【MySQL从入门到精通】【高级篇】(十一)Hash索引、AVL树、B树与B+树对比

您好,我是码农飞哥,感谢您阅读本文,欢迎一键三连哦。
💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精通
❤️ 2. Python爬虫专栏,系统性的学习爬虫的知识点。9.9元买不了吃亏,买不了上当 。python爬虫入门进阶
❤️ 3. Ceph实战,从原理到实战应有尽有。 Ceph实战
❤️ 4. Java高并发编程入门,打卡学习Java高并发。 Java高并发编程入门
😁 5. 社区逛一逛,周周有福利,周周有惊喜。码农飞哥社区,飞跃计划
全网同名【码农飞哥】欢迎关注,个人VX: wei158556
文章目录
1. 简介
上一篇文章我们介绍了 【MySQL从入门到精通】【高级篇】(十)MyISAM的索引方案&&索引的优缺点,这篇文章我们接着来对Hash索引、AVL树、B树以及B+树进行对比。
MySQL索引概述
从MySQL的角度讲,不得不考虑一个现实问题就是磁盘IO, 如果我们能让索引的数据结构尽量减少硬盘的IO操作,所消耗的时间也就越小,可以说,磁盘的I/O操作次数 对索引的使用效率至关重要。
查找都是索引操作,一般来说索引非常大,尤其是关系型数据库,当数据量比较大的时候,索引的大小有可能几个G甚至更多,为了减少索引在内存的占用,数据库索引是存储在外部磁盘上的。 当我们利用索引查询的时候,不可能把整个索引全部加载到内存,只能逐一加载,那么MySQL衡量查询效率的标准就是磁盘IO次数。
全表遍历
全表遍历没有使用到索引,就是一条条遍历表中的数据。
Hash结构
Hash本身是一个函数,又被称为散列函数,它可以帮助我们大幅提升检索数据的效率。
Hash算法是通过某种确定性的算法(比如MD5、SHA1、SHA2、SHA3)将输入转变为输出。相同的输入永远可以得到相同的输出,假设输入内容由微小偏差,则输出结果通常会不相同。
比如要验证两个数据文件是否相同,只需要将这两个数据文件分别进行Hash操作,如果Hash操作的结果一致,则表示这两个文件内容相同。
加快查找速度的数据结构,常见的有两类:
- 树,例如平衡二叉搜索树,查询/插入/修改/删除的平均时间复杂度都是O(log2N)
- 哈希,例如HashMap,查询/插入/修改/删除的平均时间复杂度都是O(1)。

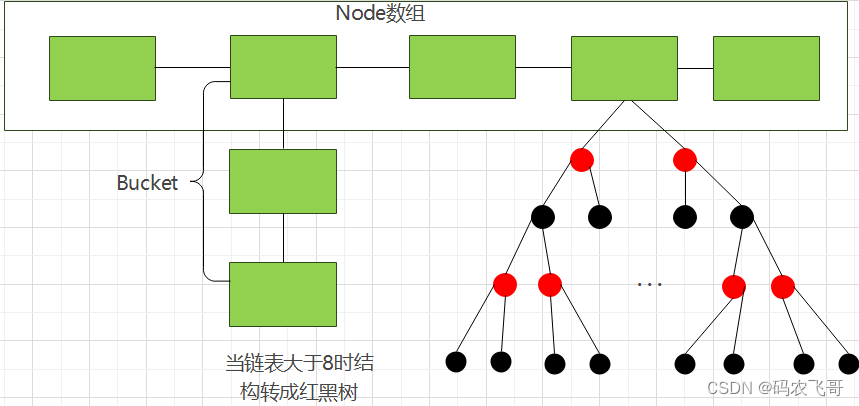
