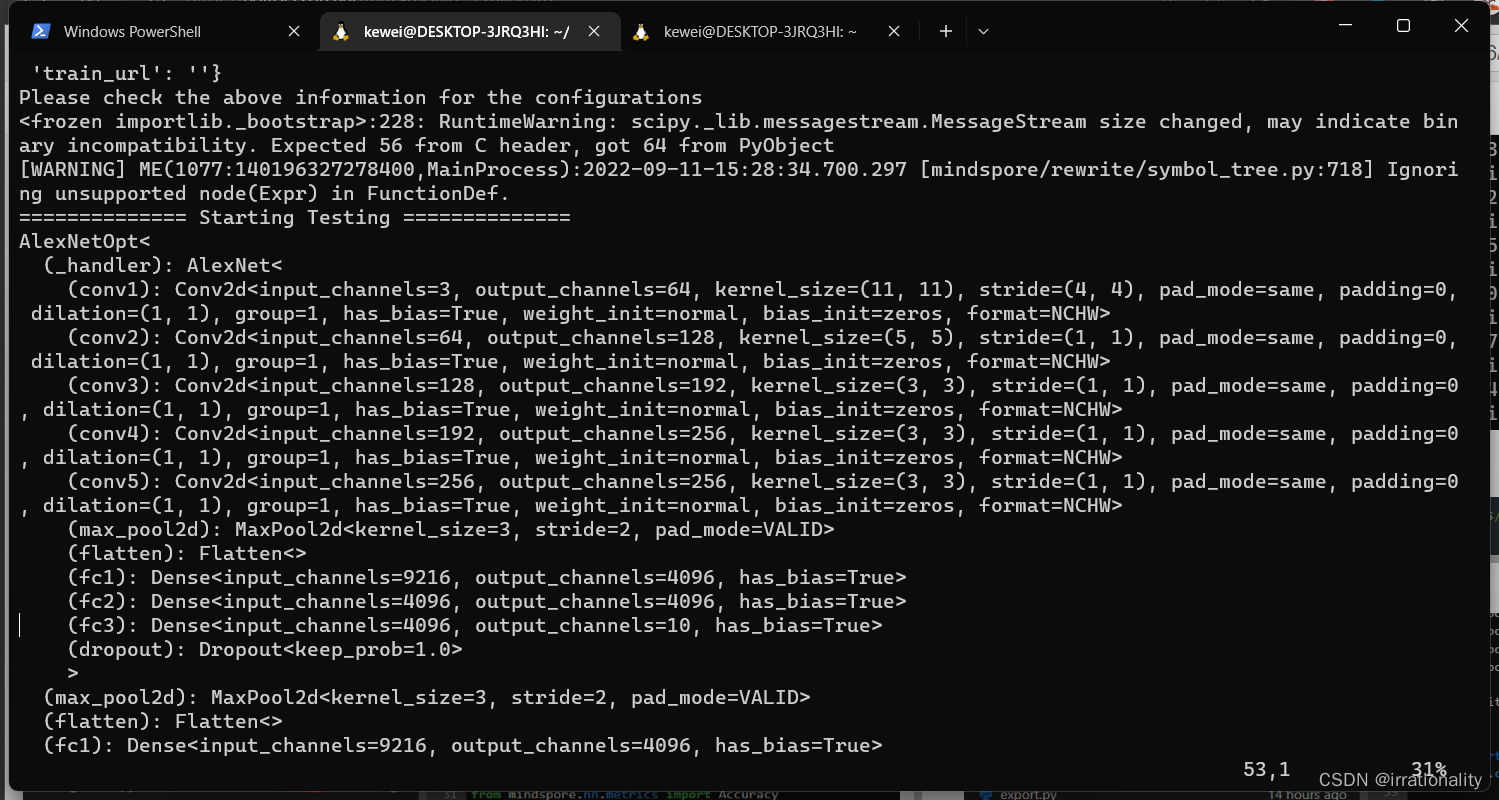
网络结构就打印出来了。
最后acc只有0.1,不知道原因是什么,在学校里有个课题我们也尝试用了女alexnet,效果也不是很好,那我们恐怕需要微调参数了,而且仔细看训练的loss,波动后也没有明显的下降。
要使用金箍棒
写一个algorithm.py
train和eval分别导入
eval中添加
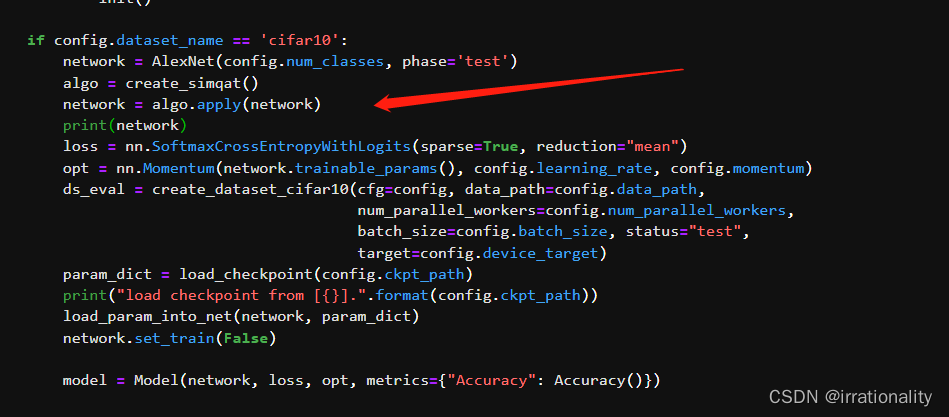
现在看来像alexnet这种比较大的网络,还是不要在本地比较好。
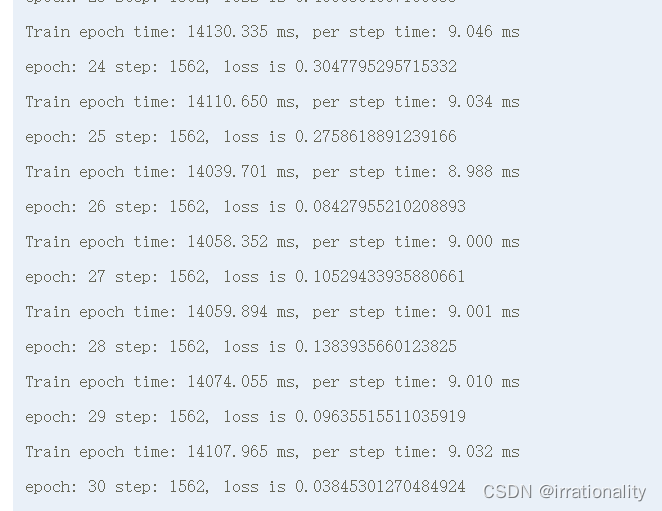
上面是全精度训练的结果。fp32训练后精度为0.88
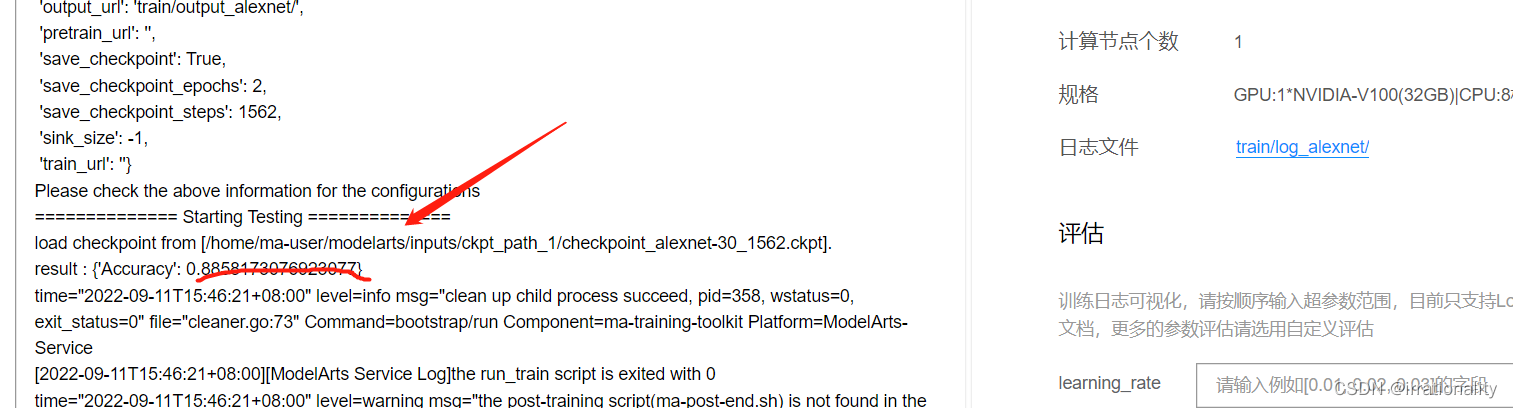
我们添加量化训练的eval和train逻辑,把对应部分量化。

fp32训练结果如图,15s一个epoch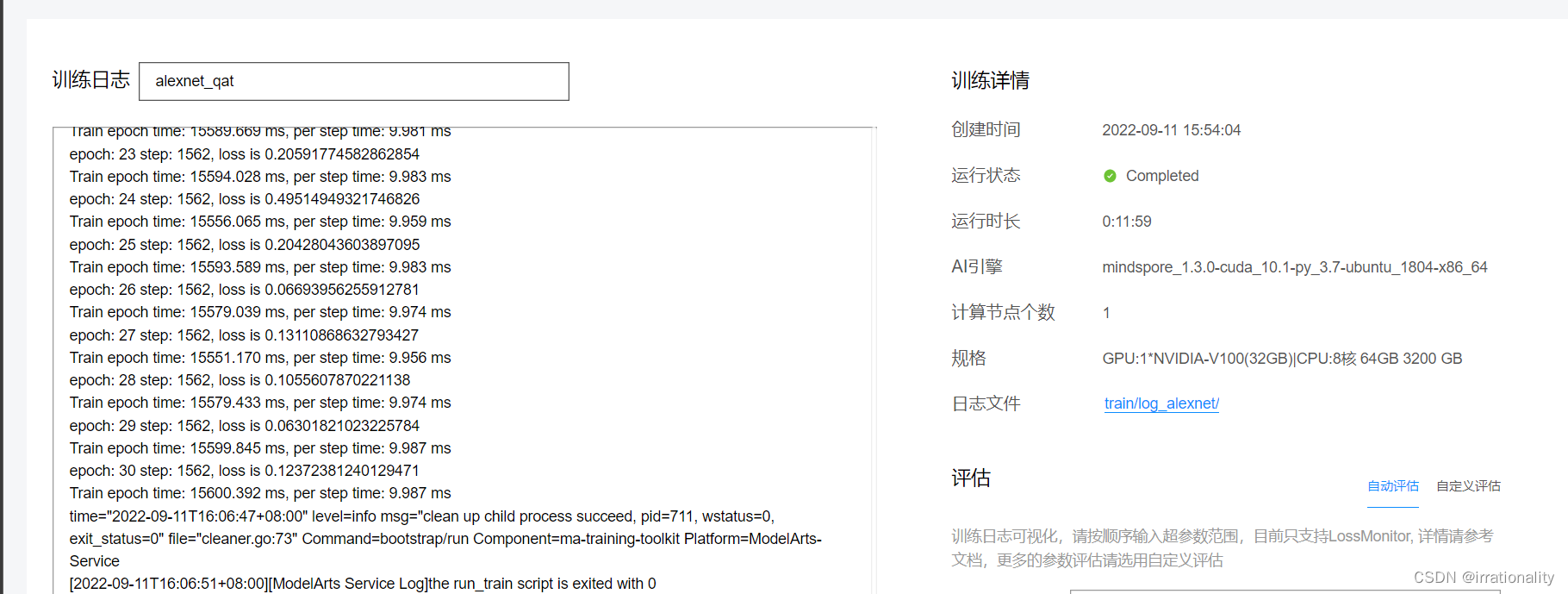
loss有序下降,并且训练速度比本地快得多。
量化训练用时明显比全精度训练慢了很多,一百多s一个epoch

量化测试采用刚刚生成的ckpt,并在测试脚本里添加打印量化后的网络的逻辑。


AlexNetOpt<
(_handler): AlexNet<
(conv1): Conv2d<input_channels=3, output_channels=64, kernel_size=(11, 11), stride=(4, 4), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True, weight_init=normal, bias_init=zeros, format=NCHW>
(conv2): Conv2d<input_channels=64, output_channels=128, kernel_size=(5, 5), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True, weight_init=normal, bias_init=zeros, format=NCHW>
