【CANN训练营】CANN昇腾体验官2022第二季第五期 轻松应对5道题(不轻松)

1、跑通样例
为避免原先的sample有冲突,
cd ~
mv samples/ samples_bak/
git clone https://gitee.com/ascend/samples.git
- 1
- 2
- 3
参考
https://gitee.com/ascend/samples/tree/master/cplusplus/level3_application/1_cv/detect_and_classify#模型及数据准备
# 进入目标识别样例工程根目录
cd $HOME/samples/cplusplus/level3_application/1_cv/detect_and_classify
# 创建并进入model目录
mkdir model
cd model
# 下载yolov3的原始模型文件及AIPP配置文件
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/yolov3_t.onnx
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp_onnx.cfg
# 执行模型转换命令,生成yolov3的适配昇腾AI处理器的离线模型文件
atc --model=./yolov3_t.onnx --framework=5 --output=yolov3 --input_shape="images:1,3,416,416;img_info:1,4" --soc_version=Ascend310 --input_fp16_nodes="img_info" --insert_op_conf=aipp_onnx.cfg
# 下载color模型的原始模型文件及AIPP配置文件
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/color.pb
wget https://obs-9be7.obs.cn-east-2.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp.cfg
# 执行模型转换命令,生成color的适配昇腾AI处理器的离线模型文件
atc --input_shape="input_1:-1,224,224,3" --output=./color_dynamic_batch --soc_version=Ascend310 --framework=3 --model=./color.pb --insert_op_conf=./aipp.cfg --dynamic_batch_size="1,2,4,8"
vi scripts/params.conf

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
配置为单路,
cd scripts
bash sample_build.sh
cd ../out
./main
- 1
- 2
- 3
- 4
- 5

data里面有3个文件
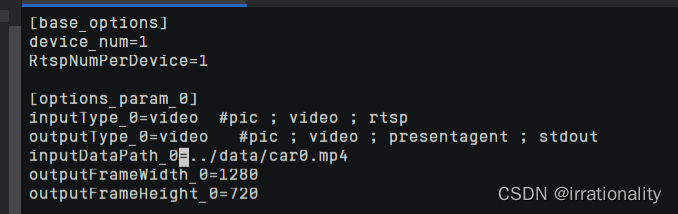
param.conf里面也是只处理一个视频
输入输出都要求为图片
那我们更改一下
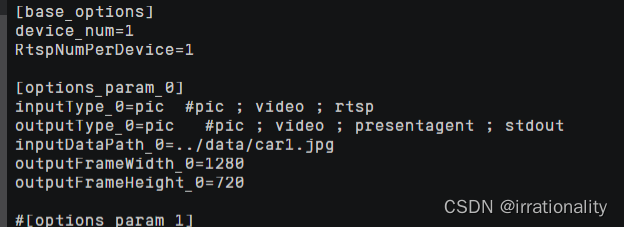
再次运行即可
2、将输入数据从 jpeg 压缩图变为png
参考https://gitee.com/ascend/samples/tree/master/cplusplus/level3_application/1_cv/detect_and_classify#%E5%9B%BE%E7%89%87
修改车辆检测模型的预处理代码(涉及代码文件:
detect_and_classify/src/detectPreprocess/detectPreprocess.cpp)。
a. 打开图片文件夹的接口可直接复用样例代码,无需修改。
b. 修改读取图片的接口“DetectPreprocessThread::ReadPic”,将其中读取 JPEG