采用Hash进行检索效率非常高,基本上一次检索就可以找到数据,而B+树需要自顶向下依次查找,多次访问节点才能找到数据,中间需要多次I/O操作,从效率来说Hash 比B+树更快。
在哈希的方式下,一个元素K处于h(k)中,即利用哈希函数h,根据关键字k计算出槽的位置,函数h将关键字域映射到哈希表T[0…m-1]的槽位上。
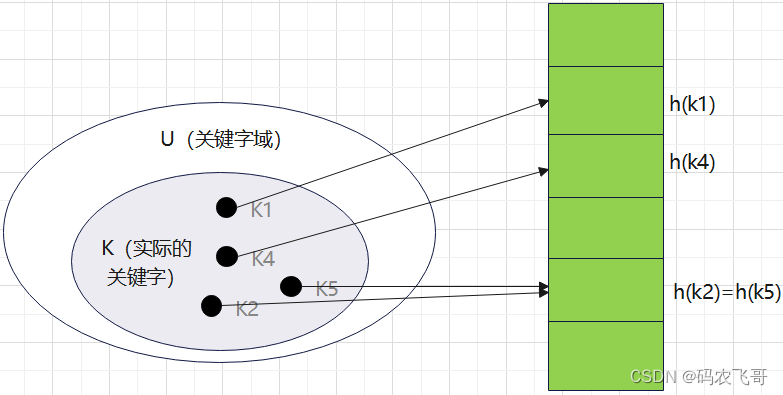
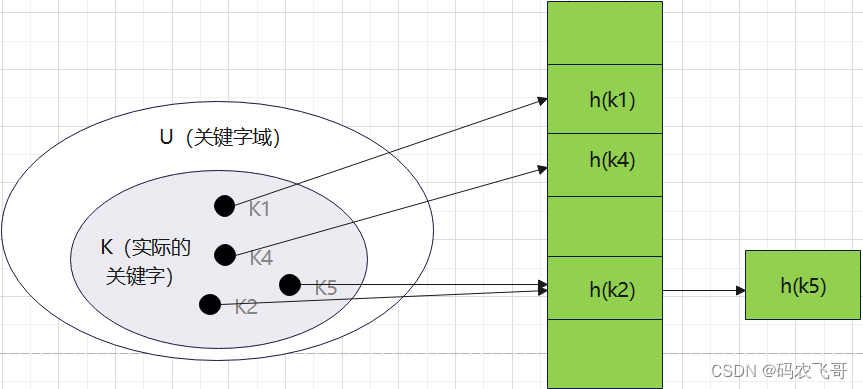
Hash结构的效率高,那为什么索引结构要设计为树型呢?
原因1:Hash索引仅能满足(=)(<>)和IN查询。如果进行范围查询,哈希型的索引,时间复杂度会退化为O(n);而树型的"有序"特性,依然能够保持O(log2N)的高效率。
原因2:Hash索引还有一个缺陷,数据的存储是没有顺序的,在ORDER BY的情况下,使用Hash索引还需要对数据进行重排序。
原因3:对联合索引的情况,Hash值是将联合索引键合并后一起来计算的,无法对单独的一个键或者几个索引进行查询。
原因4:对于等值查询来说,通常Hash索引的效率更高,不过也存在一种情况,就是索引列的重复值如果很多,效率就会降低。 这是因为遇到Hash冲突时,需要遍历桶中的行指针进行比较,找到查询的关键字,非常耗时。所以,Hash索引通常不会用到重复值多的列上,比如列为性别、年龄的情况等。
Hash索引适用存储引擎如表所示:
| 索引/存储引擎 | MyISAM | InnoDB | Memory |
|---|---|---|---|
| HASH索引 | 不支持 | 不支持 | 支持 |
Hash索引的适用性:
Hash索引存在着很多限制,相比之下在数据库中B+树索引的使用面会更广,不过也有一些场景采用Hash索引效率更高,比如在键值型(Key-Value)数据库中,Redis存储的核心就是Hash表。
MySQL中的Memory存储支持Hash存储,如果我们需要用到查询的临时表时,就可以选择Memory存储引擎,把某个字段设置为Hash索引,比如字符串类型的字段,进行Hash计算之后长度就可以缩短到几个字节,当字段的重复度低,而且经常需要进行等值查询的时候,采用Hash索引是个不错的选择。
另外,InnoDB 本身不支持Hash索引,但是提供自适应Hash索引(Adaptive Hash Index)。什么情况下才会使用自适应Hash索引呢?如果某个数据经常被访问,当满足一定条件的时候,就会将这个数据页的地址存放到Hash表中,这样下次查询的时候,就可以直接找到这个页面的所在位置,这样让B+树也具备Hash索引的优点。
