现代 ABAP 编程语言中的正则表达式

在这篇博文中,我想分享现代 ABAP 中正则表达式的最新消息和变化,主要来自 OP 版本 7.55 和 7.56。
以前,在 ABAP 中使用 POSIX 样式的正则表达式或“uniX 的便携式操作系统接口- POSIX 的全称是 Portable Operating System Interface for uniX”。 因此,从现在开始,POSIX 语法中的正则表达式已过时,然后使用这种正则表达式语法会导致语法检查警告。 虽然这可以被 pragma ##regex_posix 隐藏,但强烈建议迁移到 ABAP 支持的其他正则表达式语法,如 PCRE 正则表达式、XPath 正则表达式或 XSD 正则表达式。
ABAP 正则表达式的回顾
正则表达式对于新用户来说通常是复杂和令人生畏的。 在深入研究新功能之前,我想简要介绍一下 RegEx,并展示用 ABAP 明确编写的示例。 如果您是该主题的专家并且可能会感到无聊,请随时跳过此部分。
RegEx 的概念已经存在了很长一段时间。当需要复杂的模式时使用它。 如搜索数字、字母、特殊字符或验证电子邮件等。许多文本搜索和替换问题在不使用正则表达式模式匹配的情况下很难处理。 此外,在 ABAP 中,使用正则表达式的搜索比传统的 SAP 模式更强大。让我们以这个简单的例子为例:
FIND 'A' IN 'ABCD1234EFG'
MATCH COUNT sy-tabix.
WRITE: sy-tabix.
现在,如果您想在不使用 RegEx 的情况下通过正常搜索模式查找字符串中的所有字母,则需要对所有 26 个字符进行循环。 使用 RegEx,可以很容易地搜索和找到所有七个字符:
FIND ALL OCCURRENCES OF PCRE '[A-Z]' IN 'ABCD1234EFG'
