大数据调度平台Airflow(八):Airflow分布式集群搭建及测试

Airflow分布式集群搭建及测试
一、节点规划
|
节点IP |
节点名称 |
节点角色 |
运行服务 |
|---|---|---|---|
|
192.168.179.4 |
node1 |
Master1 |
webserver,scheduler |
|
192.168.179.5 |
node2 |
Master2 |
websever,scheduler |
|
192.168.179.6 |
node3 |
Worker1 |
worker |
|
192.168.179.7 |
node4 |
Worker2 |
worker |
二、airflow集群搭建步骤
1、在所有节点安装python3.7
参照单节点安装Airflow中安装anconda及python3.7
2、在所有节点上安装airflow
每台节点安装airflow需要的系统依赖
yum -y install mysql-devel gcc gcc-devel python-devel gcc-c++ cyrus-sasl cyrus-sasl-devel cyrus-sasl-lib 每台节点配置airflow环境变量
vim /etc/profile
export AIRFLOW_HOME=/root/airflow
#使配置的环境变量生效
source /etc/profile每台节点切换airflow环境,安装airflow,指定版本为2.1.3
(python37) conda activate python37
(python37) pip install apache-airflow==2.1.3 -i https://pypi.tuna.tsinghua.edu.cn/simple默认Airflow安装在$ANCONDA_HOME/envs/python37/lib/python3.7/site-packages/airflow目录下。配置了AIRFLOW_HOME,Airflow安装后文件存储目录在AIRFLOW_HOME目录下。可以每台节点查看安装Airflow版本信息:
(python37) airflow version
2.1.3在Mysql中创建对应的库并设置参数
aiflow使用的Metadata database我们这里使用mysql,在node2节点的mysql中创建airflow使用的库及表信息。
CREATE DATABASE airflow CHARACTER SET utf8;
create user 'airflow'@'%' identified by '123456';
grant all privileges on airflow.* to 'airflow'@'%';
flush privileges;在mysql安装节点node2上修改”/etc/my.cnf”,在mysqld下添加如下内容:
[mysqld]
explicit_defaults_for_timestamp=1以上修改完成“my.cnf”值后,重启Mysql即可,重启之后,可以查询对应的参数是否生效:
#重启mysql
[root@node2 ~]# service mysqld restart
#重新登录mysql查询
mysql> show variables like 'explicit_defaults_for_timestamp';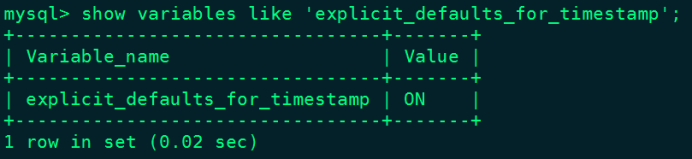
每台节点配置Airflow airflow.cfg文件
修改AIRFLOW_HOME/airflow.cfg文件,确保所有机器使用同一份配置文件,在node1节点上配置airflow.cfg,配置如下:
[core]
dags_folder = /root/airflow/dags
#修改时区
default_timezone = Asia/Shanghai
#配置Executor类型,集群建议配置CeleryExecutor
executor = CeleryExecutor
# 配置数据库
sql_alchemy_conn=mysql+mysqldb://airflow:123456@node2:3306/airflow?use_unicode=true&charset=utf8
[webserver]
#设置时区
default_ui_timezone = Asia/Shanghai
[celery]
#配置Celery broker使用的消息队列
broker_url = redis://node4:6379/0
#配置Celery broker任务完成后状态更新使用库
result_backend = db+mysql://root:123456@node2:3306/airflow将node1节点配置好的airflow.cfg发送到node2、node3、node4节点上:
(python37) [root@node1 airflow]# scp ./airflow.cfg node2:`pwd`
(python37) [root@node1 airflow]# scp ./airflow.cfg node3:`pwd`
(python37) [root@node1 airflow]# scp ./airflow.cfg node4:`pwd`三、初始化Airflow
1、每台节点安装需要的python依赖包
初始化Airflow数据库时需要使用到连接mysql的包,执行如下命令来安装mysql对应的python包。
(python37) # pip install mysqlclient -i https://pypi.tuna.tsinghua.edu.cn/simple2、在node1上初始化Airflow 数据库
(python37) [root@node1 airflow]# airflow db init初始化之后在MySQL airflow库下会生成对应的表。
四、创建管理员用户信息
在node1节点上执行如下命令,创建操作Airflow的用户信息:
airflow users create \
--username airflow \
--firstname airflow \
--lastname airflow \
--role Admin \
--email xx@qq.com执行完成之后,设置密码为“123456”并确认,完成Airflow管理员信息创建。
五、配置Scheduler HA
1、下载failover组件
登录https://github.com/teamclairvoyant/airflow-scheduler-failover-controller下载 airflow-scheduler-failover-controller 第三方组件,将下载好的zip包上传到node1 “/software”目录下。
在node1节点安装unzip,并解压failover组件:
(python37) [root@node1 software]# yum -y install unzip
(python37) [root@node1 software]# unzip ./airflow-scheduler-failover-controller-master.zip2、使用pip进行安装failover需要的依赖包
需要在node1节点上安装failover需要的依赖包。
(python37) [root@node1 software]# cd /software/airflow-scheduler-failover-controller-master
(python37) [root@node1 airflow-scheduler-failover-controller-master]# pip install -e .3、node1节点初始化failover
(python37) [root@node1 ~]# scheduler_failover_controller init
Adding Scheduler Failover configs to Airflow config file...
