大数据ClickHouse进阶(九):ClickHouse的From和Sample子句

ClickHouse的From和Sample子句
一、From子句
From子句表示从何处读取数据,支持2种形式,由于From比较简单,这里不再举例,2种使用方式如下:
SELECT clo1 FROM tbl;
SELECT rst FROM (SELECT sum(col1) as rst FROM tbl) from 关键字可以省略,此时会从虚拟表中取数,ClickHouse中没有dual虚拟表,它的虚拟表是system.one,例如,以下两种查询等价:
SELECT 1;
SELECT 1 FROM system.one;另外,FROM 子句后还可以跟上final修饰符,可以配合COllapsingMergeTree和VersionedCollapsingMergeTree等表引擎进行查询操作,强制在查询过程中合并,由于Final修饰符会降低查询性能,所以尽量避免使用Final修饰符。
二、Sample子句
Sample子句可以实现数据采样功能,使查询仅返回采样数据而非全部数据,从而减少查询负载。Sample采样机制是幂等机制,也就是说在数据不发生变化,使用相同的采样规则总是能够返回相同的数据。
sample子句只能用于MergeTree系列表引擎,并且要求在Create Table时声明sample by 抽样表达式。
例如,创建表 tbl 声明sample by抽样表达式:
CREATE TABLE tbl(
id UInt32,
name String,
age UInt32,
birthday DATE
)ENGINE = MERGETREE()
PARTITION BY toYYYYMM(birthday)
ORDER BY (id,intHash32(age))
SAMPLE BY intHash32(age)以上创建sample by 采样表时注意:
- Sample by 所声明的表达式必须同时包含在主键的声明内。
- Sample Key 必须是Int类型,虽然在建表不报错,但是数据查询时报错。
另外,建表时没有声明Sample by,在使用sample 采样时会报错。
Sample目前支持三种语法,前面导入的datasets.hits_v1创建时指定了SAMPLE BY ,建表语句如下:
CREATE TABLE datasets.hits_v1(
`WatchID` UInt64,
`JavaEnable` UInt8,
`Title` String,
... ...
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(EventDate)
ORDER BY (CounterID, EventDate, intHash32(UserID))
SAMPLE BY intHash32(UserID)下面就以表hits_v1为例,来讲解sample三种用法。
- Sample factor
Sample factor表示按因子系数采样,factor表示采样因子,取值0-1之间的小数,表示采样总体数据的比例。如果factor 设置为0或者1,则表示不采样。使用如下:
#按10%的因子采样数据
SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.1;
839889 rows in set. Elapsed: 0.114 sec. Processed 7.36 million rows, 88.30 MB (64.46 million rows/s., 773.46 MB/s.)- Sample rows
Sample rows表示按照样本数量采样,其中rows表示大概采样多少行数据,是个近似值,取值必须大于1,如果rows行数大于表总数,效果等同于rows=1,即不采样。使用如下:
node1 :) SELECT count() FROM datasets.hits_v1 SAMPLE 10000;
┌─count()─┐
│ 9251 │
└─────────┘- SAMPLE factor OFFSET n
SAMPLE factor OFFSET n 表示按因子系数和偏移量采样,其中factor表示采样因子,即采样总数据的百分比,n表示偏移多少数据后才开始采样,它们两个取值都是0~1之间的小数。使用如下:
#偏移量0.5并按0.4的系数采样
node1 :) SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.4 OFFSET 0.5;
3589194 rows in set.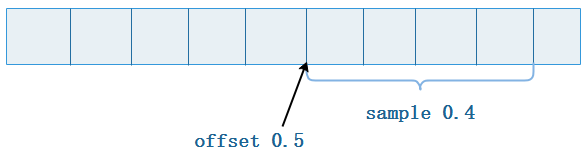
偏移量0.5并按0.4的系数采样的采样为:从数据的二分之一处开始,按总数量的0.4采样数据。如果Sample比例采样出现了溢出,则数据会被自动截断,例如:
node1 :) SELECT CounterID FROM datasets.hits_v1 SAMPLE 0.4 OFFSET 0.9;
892694 rows in set.

- 点赞
- 收藏
- 关注作者
评论(0)