MATCH COUNT sy-tabix.
WRITE: sy-tabix.
ABAP 在语句 FIND 和 REPLACE 中以及通过类 CL_ABAP_REGEX 和 CL_ABAP_MATCHER 支持正则表达式。 CL_ABAP_MATCHER 类将使用 CL_ABAP_REGEX 生成的正则表达式应用于字符串或内部表。
Greedy or Lazy?
另一个可能有趣的概念是 RegEx 中贪婪或惰性量词的含义。 在用 (,+,…) 定义的贪婪模式中,量化字符被重复尽可能多的次数。 RegEx 引擎将尽可能多的字符添加到匹配中,然后一个一个地缩短,以防模式的其余部分不匹配。 它的反面将被称为懒惰模式,它匹配尽可能少的字符。 例如,在 ABAP 中,通过在 * , (.?) 后面放置一个问号,您要求子表达式匹配尽可能少的字符。 正则表达式的默认行为是贪婪的(实际上 POSIX 意味着无法关闭的贪婪量词)。
例子:
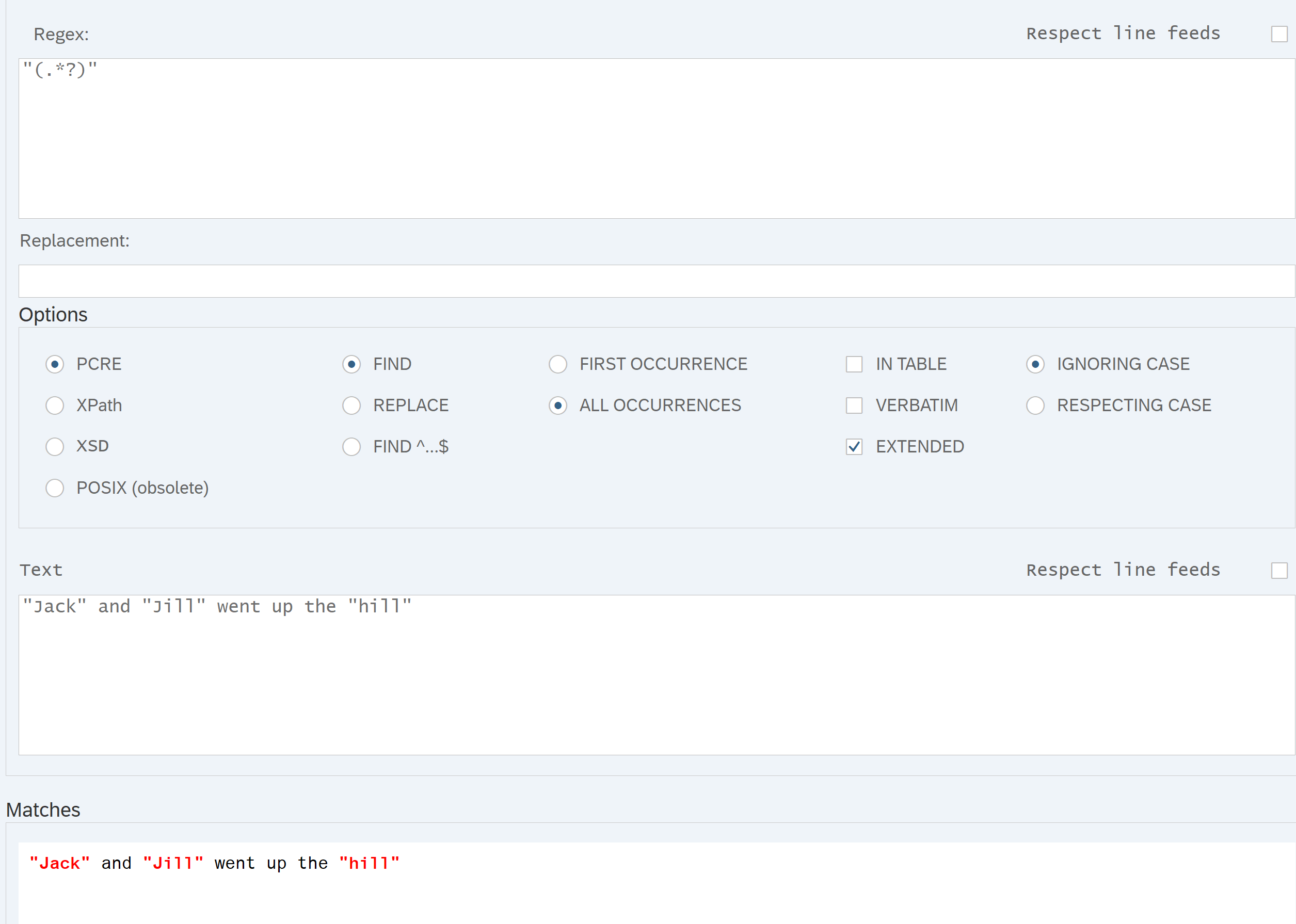
DATA(text) = `"Jack" and "Jill" went up the "hill"`.
FIND ALL OCCURRENCES OF PCRE `"(.*?)"` IN text IGNORING CASE
RESULTS DATA(result_tab).
IF sy-subrc = 0.
LOOP AT result_tab ASSIGNING FIELD-SYMBOL(<result>).
cl_demo_output=>write( substring( val = text off = <result>-offset len = <result>-length ) ).
ENDLOOP.
ENDIF.
cl_demo_output=>display( ).
