分区再平衡

4 分区再平衡(rebalancing)
随业务井喷,DB出现变化:
- 查询负载增加,需更多CPU处理负载
- 数据规模增加,需更多磁盘和内存来存储
- 节点可能故障,需要其他节点接管失效节点
所有这些更改都要求数据、请求可以从一个节点转移到另一个节点。 将负载从集群中的一个节点向另一个节点移动的过程称为 再平衡(rebalancing)。无论哪种分区策略,分区rebalancing通常至少要满足:
- rebalancing后,负载、数据存储、读写请求应在集群内更均匀分布
- rebalancing执行时,DB应能继续正常读写
- 避免不必要的负载迁移,以加速rebalancing效率,并尽量减少网络和磁盘 I/O 影响
4.1 再平衡策略
4.1.1 反面教材:hash mod N
图-3提过,最好将hash值分成不同区间范围,然后每个区间分配给一个分区。
那为何不使用mod(Java中的%运算符)。如hash(key) mod 10 返回介于 0 和 9 之间的数字。若有 10 个节点,编号为 0~9,这似乎是将每个K分配给一个节点的最简单方法。
但问题是,若节点数量 N 变化,大多数K将需从一个节点移动到另一个。假设 hash(key)=123456 。最初10个节点,则该K一开始在节点6(因为123456 mod 10 = 6):
- 当增长到 11 个节点,K需移动到节点 3( )
- 当增长到 12 个节点,K需要移动到节点 0( )
这频繁的迁移大大增加rebalancing的成本。
所以重点是减少迁移的数据。
4.1.2 固定数量的分区
还好有个很简单的解决方案:创建比节点更多的分区,并为每个节点分配多个分区。如10 个节点的集群,DB可能会从一开始就逻辑划分为 1,000 个分区,因此大约有 100 个分区分配给每个节点。
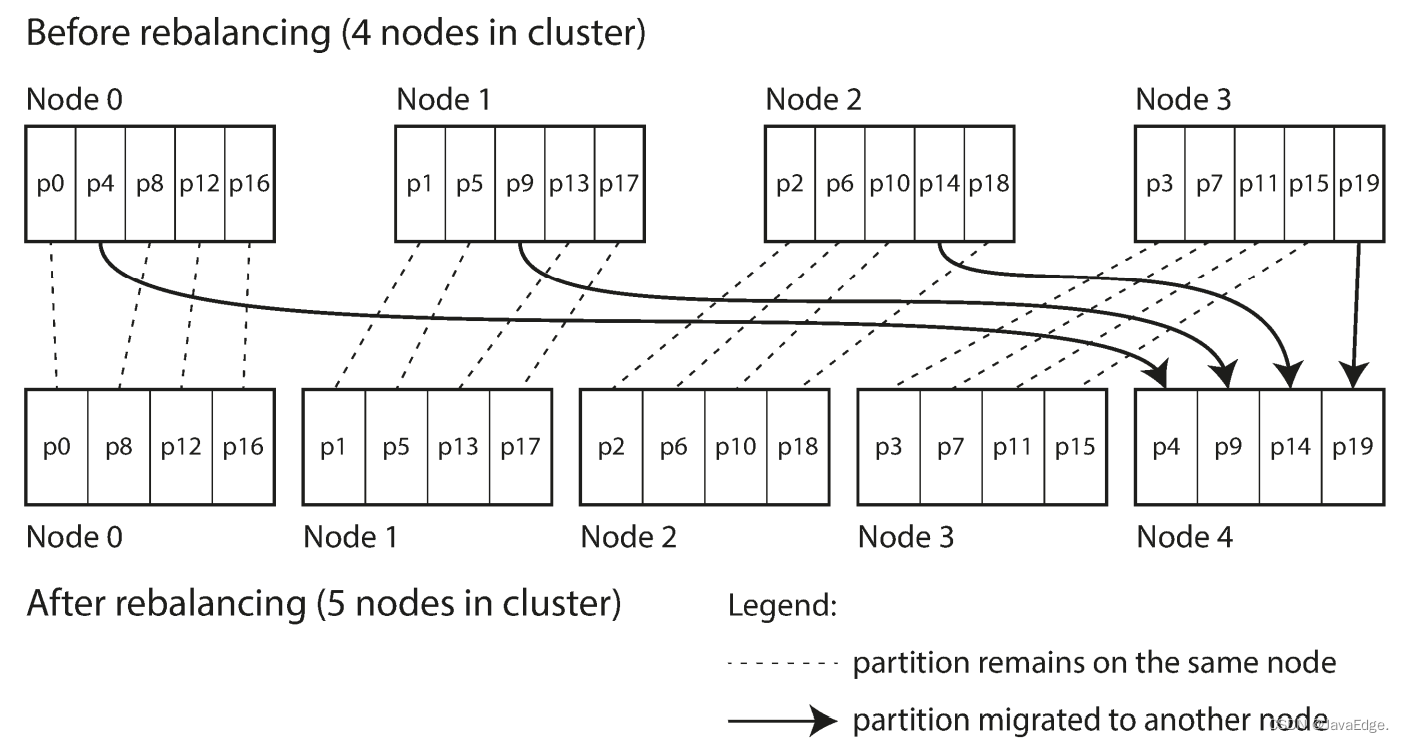
若一个新节点加入集群,新节点可以从当前每个节点中窃取一些分区,直到分区再次达到全局平衡。过程如图-6。若从集群中删除一个节点,则会发生相反情况。
选中的整个分区会在节点之间迁移,但分区的总数不变,K到分区的映射关系也不变。唯一变的是分区所在节点。这种变更并非即时,毕竟在网络上传输数据总需要时间,所以在传输过程中,旧分区仍可接收读写操作。
原则上,也可以将集群中的不同的硬件配置因素考虑进来:性能更强大的节点分配更多分区,从而能分担更多负载。在ES 、Couchbase中使用了这种动态平衡方法。
使用该策略时,分区数量通常在DB第一次建立时确定,之后不会改变。虽然原则上可拆分、合并分区,但固定数量的分区使得操作都更简单,因此许多固定分区策略的 DB 决定不支持分区拆分。因此,初始化时的分区数就是你能拥有的最大节点数量,所以你要充分考虑将来业务需求,设置足够大的分区数。但每个分区也有额外管理开销,选择过高数字也有副作用。
若数据集的总规模难预估(如可能开始很小,但随时间推移会变异常得大),此时,选择合适的分区数就很难。由于每个分区包含的数据量上限是固定的,因此每个分区的实际大小与集群中的数据总量成正比:
- 若分区里的数据量很大,则再平衡和从节点故障恢复的代价就很大
- 若分区太小,则会产生太多开销
分区大小应“恰到好处”,若分区数量固定了,但总数据量却变动很大,则难以达到最佳性能。

- 点赞
- 收藏
- 关注作者
评论(0)