Finished adding Scheduler Failover configs to Airflow config file.
Finished Initializing Configurations to allow Scheduler Failover Controller to run. Please update the airflow.cfg with your desired configurations.注意:初始化airflow时,会向airflow.cfg配置中追加配置,因此需要先安装 airflow 并初始化。
4、修改airflow.cfg
首先修改node1节点的AIRFLOW_HOME/airflow.cfg
[scheduler_failover]
# 配置airflow Master节点,这里配置为node1,node2,两节点需要免密
scheduler_nodes_in_cluster = node1,node2
#在1088行,特别注意,需要去掉一个分号,不然后期自动重启Scheduler不能正常启动
airflow_scheduler_start_command = export AIRFLOW_HOME=/root/airflow;nohup airflow scheduler >> ~/airflow/logs/scheduler.logs &配置完成后,可以通过以下命令进行验证Airflow Master节点:
(python37) [root@node1 airflow]# scheduler_failover_controller test_connection
Testing Connection for host 'node1'
(True, ['Connection Succeeded', ''])
Testing Connection for host 'node2'
(True, ['Connection Succeeded\n'])将node1节点配置好的airflow.cfg同步发送到node2、node3、node4节点上:
(python37) [root@node1 ~]# cd /root/airflow/
(python37) [root@node1 airflow]# scp airflow.cfg node2:`pwd`
(python37) [root@node1 airflow]# scp airflow.cfg node3:`pwd`
(python37) [root@node1 airflow]# scp airflow.cfg node4:`pwd`六、启动Airflow集群
1、在所有节点安装启动Airflow依赖的python包
(python37) [root@node1 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3
(python37) [root@node2 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3
(python37) [root@node3 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.3
(python37) [root@node4 airflow]# pip install celery==4.4.7 flower==0.9.7 redis==3.5.32、在Master1节点(node1)启动相应进程
#默认后台启动可以使用-D ,这里使用-D有时不能正常启动Airflow对应进程
airflow webserver
airflow scheduler3、在Master2节点(node2)启动相应进程
airflow webserver4、在Worker1(node3)、Worker2(node4)节点启动Worker
在node3、node4节点启动Worker:
(python37) [root@node3 ~]# airflow celery worker
(python37) [root@node4 ~]# airflow celery worker5、在node1启动Scheduler HA
(python37) [root@node1 airflow]# nohup scheduler_failover_controller start > /root/airflow/logs/scheduler_failover/scheduler_failover_run.log &至此,Airflow高可用集群搭建完成。
七、访问Airflow 集群WebUI
浏览器输入node1:8080,查看Airflow WebUI:
八、测试Airflow HA
1、准备shell脚本
在Airflow集群所有节点{AIRFLOW_HOME}目录下创建dags目录,准备如下两个shell脚本,将以下两个脚本放在$AIRFLOW_HOME/dags目录下,BashOperator默认执行脚本时,默认从/tmp/airflow**临时目录查找对应脚本,由于临时目录名称不定,这里建议执行脚本时,在“bash_command”中写上绝对路径。如果要写相对路径,可以将脚本放在/tmp目录下,在“bash_command”中执行命令写上“sh ../xxx.sh”也可以。