(conv3): Conv2d<input_channels=128, output_channels=192, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True, weight_init=normal, bias_init=zeros, format=NCHW>
(conv4): Conv2d<input_channels=192, output_channels=256, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True, weight_init=normal, bias_init=zeros, format=NCHW>
(conv5): Conv2d<input_channels=256, output_channels=256, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True, weight_init=normal, bias_init=zeros, format=NCHW>
(max_pool2d): MaxPool2d<kernel_size=3, stride=2, pad_mode=VALID>
(flatten): Flatten<>
(fc1): Dense<input_channels=9216, output_channels=4096, has_bias=True>
(fc2): Dense<input_channels=4096, output_channels=4096, has_bias=True>
(fc3): Dense<input_channels=4096, output_channels=10, has_bias=True>
(dropout): Dropout<keep_prob=1.0>
>
(max_pool2d): MaxPool2d<kernel_size=3, stride=2, pad_mode=VALID>
(flatten): Flatten<>
(fc1): Dense<input_channels=9216, output_channels=4096, has_bias=True>
(fc2): Dense<input_channels=4096, output_channels=4096, has_bias=True>
(fc3): Dense<input_channels=4096, output_channels=10, has_bias=True>
(dropout): Dropout<keep_prob=1.0>
(Conv2dQuant): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=3, out_channels=64, kernel_size=(11, 11), stride=(4, 4), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 64), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dQuant_1): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=64, out_channels=128, kernel_size=(5, 5), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 128), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dQuant_2): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=128, out_channels=192, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 192), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dQuant_3): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=192, out_channels=256, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 256), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(Conv2dQuant_4): QuantizeWrapperCell<