二叉搜索树
如果我们利用二叉树作为索引结构,那么磁盘的IO次数和索引树的高度是相关的。
二叉搜索树的特点
- 一个节点只能有两个子节点,也就是一个节点度不能超过2
- 左子节点<本节点;右子节点>=本节点,比我小的在左,比我大的在右。
查找规则
我们先来看下最基础的二叉搜索树(Binary Search Tree), 搜素某个节点和插入节点的规则一样,我们假设搜索插入的数值为key:
- 如果key大于根节点,则在右子树中进行查找;
- 如果key小于根节点,则在左子树中进行查找;
- 如果key等于根节点,也就是找到了这个节点,返回根节点即可。
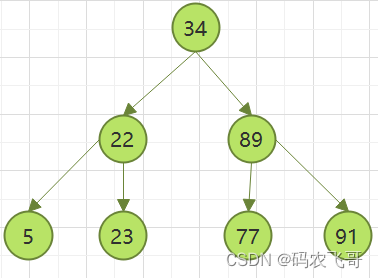
举个例子,我们对数列(34,22,89,5,23,77,91)创造出来的二分查找树如下图所示:
但是存在特殊的情况,就是有时候二叉树的深度非常大,比如我们给出的数据顺序是(5,22,23,34,77,89,91),创造出来的二分搜索树如下图所示:
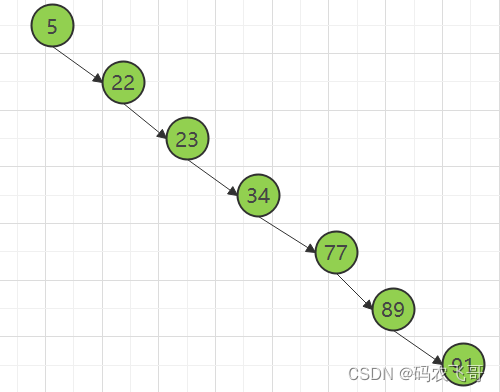
上面第二棵树也属于二分查找树,但是性能已经退化成了一条链表,查找数据的时间复杂度变成了O(n)。你能看到第一棵树的深度是3,也就是说最多只需3次比较,就可以找到节点,而第二个树的深度是7,最多需要7次比较才能找到节点。
AVL树
为了解决上面二叉查找树退化成链表的问题,人们提出了平衡二叉搜索树(Balance Binary Tree)。又称为AVL树(有别于AVL算法),它在二叉搜索树的基础上增加了约束,具有一下性质:
它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
这里说一下,常见的平衡二叉树有很多种,包括了平衡二叉搜索树、红黑树、数堆、伸展树 。平衡二叉搜索树是最早提出来的自平衡二叉搜索树,当我们平衡二叉树时一般指的就是平衡二叉搜索树。事实上,第一棵树就属于平衡二叉搜索树,搜索时间复杂度就是O(log2n)。
数据查询的时间主要依赖于磁盘I/O的次数,如果我们采用二叉树的形式,即使通过平衡二叉搜索树进行改进,树的深度也是O(log2N),当n比较大时,深度也是比较高的,比如下图的情况:
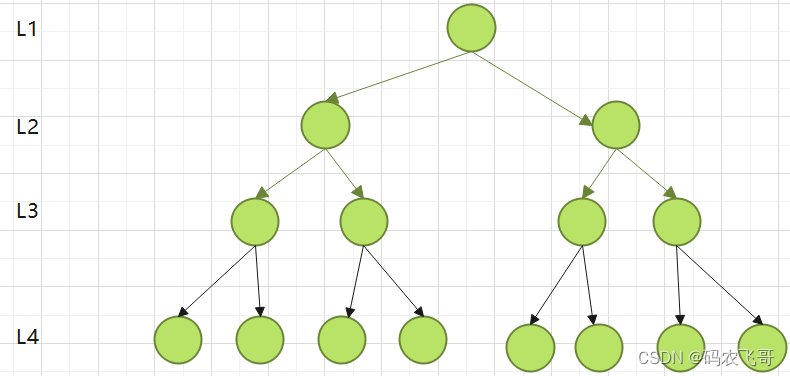
每访问一次节点就需要进行一次磁盘I/O操作,对于上面的树来说,我们需要进行5次I/O操作,虽然平衡二叉树的效率高,但是树的深度也同样高,这就意味着磁盘I/O操作次数多,会影响整体数据查询的效率。