贪婪符号“(.)”将整个输入句子作为输出,而懒惰符号“(.?)”给出三个单词“Jack”、“Jill”、“hill”。 如果在懒惰的情况下省略表达式“ALL OCCURRENCES OF”,则只会找到第一个“和后面的”之间的子字符串,即“Jack”。
直到 7.55 版本,ABAP 仅将 POSIX 库用于 RegEx。 从那时起,也支持 Perl 库。 两个库在计算匹配的方式上有很大不同。 由于 POSIX 已经过时,我们将在下文中使用 Perl 风格的正则表达式。 您可以通过在 AS ABAP 中运行报表 DEMO_REGEX 来尝试使用 Regex 来尝试不同的表达式。
PCRE Syntax
PCRE 库是一组用 C 语言编写的函数,它们使用与 Perl 5 相同的语法和语义实现正则表达式模式匹配,并拥有自己的原生 API。 PCRE 语法代表“Perl Compatible Regular Expressions”,比 POSIX 语法或许多其他正则表达式库更强大、更灵活,并且比 ABAP 支持的 POSIX 正则表达式性能更好。
具有 PCRE 语法的 RegEx 可以在 FIND 和 REPLACE 语句的添加 PCRE 和字符串的内置函数的参数 PCRE 之后指定。 PCRE 正则表达式的对象可以使用系统类 CL_ABAP_REGEX 的工厂方法 CREATE_PCRE 创建,用于语句 FIND 和 REPLACE 或使用系统类 CL_ABAP_MATCHER。
例子:
DATA(text) = `oooababboo`.
FIND PCRE 'a.|[ab]+|b.*' IN text
MATCH OFFSET DATA(moff)
MATCH LENGTH DATA(mlen).
IF sy-subrc = 0.
cl_demo_output=>write( substring( val = text off = moff len = mlen ) ).
ENDIF.
搜索使用 PCRE 正则表达式语法并从偏移量 3 中找到长度为 2 的“ab”。但是,使用加法 REGEX 而不是 PCRE,搜索会从偏移量 3 或更高的长度为 5 中找到子字符串“abbabb”。
Callouts in PCRE Regular Expressions
通过RegEx callouts,可以在正则表达式模式匹配过程中临时将控制权交给函数。 PCRE 标注使用语法 (?C…) 指定,其中点代表可选参数。如果你在调用 PCRE 的匹配函数之前指定一个 callout 函数,每当引擎运行到 (?C…) 时,它会暂时挂起匹配并将控制权传递给那个 callout 函数,它提供有关匹配的信息。然后调用函数执行它应该做的任何任务,然后它向引擎返回一个代码,让它知道是否正常进行剩下的比赛。
在 ABAP 中,PCRE 语法支持在将正则表达式与 CL_ABAP_MATCHER 匹配期间调用 ABAP 方法的标注。当执行方法 MATCH 时,PCRE 正则表达式的特殊字符 (?C…) 然后调用接口方法 CALLOUT。该示例演示了如何从 PCRE 正则表达式调用 ABAP 方法。
REPORT demo_pcre_callout.
CLASS handle_regex DEFINITION.
PUBLIC SECTION.
INTERFACES if_abap_matcher_callout.
ENDCLASS.
CLASS handle_regex IMPLEMENTATION.
METHOD if_abap_matcher_callout~callout.
cl_demo_output=>write( |{ callout_num } { callout_string }| ).
ENDMETHOD.
ENDCLASS.
CLASS demo_pcre DEFINITION.
PUBLIC SECTION.
CLASS-METHODS main.
ENDCLASS.
CLASS demo_pcre IMPLEMENTATION.
METHOD main.
DATA(regex) = cl_abap_regex=>create_pcre(
pattern = `a(?C1)b(?C2)c(?C3)d(?C"D")e(?C"E")` ).
DATA(matcher) = regex->create_matcher( text = `abcde` ).
DATA(handler) = NEW handle_regex( ).
matcher->set_callout( handler ).
matcher->match( ).
cl_demo_output=>display( ).
ENDMETHOD.
ENDCLASS.
START-OF-SELECTION.
demo_pcre=>main( ).
