easyRL学习笔记:强化学习基础

【摘要】
https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1
pip install gym
1
配置开发环境 https://book....
https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1
pip install gym
- 1
配置开发环境

https://book.douban.com/subject/35043939/
https://zhuanlan.zhihu.com/reinforce
参考项目二
python train.py
visualdl --logdir=train_log/train --host=172.30.159.168
- 1
- 2
- 3
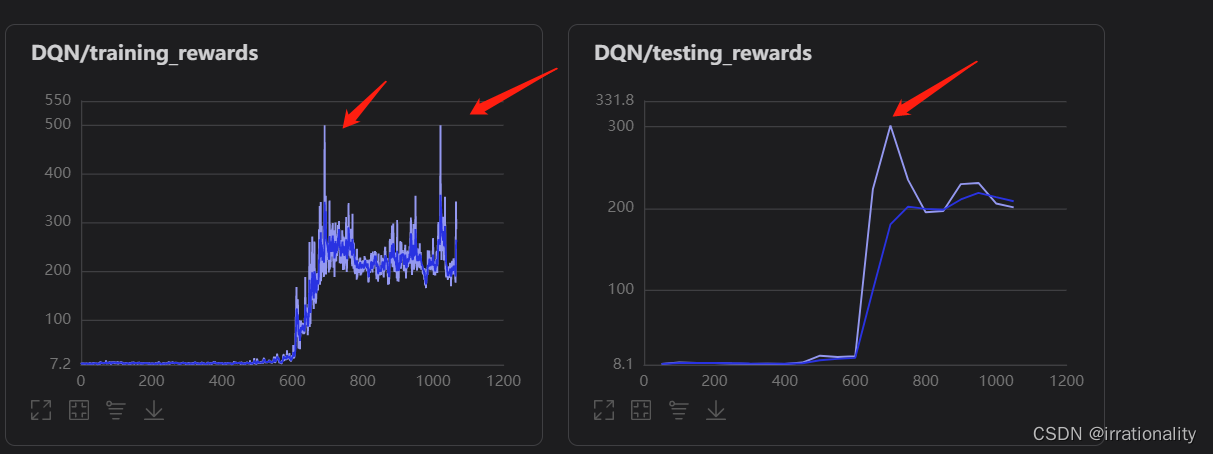
这三个高峰意味着什么呢?
偶尔的突变

6分钟左右跑完成了,我们看看效果。
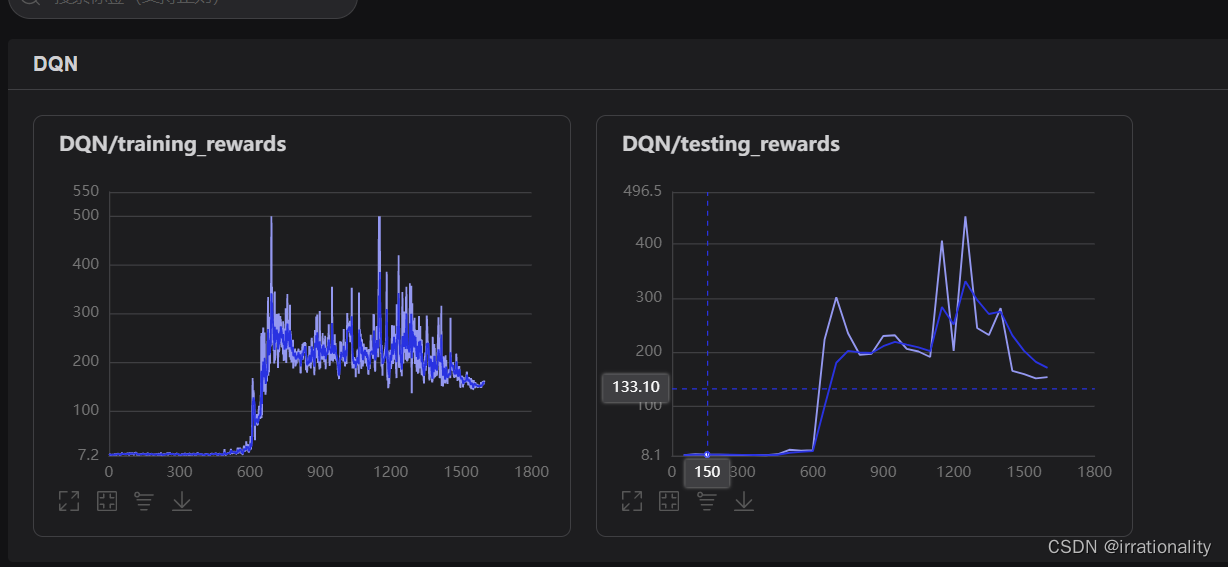
不知道什么原因,感觉后面是越训练越差劲了,后面我们再调试女一下。
note:
前面sarsa是同策略的一直是策略π,Q学习是异策略的每次算maxQ,第六章深度Q网络是只属于异策略部分的一个深度算法。
第六章刚开始的价值函数近似只有Q函数近似,是不是就是说策略迭代时候从Q表格找maxQ用近似函数代替,价值迭代时候不需要近似V函数,然后这个近似Q和不近似的V再用深度网络训练。
DQN里还有目标网络,是不是这第六章到第九章都是在异策略的条件下做的?
参考链接https://datawhalechina.github.io/easy-rl/#/chapter1/chapter1
Actor-Critic算法,可以这么说(PPO也可以说是异策略)
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/126395876

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)