针对同样的数据,如果我们把二叉树改成M叉树(M>2)呢?当M=3时,同样的15个节点可以由下面的三叉树来进行存储:

B树
B树的英文是Balance Tree,也就是多路平衡查找树。简写为B-Tree(注意横杠表示这两个单词连起来的意思,不是减号)。它的高度远小于平衡二叉树的高度。
B树作为多路平衡查找树,它的每一个节点最多可以包含M个子节点,M称为B树的阶。每个磁盘块包括了关键字和子节点的指针。如果一个磁盘块中包含了X个关键字,那么指针数就是x+1。对于一个100阶的B树来说,如果有3层的话最多可以存储约100万的索引数据。对于大量的索引数据来说,采用B树的结构是非常适合的,因为树的高度要远小于二叉树的高度。
一个M阶的B树(M>2)有以下特性:
- 根节点的儿子数的范围是
[2,M]。 - 每个中间节点包含k-1关键字和k个孩子,孩子的数量=关键字的数量+1,k的取值范围为[cei(M/2)],
- 假设中间节点的关键字为: key[1],key[2],…key[k-1],且关键字按照升序排序,即
key[i]<key[i+1]。此时k-1个关键字相当于划分了k个范围,也就是对应着k个指针,即为:P[1],P[2],…P[k],其中P[1]指向关键字小于key[1]的子树,P[i]指向关键字属于(key[i-1],key[i])的子树,P[k] 指向关键字大于key[k-1] 的子树。 - 所有叶子节点位于同一层。
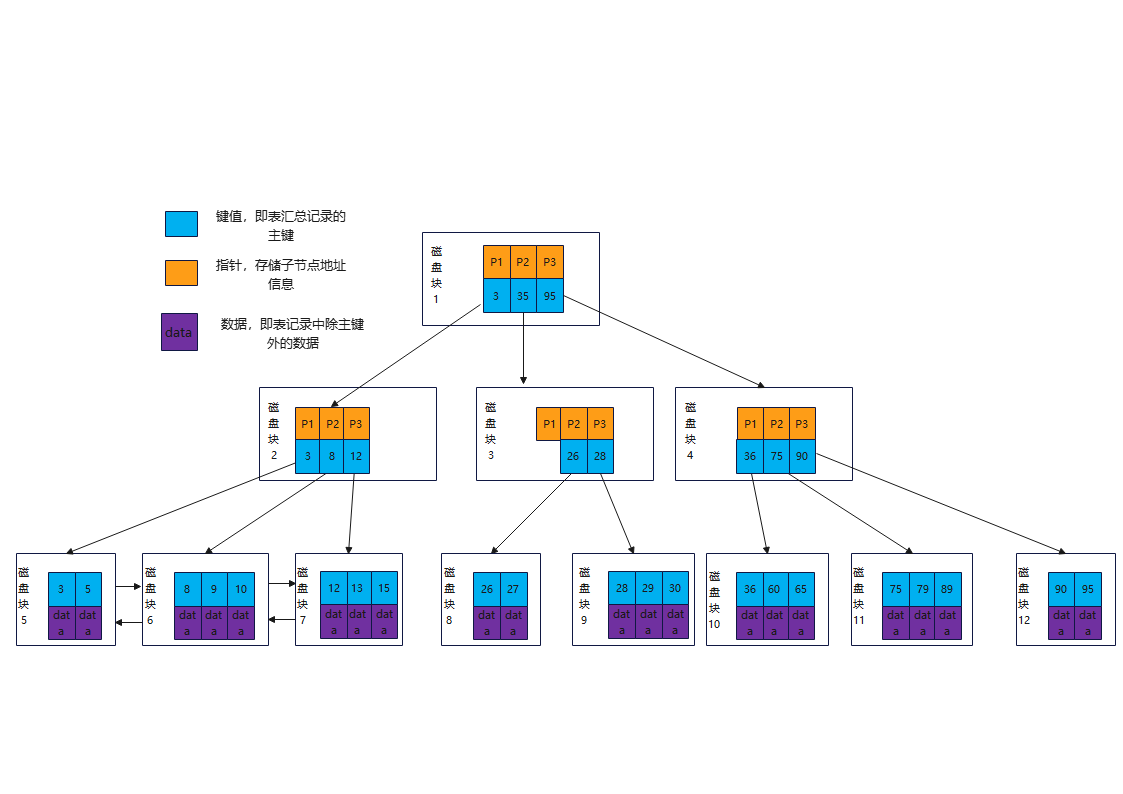
上面那张图所表示的B树就是一棵3阶的B树,我们可以看下磁盘块2,里面的关键字为(8,12),它有3个孩子(3,5),(9,10),(13,15),你能看到(3,5)小于8,(9,10)在8和12之间,而(13,15)大于12,刚好符合刚才我们给出的特征。
然后我们来看下如何用B树进行查找,假设我们想要查找的关键字是9,那么步骤可以分为以下几步: - 我们与根节点的关键字(17,35)进行比较,9小于17 那么得到指针P1;
- 按照指针P1找到磁盘块2,关键字为(8,12),因为9在8和12之间,所以我们得到指针P2;
- 按照指针P2找到磁盘块6,关键字为(9,10),然后我们找到了关键字9。

你能看出来在B树的搜索过程中,我们比较的次数并不少,但如果把数据读取出来然后再内存中进行比较,这个时间就是可以忽略不计的。而读取磁盘块本身需要进行I/O操作,消耗的时间比在内存中进行比较所需要的时间要多,是数据查找用时的重要因素。B树相比于平衡二叉树来说磁盘I/O操作要少,在数据查询中比平衡二叉树效率要高。所以只要树的高度足够低,IO次数足够少,就可以提高查询性能。