正则表达式包含用于标注的特殊字符 (?C…)。 前三个标注传递数字数据,其他两个传递字符串数据。
本地类“handle_regex”实现接口 IF_ABAP_MATCHER_CALLOUT 并且该类的实例被设置为标注处理程序。 当正则表达式匹配到时,每个callout位置都会调用接口方法CALLOUT,可以访问传入的参数。
PCRE syntax for ABAP SQL and ABAP CDS
ABAP SQL 和 ABAP CDS 还通过内置函数 REPLACE_REGEXPR、LIKE_REGEXPR 和 OCCURRENCES_REGEXPR 支持 PCRE 语法。 这些函数访问在 SAP HANA 数据库中实现的 PCRE1 库。 一般 ABAP 的正则表达式与 ABAP 内核中实现的 PCRE2 库一起使用。
CDS View Entity
此 SQL 函数在字符串中搜索正则表达式模式,并返回该字符串,其中包含使用 CDS 视图实体中的替换字符串替换的正则表达式模式的一次或每次出现。
REPLACE_REGEXPR(PCRE => pcre,
VALUE => arg1,
WITH => arg2,
RESULT_LENGTH => res[,
OCCURRENCE => occ][,
CASE_SENSITIVE => case][,
SINGLE_LINE => bool][,
MULTI_LINE => bool][,
UNGREEDY => bool])
以下 CDS 视图实体将 SELECT 列表中的字符串的内置 SQL 函数应用于 DDIC 数据库表 SPFLI 的列,以使用转换值替换 MI 到 KM 的距离 id。
@AccessControl.authorizationCheck: #NOT_REQUIRED
define view entity ZI_regex_test
as select from spfli
{
concat_with_space( cityfrom, cityto, 4 ) as from_City_to,
distance as Distance,
distid as DistanceId,
case
when distid = 'MI' then
replace_regexpr( pcre => '[^<]+',
value => distid,
with => '1.6 KM',
result_length => 6 )
else 'KM'
end as DistanceIdInKM
}
SQL Expressions
ABAP SQL 现在支持一些新的正则处理功能。
本示例从 spfli 表中选择来自柏林或东京的航班,并将它们放在 lt_table 中。
SELECT * FROM spfli
WHERE
like_regexpr( pcre = '\bBERLIN\b|\bTOKYO\b', value = cityfrom ) = '1'
INTO @ls_table.
APPEND ls_table TO lt_table.
ENDSELECT.
以下示例使用正则表达式替换从东京到 Neapel 的航班的目的地“罗马”。
SELECT
carrid as Airline,
connid as flightNo,
deptime as Departure_time,
cityfrom as Departure,
replace_regexpr( pcre = '\bROME\b', value = cityto , with = 'Neapel' ) as Destination
from spfli where cityfrom = 'TOKYO'
into TABLE @data(lt_replace) .
并非所有可以为 ABAP CDS 视图实体(例如 UNGREEDY)中的 REPLACE_REGEXPR 函数指定的参数也可以为 ABAP SQL 指定。 此功能可以通过 PCRE 语法本身来实现。
Xpath and XSD Syntax
功能丰富的 PCRE 正则表达式几乎可以在所有情况下使用。然而,Perl 使用的正则表达式查询并不能很好地将 XML/HTML 分解成有意义的部分并轻松解析它们。为了解决这个难题,ABAP 还支持 Xpath & XSD 正则表达式,并在内部将其转换为 PCRE 语法。
XPath 代表“XML 路径语言”,是一种用于指定 XML 文档部分的表达式语言。 XPath 也可用于结构类似于 XML 的文档,如 HTML。 XPath 语法中的正则表达式可以在正常和扩展模式下编译。在扩展模式下,模式的大多数未转义空格(空格和换行符)在字符类之外被忽略,注释可以放在 # 后面。在ABAP内置函数中,扩展模式默认开启,可以通过正则表达式中的(?-x)关闭。
与正则表达式不同,我们在使用 XPath 时不需要提前知道数据的模式。由于 XML 文档是使用节点结构化的,XPath 使用该结构来浏览节点以返回包含我们正在寻找的节点的对象。
例子:XPath 正则表达式的一个特殊功能是字符集的减法。 在以下示例中,从字符集 BasicLatin 中减去字母 a 到 c,第一个匹配项是偏移量为 3 的 d。
FIND REGEX
cl_abap_regex=>create_xpath2( pattern = '[\p{IsBasicLatin}-[a-c]]' )
IN 'abcd' MATCH OFFSET DATA(moff).