压缩图片的接口更改为读取 PNG 压缩图片的接口。
c. 修改图片解码接口“DetectPreprocessThread::ProcessPic”,将其中的 JPEG 解
码接口更改为 PNG 解码接口。
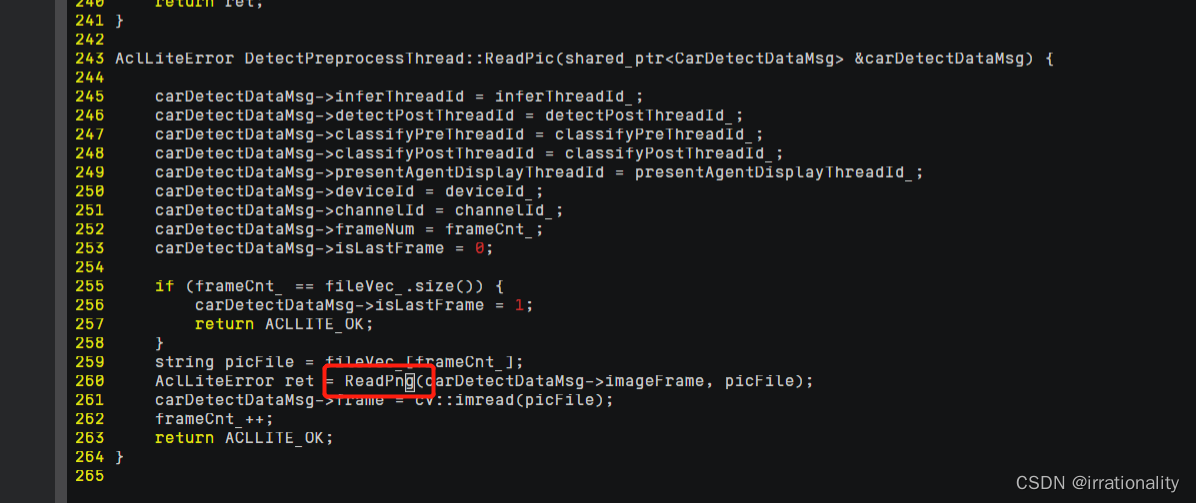
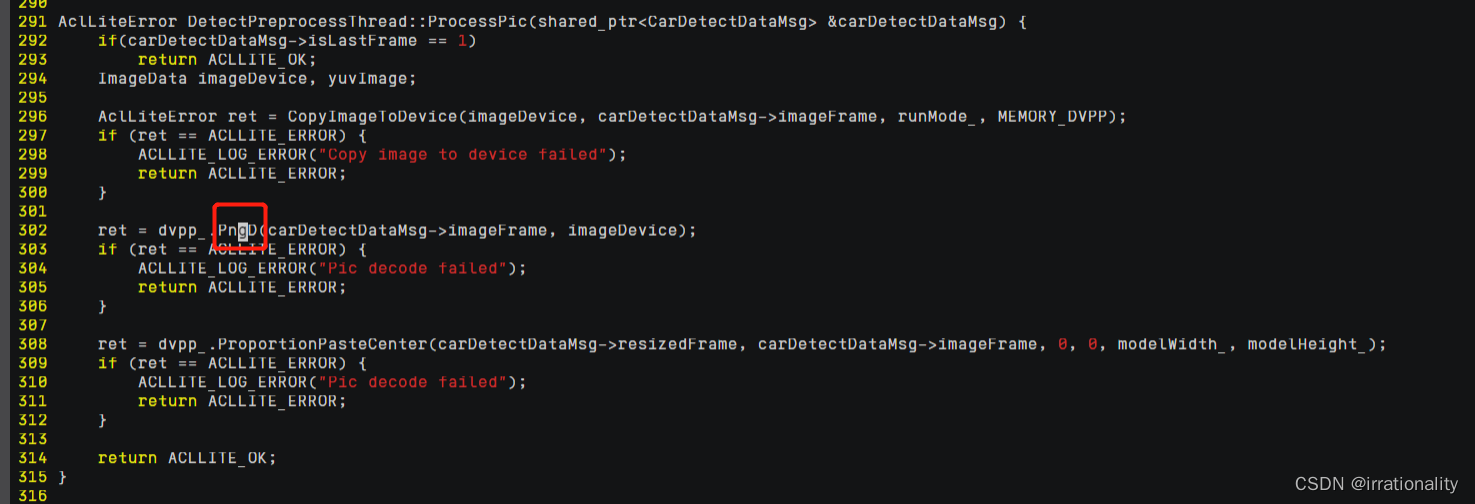
- 重新编译运行样例。
3、将JPEG解码后格式指定为YUV420SP NV21
-
将 JPEGD 解码功能相关代码中的输出格式由 YUV420SP NV12 修改为 YUV420SP
NV21。
AscendCL 中 DVPP 的图片数据格式配置可参见 acldvppPixelFormat。涉及代码文件:acllite/src/JpegDHelper.cpp
-
将图片缩放功能相关代码中的数据格式由 YUV420SP NV12 修改为 YUV420SP
NV21。
由于车辆检测模型与颜色分类模型都涉及到图片缩放功能,原样例中的缩放是基
于 YUV420SP NV12 格式的数据进行操作,所以数据格式变更后,这部分代码需
同步修改。
涉及代码文件:acllite/src/ResizeHelper.cpp -
将抠图功能相关代码中的数据格式由 YUV420SP NV12 修改为 YUV420SP NV21。
由于颜色分类模型还涉及到抠图操作,原样例中的抠图功能是基于 YUV420SP
NV12 格式的数据进行操作,所以数据格式变更后,这部分代码需同步修改。
涉及代码文件:acllite/src/CropAndPasteHelper.cpp以上提到的三个文件:
acllite/src/JpegDHelper.cpp
acllite/src/ResizeHelper.cpp
acllite/src/CropAndPasteHelper.cpp
这三个
路径在samples/cplusplus/common/acllite
将acllitee中
PIXEL_FORMAT_YUV_SEMIPLANAR_420
改为
PIXEL_FORMAT_YVU_SEMIPLANAR_420cd ${HOME}/samples/cplusplus/common/acllite make make install- 1
- 2
- 3
- 4
-
定制车辆检测模型与颜色分类模型的 AIPP 配置文件,将输入数据格式由
YUV420SP NV12 修改为 YUV420SP NV21,并重新进行模型转换。
AIPP 配置可参见:AIPP 配置参考。
# 进入目标识别样例工程根目录
cd ${HOME}/samples/cplusplus/level3_application/1_cv/detect_and_classify
# 创建并进入model目录
cd model
# 下载yolov3的原始模型文件及AIPP配置文件
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/yolov3_t.onnx
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp_onnx.cfg
# 下载color模型的原始模型文件及AIPP配置文件
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/color.pb
wget https://modelzoo-train-atc.obs.cn-north-4.myhuaweicloud.com/003_Atc_Models/AE/ATC%20Model/YOLOV3_carColor_sample/data/aipp.cfg
修改如下文件
model/aipp.cfg
model/aipp_onnx.cfg
修改内容:
rbuv_swap_switch : true
# 执行模型转换命令,生成yolov3的适配昇腾AI处理器的离线模型文件
atc --model=./yolov3_t.onnx --framework=5 --output=yolov3 --input_shape="images:1,3,416,416;img_info:1,4" --soc_version=Ascend310 --input_fp16_nodes="img_info" --insert_op_conf=aipp_onnx.cfg