小结
- B树在插入和删除节点的时候如果导致树不平衡,就通过自动调整节点的位置来保存树的自平衡。
- 关键字集合分布在整棵树中,即叶子节点和非叶子节点都存放数据。搜索有可能在非叶子节点结束
- 其搜索性能等价于在关键字全集内做一次二分查找。
B+树
B+树也是一种多路搜索树,基于B树做出了改进,主流的DBMS都支持B+树的索引方式,比如MySQL,相比于B-Tree,B+Tree适合文件索引系统。
B+树和B树的差异在于以下几点:
- 有k个孩子的节点就有k个关键字,也就是孩子数量=关键字数,而B树中,孩子数量=关键字+1,
- 非叶子节点的关键字也会同时存在在子节点中,并且是在子节点中所有关键字的最大(或最小)。
- 非叶子节点仅用于索引,不保存数据记录,跟记录有关的信息都放在叶子节点中。而B树中,非叶子节点既保存索引,也保存数据记录。
- 所有关键字都在叶子节点出现,叶子节点构成一个有序链表,而且叶子节点本身按照关键字的大小从小到大顺序链接。
下图就是一棵B+树,阶数为3,根节点中的关键字1、18、35分别是子节点(1,8,14),(18,24,31) 和(35,41,53)中的最小值。每一层父节点的关键字都会出现在下一层的子节点的关键字中,因此在叶子节点中包括了所有的关键字信息,并且每一个叶子节点都有一个指向下一个节点的指针,这样就形成了一个链表。
B+树相对B树有如下优点:
- B+树查询效率更稳定。 因为B+树每次只有访问到叶子节点才能找到对应的数据,而B树中,非叶子节点也会存储数据,这样就会造成查询效率不稳定的情况,有时候访问到了非叶子节点就可以找到关键字,而有时候需要访问到叶子节点才能找到关键字。
- B+树的查询效率更高, 这是因为通常B+树比B树更矮胖(阶数更大,深度更低),查询所需的磁盘I/O也会更小,同样的磁盘页大小,B+树可以存储更多的关键字。
- 在查询范围上,B+树的效率也比B树高,这是因为所有关键字都出现在B+树的叶子节点中,叶子节点之间会有指针,数据又是递增的,这使得我们范围查找可以通过指针连接查找。而在B树中则需要通过中序遍历才能完成查询范围的查找,效率要低很多。
思考题
1. B+树的存储能力如何?为何说一般查找行记录,最多只需1~3次磁盘IO
InnoDB存储引擎的页大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的k取值10^3,