first_shell.sh
#!/bin/bash
dt=$1
echo "==== execute first shell ===="
echo "---- first : time is ${dt}"second_shell.sh
#!/bin/bash
dt=$1
echo "==== execute second shell ===="
echo "---- second : time is ${dt}"
2、编写airflow python 配置
from datetime import datetime, timedelta
from airflow import DAG
from airflow.operators.bash import BashOperator
default_args = {
'owner':'zhangsan',
'start_date':datetime(2021, 9, 23),
'retries': 1, # 失败重试次数
'retry_delay': timedelta(minutes=5) # 失败重试间隔
}
dag = DAG(
dag_id = 'execute_shell_sh',
default_args=default_args,
schedule_interval=timedelta(minutes=1)
)
first=BashOperator(
task_id='first',
#脚本路径建议写绝对路径
bash_command='sh /root/airflow/dags/first_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),
dag = dag
)
second=BashOperator(
task_id='second',
#脚本路径建议写绝对路径
bash_command='sh /root/airflow/dags/second_shell.sh %s'%datetime.now().strftime("%Y-%m-%d"),
dag=dag
)
first >> second将以上内容写入execute_shell.py文件,上传到所有Airflow节点{AIRFLOW_HOME}/dags目录下。
3、重启Airflow,进入Airflow WebUI查看对应的调度
重启Airflow之前首先在node1节点关闭webserver ,Scheduler进程,在node2节点关闭webserver ,Scheduler进程,在node3,node4节点上关闭worker进程。
如果各个进程是后台启动,查看后台进程方式:
(python37) [root@node1 dags]# ps aux |grep webserver
(python37) [root@node1 dags]# ps aux |grep scheduler
(python37) [root@node2 dags]# ps aux |grep webserver
(python37) [root@node2 dags]# ps aux |grep scheduler
(python37) [root@node3 ~]# ps aux|grep "celery worker"
(python37) [root@node4 ~]# ps aux|grep "celery worker"
找到对应的启动命令对应的进程号,进行kill。重启后进入Airflow WebUI查看任务:
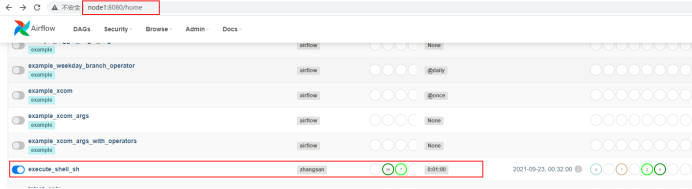
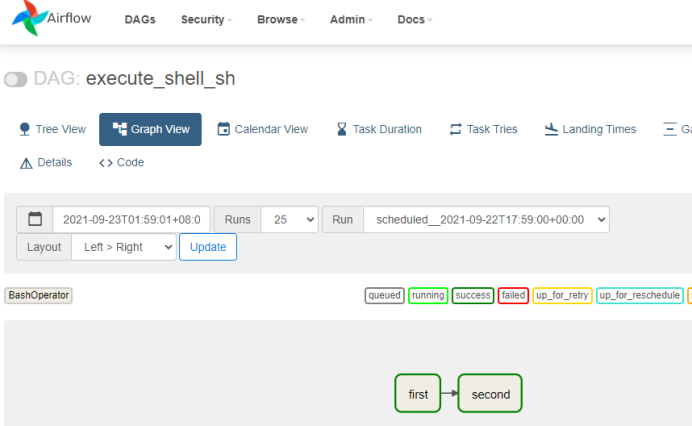
点击“success”任务后,可以看到脚本执行成功日志:
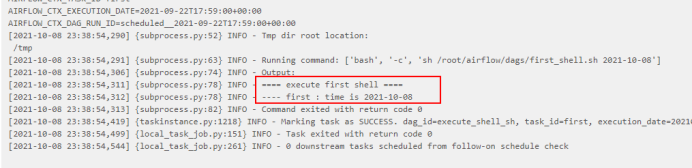
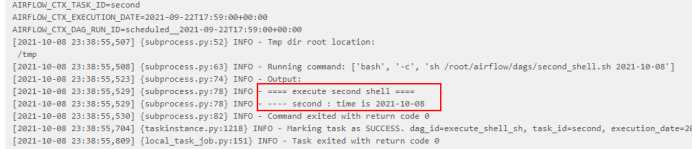
4、测试Airflow HA
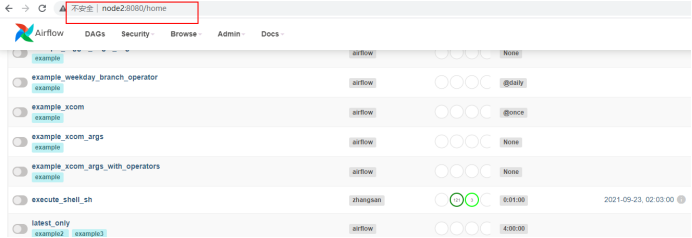
当我们把node1节点的websever关闭后,可以直接通过node2节点访问airflow webui:
在node1节点上,查找“scheduler”进程并kill,测试scheduler HA 是否生效:
(python37) [root@node1 ~]# ps aux|grep scheduler
root 23744 0.9 3.3 326940 63028 pts/2 S 00:08 0:02 airflow scheduler -- DagFileProcessorManager
#kill 掉scheduler进程
(python37) [root@node1 ~]# kill -9 23744
#访问webserver webui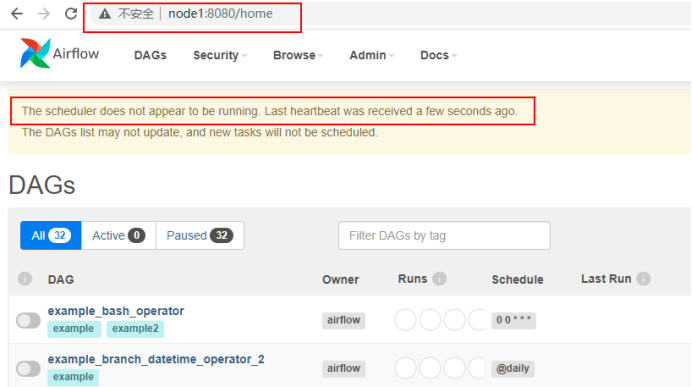
#在node1节点查看scheduler_failover_controller进程日志中有启动schudler动作,注意:这里是先从node1启动,启动不起来再从其他Master 节点启动Schduler。


- 点赞
- 收藏
- 关注作者
评论(0)