# 执行模型转换命令,生成color的适配昇腾AI处理器的离线模型文件
atc --input_shape="input_1:-1,224,224,3" --output=./color_dynamic_batch --soc_version=Ascend310 --framework=3 --model=./color.pb --insert_op_conf=./aipp.cfg --dynamic_batch_size="1,2,4,8"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 重新编译 AclLite。
因为步骤 1~步骤 3 会涉及到 AclLite 公共库的代码修改,所以需要重新编译
AclLite 库,编译方法请参见 AclLite 库编译。
说明:ECS 云环境为开发环境与运行环境合设场景。 - 重新编译运行样例。
请参见样例编译运行。
修改conf文件读入为jpeg
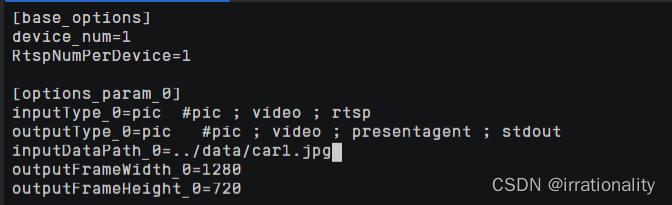
cd ~/samples/cplusplus/level3_application/1_cv/detect_and_classify/scripts
bash sample_build.sh
bash sample_run.sh
- 1
- 2
- 3
- 4
4、静态Batch -> 动态Batch的定制开发
- 进行定制开发前,请先了解动态 Batch 场景下的接口调用流程,及定制流程参考资料:昇腾文档中心中的接口调用流程与动态 Batch。
通用目标检测与识别 README 中的动态 batch 场景定制。
了解了基本流程后,下面按照提示进行静态 Batch->动态 Batch 改造,实现流程提示如下。 - 重新将 TensorFlow框架的颜色分类模型转换为离线 om 模型,设置模型每次处理
的图片数量可以为 1、2、4、8 几种场景。 - 定制颜色分类模型的预处理代码,设置模型推理时的实际 batch 大小,并创建对应
batch 大小的输入数据。
a. 准备动态 Batch 输入的数据结构。
涉及代码文件:acllite/src/AclLiteModel.cpp 定制参考代码片段如下:
void CreateModelInput()
{
aclError ret;
modelDesc_ = aclmdlCreateDesc();
ret = aclmdlGetDesc(modelDesc_, modelId_);
input_ = aclmdlCreateDataset();
for(size_t index = 0; index < aclmdlGetNumInputs(modelDesc_); ++index)
{
// get ACL_DYNAMIC_TENSOR_NAME index
const char* name = aclmdlGetInputNameByIndex(modelDesc_, index);
size_t inputLen = aclmdlGetInputSizeByIndex(modelDesc_, index);
if(strcmp(name, ACL_DYNAMIC_TENSOR_NAME) == 0)
{
void *data = nullptr;
ret = aclrtMalloc(&data, inputLen, ACL_MEM_MALLOC_HUGE_FIRST);
batchBuffer = aclCreateDataBuffer(data, inputLen);
ret = aclmdlAddDatasetBuffer(input_, batchBuffer);
}
else
{
inputBuffer = aclCreateDataBuffer(InputData_index, InputData Size_index);