也就是说一个深度为3的B+Tree索引可以维护 :10^3 *10^3 *10^3=10亿条记录。)
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的 ,也就是说查找某一键值的行记录是最多只需要1~3次磁盘I/O操作。
2. 为什么说B+树比B树更适合实际应用中操作系统的文件索引和数据库索引?
- B+树的磁盘读写代价更低
B+树的内部节点并没有指向关键字具体信息的指针。因此其内部节点相对B树更小,如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多,一次性读入内存中的需要查找的关键字也就越多,相对来说IO读写次数也就降低了。 - B+树的查询效率更稳定
因为B+树每次只有访问到叶子节点才能找到对应的数据,而B树中,非叶子节点也会存储数据,这样就会造成查询效率不稳定的情况,有时候访问到了非叶子节点就可以找到关键字,而有时候需要访问到叶子节点才能找到关键字。
Hash索引与B+树索引的区别
Hash索引结构和B+树的不同,因此在索引使用上也会有差别。
- Hash索引不能进行范围查询,而B+树可以。这是因为Hash索引指向的数据是无序的,而B+树的叶子节点是一个有序的链表。
- Hash索引不支持联合索引的最左侧原则(即联合索引的部分索引无法使用),而B+树可以。对于联合索引来说,Hash索引在计算Hash值的时候将索引键合并后再一起计算Hash值,所以不会针对每个索引单独计算Hash值,因此如果用到联合索引的一个或者几个索引时,联合索引无法被利用。
- Hash索引不支持ORDER BY 排序,因为Hash索引指向的数据是无序的,因为无法起排序优化的作用,而B+树索引是有序的,可以起到对该字段ORDER BY排序优化的作用,同理,我们无法用Hash索引进行模糊查询,而B+树使用LIKE进行模糊查询的时候,LIKE后面模糊查询(比如%结尾)的话即可。
Hash索引与B+树索引是在建索引的时候手动指定的么?
针对InnoDB和MyISAM存储引擎,都会默认采用B+树索引,无法使用Hash索引,InnoDB提供的自适应Hash是不需要手动指定的。如果是Memory/Heap和NDB存储引擎,是可以选择Hash索引的。
总结
文章来源: feige.blog.csdn.net,作者:码农飞哥,版权归原作者所有,如需转载,请联系作者。
原文链接:feige.blog.csdn.net/article/details/126214320

- 点赞
- 收藏
- 关注作者
评论(0)