大数据Apache Druid(七):Druid数据的全量更新

【摘要】 Druid数据的全量更新Druid中不支持对指定的数据进行更新,只支持对数据进行全量替换,全量替换的粒度是以Segment为标准。举例说明如下:现在在Druid中Datasoure “mydruid_testdata”中目前的数据如下:SELECT __time, "count", item, loc, sum_amount, uidFROM mydruid_testdata我...
Druid数据的全量更新
Druid中不支持对指定的数据进行更新,只支持对数据进行全量替换,全量替换的粒度是以Segment为标准。举例说明如下:
现在在Druid中Datasoure “mydruid_testdata”中目前的数据如下:
SELECT
__time,
"count",
item,
loc,
sum_amount,
uid
FROM mydruid_testdata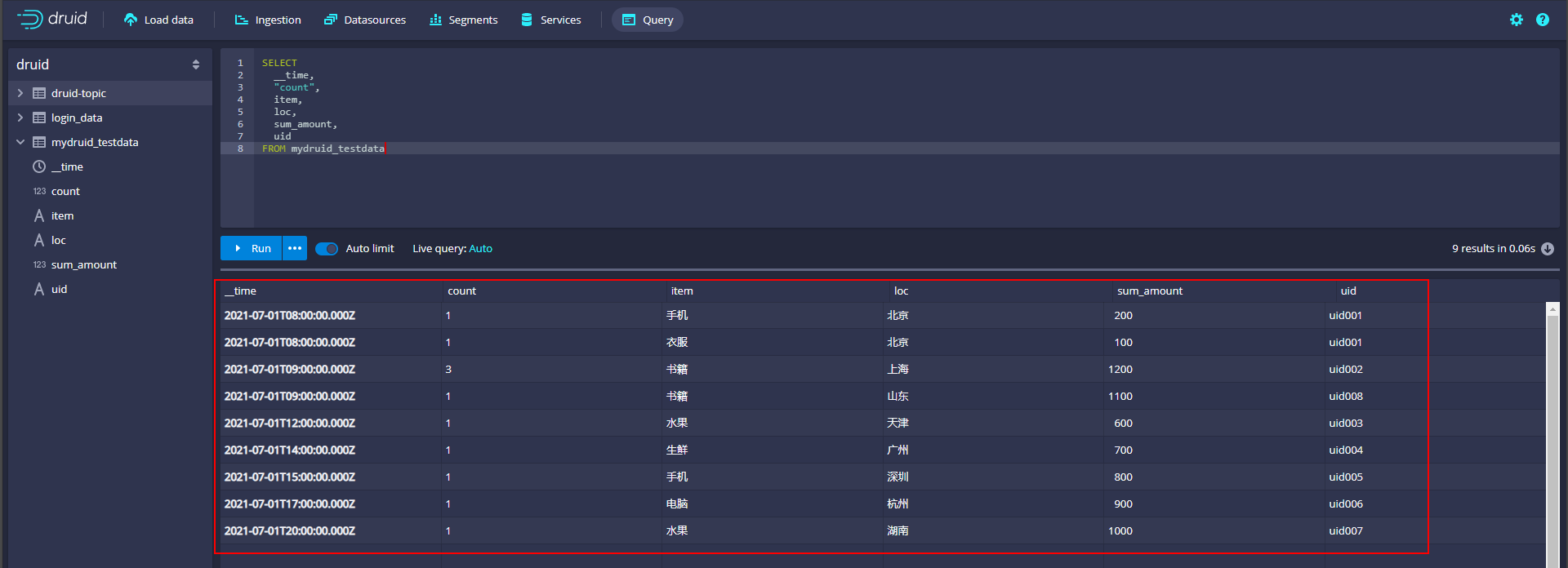
我们可以在Druid webui中查看当前Datasource 对应的Segment信息,其对应的Segement在HDFS中的信息如下:

我们想要替换Datasouse “mydruid_testdata”中的数据,替换的粒度就是以segment为基准,假设我们需要替换当前“20210701T000000.000Z_20210702T000000.000Z”segment信息,我们只需要准备对应时间段内的数据,重新像导入数据一样,导入到当前名为“mydruid_testdata”的Datasource中即可,准备的对应时间段的新数据如下:
{"data_dt":"2021-07-01T08:13:23.000Z","uid":"uid001","loc":"深圳","item":"家具","amount":"10"}
{"data_dt":"2021-07-01T08:20:13.000Z","uid":"uid001","loc":"深圳","item":"家电","amount":"11"}
{"data_dt":"2021-07-01T09:24:46.000Z","uid":"uid002","loc":"西安","item":"生鲜","amount":"12"}
{"data_dt":"2021-07-01T09:43:42.000Z","uid":"uid002","loc":"西安","item":"家具","amount":"13"}
{"data_dt":"2021-07-01T09:53:42.000Z","uid":"uid003","loc":"海南","item":"生鲜","amount":"14"}以上数据与目前Druid当前Datasource中此Segment的数据完全不一样,然后,我们将对应的数据上传到node3、node4、node5某个新路径下,在Druid webui 页面上选择“Load Data”以加载磁盘数据方式将数据加载到“mydruid_testdata”中,这里截图只是部分截图:


提交任务后,稍等片刻,在“Segment”标签下找到“mydruid_testdata”Datasource,可以最终看到指定的时间范围“20210701T000000.000Z~20210702T000000.000Z”内,只有一个最后提交的Segment片段信息(开始可能会有2个,等一会只剩最新提交的一个Segment)。

并且,查询Datasource“mydruid_testdata”数据结果也是最终新导入数据的结果:
SELECT
__time,
"count",
item,
loc,
sum_amount,
uid
FROM mydruid_testdata

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)