(_handler): Conv2dQuant<
in_channels=256, out_channels=256, kernel_size=(3, 3), stride=(1, 1), pad_mode=same, padding=0, dilation=(1, 1), group=1, has_bias=True
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 256), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(DenseQuant): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=9216, out_channels=4096, weight=Parameter (name=DenseQuant._handler.weight, shape=(4096, 9216), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant._handler.bias, shape=(4096,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 4096), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(DenseQuant_1): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=4096, out_channels=4096, weight=Parameter (name=DenseQuant_1._handler.weight, shape=(4096, 4096), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_1._handler.bias, shape=(4096,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 4096), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
(DenseQuant_2): QuantizeWrapperCell<
(_handler): DenseQuant<
in_channels=4096, out_channels=10, weight=Parameter (name=DenseQuant_2._handler.weight, shape=(10, 4096), dtype=Float32, requires_grad=True), has_bias=True, bias=Parameter (name=DenseQuant_2._handler.bias, shape=(10,), dtype=Float32, requires_grad=True)
(fake_quant_weight): SimulatedFakeQuantizerPerChannel<bit_num=8, symmetric=True, narrow_range=False, ema=False(0.999), per_channel=True(0, 10), quant_delay=900>
>
(_input_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
(_output_quantizer): SimulatedFakeQuantizerPerLayer<bit_num=8, symmetric=False, narrow_range=False, ema=False(0.999), per_channel=False, quant_delay=900>
>
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
打印网络结构
训练后的精度为0.87几乎没有变化
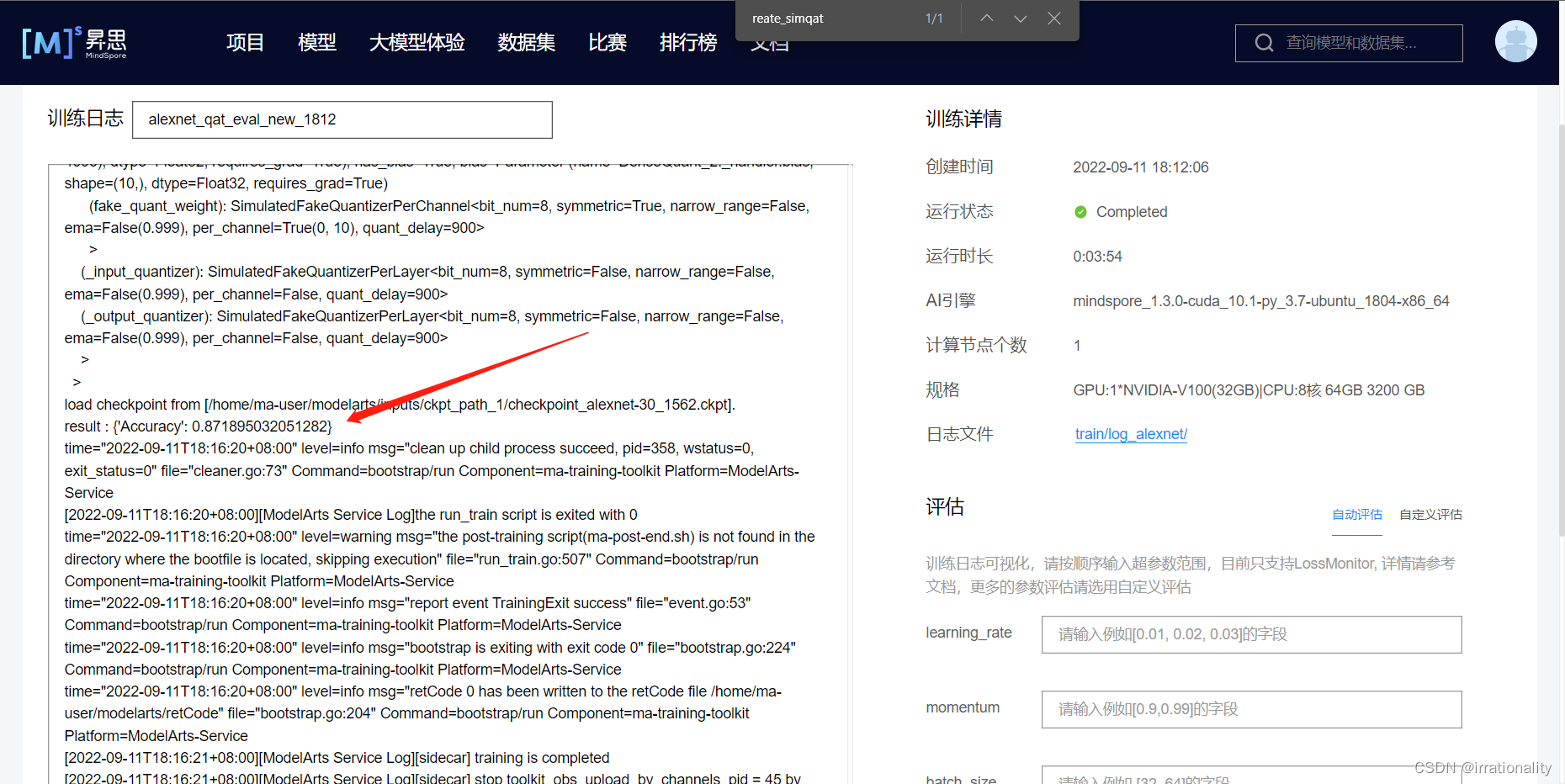
ok顺利完成。
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/126800367

- 点赞
- 收藏
- 关注作者
评论(0)