与 PCRE 相比,XPath 正则表达式允许转义字符 \ 而不仅仅是在特殊字符前面。 在以下示例中,带有参数 xpath 的 match 函数会找到 x,而带有参数 pcre 的 match 函数则不会。 因此,第一个 FIND 语句在 sy-subrc 中返回值 0,而第二个 FIND 语句返回 4。
DATA(x) = match( val = `abxcd` xpath = `\x` occ = 1 ).
DATA(y) = match( val = `abxcd` pcre = `\x` occ = 1 ).
FIND REGEX cl_abap_regex=>create_xpath2( pattern = '\x' ) IN 'abxcd'.
FIND REGEX cl_abap_regex=>create_pcre( pattern = '\x' ) IN 'abxcd'.
XSD Syntax
XSD 代表“Xml Schema Definition”,是 XPath 语法的一个子集。与其他正则表达式相比,XML 模式风格有自己的正则表达式语法和专用符号,但功能非常有限。此功能不足不会成为障碍,因为 XSD 仅用于验证整个元素是否与模式匹配,而不是用于从大数据块中提取匹配项。
XML 模式锚定整个正则表达式。因此,您不能添加正则表达式分隔符,也不需要使用锚点(即开头的 ^ 和结尾的 $)。正则表达式必须匹配整个元素才能被视为有效元素。点从不匹配换行符,并且模式区分大小写。 XML 正则表达式没有像 \xFF 或 \uFFFF 这样的任何标记来匹配特殊字符,也没有提供指定匹配模式的方法。
非贪婪行为没有 XSD 语法。 XSD 也无法使用惰性量词。由于模式锚定在主题字符串的开头和结尾,并且只返回成功/失败结果,这只是性能问题,导致贪婪和懒惰量词之间存在差异。通过将贪婪量词更改为惰性量词或反之亦然,不可能使完全锚定的模式匹配或失败。此外,没有注册或反向引用的子组没有 XSD 语法。
不管其局限性如何,XML 模式正则表达式提供了两个方便的特性。特殊的速记字符类 \i 和 \c 使得匹配 XML 名称变得容易。没有其他正则表达式支持这种可能性。
您不能直接在 FIND & REPLACE 语句中使用 XSD 语法,但您可以使用通过添加 REGEX 的方法 CREATE_XSD 创建的 RegEx 类的对象。
以下示例使用对 PCRE 无效的 XSD 语法,并且找不到任何与 POSIX 匹配的语法。 它也适用于 XPath。
DATA(xml) = `<A><B>...<Y><Z>`.
REPLACE ALL OCCURRENCES OF
REGEX cl_abap_regex=>create_xsd( pattern = `\i\c*` )
IN xml WITH `option:$0`.
cl_demo_output=>display( xml ).
结论
如前所述,正则表达式可以让您解析字符串或复杂的替换操作。 它是一个强大的文本处理工具,可用于扩展您的 ABAP 功能。 我希望我能让你对 RegEx 和 ABAP 中支持的语法,即 PCRE、XPath 和 XSD 有一个粗略的了解。
尽管 PCRE 功能更强大且可在大多数情况下使用,但最好使用 XPath 或 XSD 从 XML 文档中选择节点或计算值(如字符串、布尔值或数字),以更快更高效。 POSIX 语法现在已经过时,需要迁移到 ABAP 支持的任何其他正则表达式语法。 ABAP SQL 和 ABAP CDS 视图还支持带有上述内置函数的 PCRE 语法。 更详细的信息也可以在 ABAP 关键字文档中找到。

- 点赞
- 收藏
- 关注作者
评论(0)