ret = aclmdlAddDatasetBuffer(input_, inputBuffer);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
b. 每次推理前,设置此次推理 batch 数。
涉及代码文件:acllite/src/AclLiteModel.cpp
int ModelSetDynamicInfo(int batchSize)
{
size_t index;
// get index of dynamic batch in input dataset
aclError ret = aclmdlGetInputIndexByName(modelDesc_,
ACL_DYNAMIC_TENSOR_NAME, &index);
// set index
ret = aclmdlSetDynamicBatchSize(modelId_, input_, index, batchSize);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
涉及代码文件:src/inference/inference.cpp
const int32_t kBatch = 2;
AclLiteError InferenceThread::InitModelInput()
{ ModelSetDynamicInfo(batchSize_);
classifyInputSize_ = YUV420SP_SIZE(kClassifyModelWidth, kClassifyModelHeight) * batchSize_;
void* buf = nullptr;
aclError aclRet = aclrtMalloc(&buf, classifyInputSize_,
ACL_MEM_MALLOC_HUGE_FIRST);
if ((buf == nullptr) || (aclRet != ACL_ERROR_NONE)) {
ACLLITE_LOG_ERROR("Malloc classify inference input buffer failed, "
"error %d", aclRet);
return ACLLITE_ERROR;
}
classifyInputBuf_ = (uint8_t *)buf;
return ACLLITE_OK;
}
或者
const int32_t kBatch = 2;
AclLiteError InferenceThread::InitModelInput()
{
// ModelSetDynamicInfo(batchSize_);
// aclmdlSetDynamicBatchSize(modelId_, input_, index, batchSize);
classifyInputSize_ = YUV420SP_SIZE(kClassifyModelWidth, kClassifyModelHeight) * batchSize_;
void* buf = nullptr;
aclError aclRet = aclrtMalloc(&buf, classifyInputSize_,
ACL_MEM_MALLOC_HUGE_FIRST);
if ((buf == nullptr) || (aclRet != ACL_ERROR_NONE)) {
ACLLITE_LOG_ERROR("Malloc classify inference input buffer failed, "
"error %d", aclRet);
return ACLLITE_ERROR;
}
classifyInputBuf_ = (uint8_t *)buf;
return ACLLITE_OK;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 重新编译 AclLite。
因为步骤 2 会涉及到 AclLite 公共库的代码修改,所以需要重新编译 AclLite 库, 编译方法请参见 AclLite 库编译。
说明:ECS 云环境为开发环境与运行环境合设场景。
cd ${HOME}/samples/cplusplus/common/acllite
