经典算法---顺序查找

【摘要】 查找也被称为检索,算法的主要目的是在某种数据结构中找出满足给定条件的元素(以等值匹配为例)。如果找到满足条件的元素则代表查找成功,否咋查找失败。
在进行查找时,对于不同的数据结构以及元素集合状态,会有相对匹配的算法,在使用时也需要注意算法的前置条件。在元素查找相关文章中只讨论数据元素只有一个数据项的情况,即关键字就是对应数据元素的值,对应到具体的数据结构,可以理解为一维数组。
元素查找介绍
查找也被称为检索,算法的主要目的是在某种数据结构中找出满足给定条件的元素(以等值匹配为例)。如果找到满足条件的元素则代表查找成功,否咋查找失败。
在进行查找时,对于不同的数据结构以及元素集合状态,会有相对匹配的算法,在使用时也需要注意算法的前置条件。在元素查找相关文章中只讨论数据元素只有一个数据项的情况,即关键字就是对应数据元素的值,对应到具体的数据结构,可以理解为一维数组。
-
顺序查找
也称为线性查找,是最简单的查找方法。思路也很简单,从数组的一边开始,逐个进行元素的比较,如果与给定的待查找元素相同,则查找成功,如果整个扫描结束后,仍未找到相匹配的元素,则查找失败。 -
折半查找
也称为二分查找,是一种效率相对较高的查找方法。使用该算法的前提要求是,元素已经有序,因为算法的核心思想是尽快的缩小搜索区间,这就需要保证在缩小范围的同时,不能有元素的遗漏。 -
索引查找
索引查找主要分为基本索引查找和分块查找,核心思想是对于无序的数据集合,先建立索引表,使得索引表有序或分块有序,结合顺序查找与索引查找的方法,完成查找。
顺序查找
-
输入
n个数的序列,通常直接存放在数组中,可以是任何顺序。
待查找元素key -
输出
查找成功:返回元素所在位置的编号
查找失败:返回-1或自定义失败标识 -
算法说明
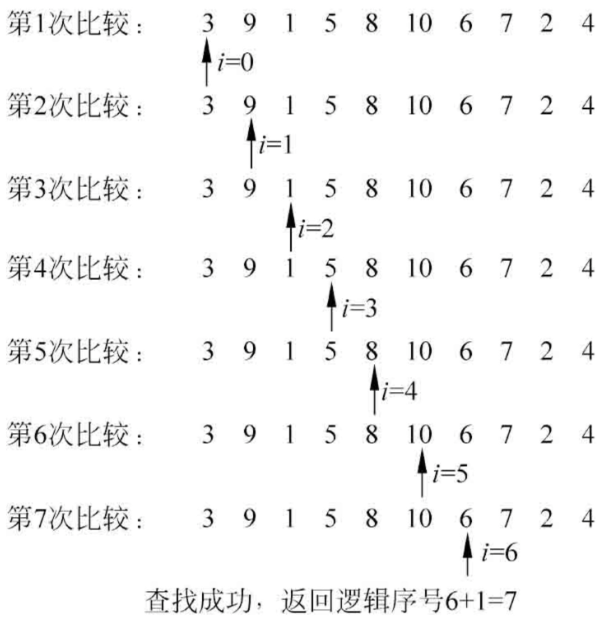
算法执行的过程简单粗暴,就是从数组的一端开始逐个扫描,挨个元素进行比较,直到找到元素位置,或将所有元素扫描一遍。 -
算法流程

i为控制索引下标的变量,从第一个元素开始,不断向后移动
每次将集合中对应位置的元素取出,与待查找元素key进行比较,如果相等则返回逻辑序号
如果整个集合扫描完成,还没有找到,则认为查找失败
伪代码
顺序查找直接使用循环结构进行集合的遍历,每次取到的元素与key进行比较,如果相等则循环提前结束。伪代码表示如下:
i=1
while i<=A.length
if A[i] == key
return i
i++
return -1

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)