大数据ClickHouse进阶(二):MergeTree表引擎

MergeTree表引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。而MergeTree系列表引擎是官方主推的存储引擎,有主键索引、数据分区、数据副本、数据采样、删除和修改等功能,支持几乎所有ClickHouse核心功能。
MergeTree系列表引擎包含:MergeTree、ReplacingMergeTree、SummingMergeTree(汇总求和功能)、AggregatingMergeTree(聚合功能)、CollapsingMergeTree(折叠删除功能)、VersionedCollapsingMergeTree(版本折叠功能)引擎,在这些的基础上还可以叠加Replicated和Distributed。
MergeTree在写入一批数据时,数据总会以数据片段的形式写入磁盘,且数据片段在磁盘上不可修改。为了避免片段过多,ClickHouse会通过后台线程,定期合并这些数据片段,属于相同分区的数据片段会被合成一个新的片段。这种数据片段往复合并的特点,也正是合并树名称的由来。
一、MergeTree
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
- 存储的数据按照主键排序:创建稀疏索引加快数据查询速度。
- 支持数据分区,可以通过PARTITION BY语句指定分区字段。
- 支持数据副本。
- 支持数据采样。
MergeTree建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]关于以上建表语句的解释如下:
1、ENGINE:ENGINE = MergeTree(),MergeTree引擎没有参数。
2、ORDER BY:排序字段。比如ORDER BY (Col1, Col2),值得注意的是,如果没有使用 PRIMARY KEY 显式的指定主键ORDER BY排序字段自动作为主键。如果不需要排序,则可以使用 ORDER BY tuple() 语法,这样的话,创建的表也就不包含主键。这种情况下,ClickHouse会按照插入的顺序存储数据。必选项。
3、PARTITION BY:分区字段,例如要按月分区,可以使用表达式 toYYYYMM(date_column),这里的date_column是一个Date类型的列,分区名的格式会是"YYYYMM"。可选。
4、PRIMARY KEY:指定主键,如果排序字段与主键不一致,可以单独指定主键字段。否则默认主键是排序字段。大部分情况下不需要再专门指定一个 PRIMARY KEY 子句,注意,在MergeTree中主键并不用于去重,而是用于索引,加快查询速度。可选。
另外,如果指定了PRIMARY KEY与排序字段不一致,要保证PRIMARY KEY 指定的主键是ORDER BY 指定字段的前缀,比如:
--允许
... ...
ORDER BY (A,B,C)
PRIMARY KEY A
--报错
... ...
ORDER BY (A,B,C)
PRIMARY KEY B
DB::Exception: Primary key must be a prefix of the sorting key这种强制约束保障了即便在两者定义不同的情况下,主键仍然是排序键的前缀,不会出现索引与数据顺序混乱的问题。
5、SAMPLE BY:采样字段,如果指定了该字段,那么主键中也必须包含该字段。比如 SAMPLE BY intHash32(UserID) ORDER BY (CounterID, EventDate, intHash32(UserID))。可选。
6、TTL:数据的存活时间。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。可选。
7、SETTINGS:额外的参数配置。可选。
二、MergeTree引擎表目录解析
这里我们介绍下MergeTree引擎表对应到磁盘的数据目录,Clikchouse新版本与之前版本对比,数据对应的磁盘目录略有不同。
创建表t_mt,并加载数据:
CREATE TABLE t_mt
(
`id` UInt8,
`name` String,
`age` UInt8,
`birthday` Date,
`location` String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(birthday)
ORDER BY (id, age)
#向表t_mt中插入数据
insert into t_mt values (1,'张三',18,'2021-06-01','上海'), (2,'李四',19,'2021-02-10','北京'), (3,'王五',12,'2021-06-01','天津'), (1,'马六',10,'2021-06-18','上海'), (5,'田七',22,'2021-02-09','广州');以上创建好表t_mt,当插入数据完成后,在ClickHouse节点/var/lib/ClickHouse/data/newdb/路径下会生成对应目录“t_mt”,进入此目录下,可以看到对应的分区目录,如图示:

以上分区目录也可以在系统表“system.parts”中查询得到:
#在系统表 system.part中查询表 t_mt的分区信息:
select table ,partition ,name ,active from system.parts where table = 't_mt';
进入到某一个分区目录片段“202102_2_2_0”中,我们可以看到如下目录:
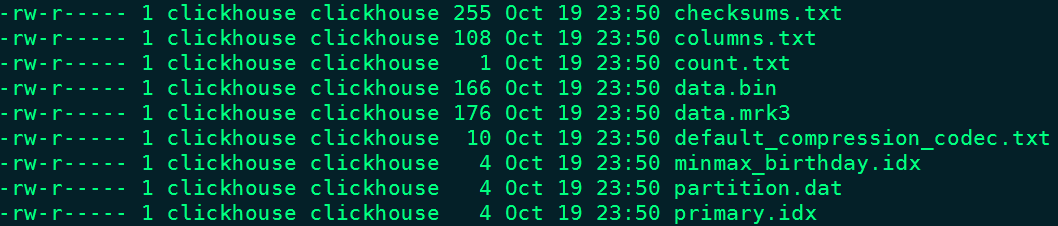
对以上目录的解释如下:
1、checksums.txt:校验文件,使用二进制格式存储。它保存了余下各类文件(primary. idx、count.txt等)的size大小及size的哈希值,用于快速校验文件的完整性和正确性。
2、columns.txt: 存储当前分区所有列信息。使用明文格式存储。
[root@node1 202102_2_2_0]# cat columns.txt
columns format version: 1
5 columns:
`id` UInt8
`name` String
`age` UInt8
`birthday` Date
`location` String3、count.txt:计数文件,使用明文格式存储。用于记录当前数据分区目录下数据的总行数。
[root@node1 202102_2_2_0]# cat count.txt
2- data.bin:数据文件,使用压缩格式存储,默认为LZ4压缩格式,用于存储某一列的数据。之前clickhoue版本是每一个列字段都拥有独立的.bin数据文件,并以列字段名称命名,在新版本ClickHouse中所有数据合并到data.bin中。
之前ClickHouse版本此目录数据如下:
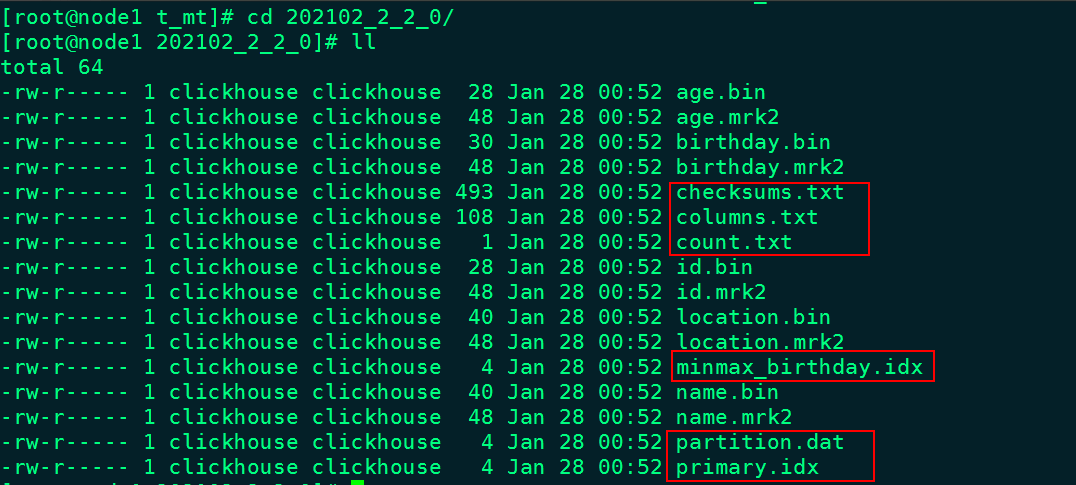
4、data.mrk3:列字段标记文件,使用二进制格式存储。标记文件中保存了data.bin文件中数据的偏移量信息
5、default_compression_codec.txt:存储数据压缩格式
6、partition.dat与minmax_[Column].idx:如果指定了分区键,则会额外生成partition.dat与minmax索引文件,它们均使用二进制格式存储。partition.dat用于保存当前分区下分区表达式最终生成的值,即分区字段值;而minmax索引用于记录当前分区下分区字段对应原始数据的最小和最大值。比如当使用birthday字段对应的原始数据为2021-02-17、2021-02-23,分区表达式为PARTITION BY toYYYYMM(birthday),即按月分区。partition.dat中保存的值将会是202102,而minmax索引中保存的值将会是2021-02-17、2021-02-23。
ClickHouse MergeTree引擎表支持分区,索引,修改,并发查询数据,当查询MergeTree表数据时,首先向primary.idx文件中获取对应的索引,根据索引找到【data.mrk3】文件获取对应的数据块偏移量,然后再根据偏移量从【data.bin】文件中读取块数据。
7、primary.idx:一级索引文件,使用二进制格式存储。用于存放稀疏索引,一张MergeTree表只能声明一次一级索引,即通过ORDER BY或者PRIMARY KEY指定字段。借助稀疏索引,在数据查询的时能够排除主键条件范围之外的数据文件,从而有效减少数据扫描范围,加速查询速度。

- 点赞
- 收藏
- 关注作者
评论(0)