make
make install
- 1
- 2
- 3
- 4
- 重新编译运行样例。 请参见样例编译运行。
cd ~/samples/cplusplus/level3_application/1_cv/detect_and_classify/scripts
bash sample_build.sh
bash sample_run.sh
- 1
- 2
- 3
- 4
这样就完成了多batch
5、AI应用自主开发
那我们话不多说,搞一个人脸识别的模型。
首先老规矩,再次clone一下代码仓。
先做个备注:
- PB
这种 PB 文件是表示 MetaGraph 的 protocol buffer格式的文件,MetaGraph 包括计算图,数据流,以及相关的变量和输入输出signature以及 asserts 指创建计算图时额外的文件。
简而言之,pb是tf模型的一种固化形式,相当于一种模型保存与加载的方式。
ONNX简介
ONNX是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的人工智能框架(如Pytorch, MXNet)可以采用相同格式存储模型数据并交互。 ONNX的规范及代码主要由微软,亚马逊 ,Facebook 和 IBM 等公司共同开发,以开放源代码的方式托管在Github上。目前官方支持加载ONNX模型并进行推理的深度学习框架有: Caffe2, PyTorch, MXNet,ML.NET,TensorRT 和 Microsoft CNTK,并且 TensorFlow 也非官方的支持ONNX。—维基百科
ONNX全称是Open Neural Network Exchange,不同深度学习框架可以将模型保存为ONNX格式,从而实现模型在不同框架之间的转换。
ONNX中,每一个计算流图都定义为由节点组成的列表,每个节点是一个OP,可能有一个或多个输入与输出,并由这些节点构建有向无环图。
目前,ONNX已支持当前主要的各种深度学习框架,有些框架如PyTorch是官方集成了ONNX,有些需要第三方支持,即便像darknet这种小众的框架,也可以手动构建ONNX图来将模型转为ONNX格式。
我们可以使用pip或在conda环境中使用conda来获取ONNX,具体参见ONNX的github。
- ONNX
ONNX是一个开放式规范,由以下组件组成:
可扩展计算图模型
一系列内置运算单元(OP)
标准数据类型
将一个模型转为ONNX格式,主要是构造计算流图,在官方github的example目录下有很多使用示例,这里列举出最常用的几个方法。
在ONNX中,数据的存储使用的是Google的Protobuf序列化框架,数据结构主要有以下六种,定义在onnx/onnx.in.proto文件内:
TensorProto
ValueInfoProto
AttributeProto
NodeProto
ModelProto
GraphProto
原来是[1,300,300,3] 我们进行缩放操作到 224 224
atc --model=./frozen_inference_graph.pb --input_shape="image_tensor:1,300,300,3" --output=./ssd_ascend_onnx --soc_version=Ascend310 --framework=3 --insert_op_conf=./aipp_onnx.cfg
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
转换成功后,结果还是运行报错。无可奈何。
提了一个issue。
就此作罢。
https://gitee.com/ascend/modelzoo/wikis/%E5%A6%82%E4%BD%95%E8%8E%B7%E5%8F%96%E6%97%A5%E5%BF%97%E5%92%8C%E8%AE%A1%E7%AE%97%E5%9B%BE?sort_id=4097825
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/126435952

- 点赞
- 收藏
- 关注作者
评论(0)