[论文阅读] (23)恶意代码作者溯源(去匿名化)经典论文阅读:二进制和源代码对比

《娜璋带你读论文》系列主要是督促自己阅读优秀论文及听取学术讲座,并分享给大家,希望您喜欢。由于作者的英文水平和学术能力不高,需要不断提升,所以还请大家批评指正,非常欢迎大家给我留言评论,学术路上期待与您前行,加油。
前一篇带来了清华唐杰老师的分享“图神经网络及认知推理总结和普及”或“Graph Neural Networks and Applications—A Review”。这篇文章将介绍两个作者溯源的工作,从二进制代码和源代码两方面实现作者去匿名化或识别。这是两篇非常经典的安全论文,希望您喜欢。一方面自己英文太差,只能通过最土的办法慢慢提升,另一方面是自己的个人学习笔记,并分享出来希望大家批评和指正。希望这篇文章对您有所帮助,这些大佬是真的值得我们去学习,献上小弟的膝盖~fighting!
前文赏析:
- [论文阅读] (01) 拿什么来拯救我的拖延症?初学者如何提升编程兴趣及LATEX入门详解
- [论文阅读] (02) SP2019-Neural Cleanse: Identifying and Mitigating Backdoor Attacks in DNN
- [论文阅读] (03) 清华张超老师 - GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [论文阅读] (04) 人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [论文阅读] (05) NLP知识总结及NLP论文撰写之道——Pvop老师
- [论文阅读] (06) 万字详解什么是生成对抗网络GAN?经典论文及案例普及
- [论文阅读] (07) RAID2020 Cyber Threat Intelligence Modeling Based on Heterogeneous GCN
- [论文阅读] (08) NDSS2020 UNICORN: Runtime Provenance-Based Detector for Advanced Persistent Threats
- [论文阅读] (09)S&P2019 HOLMES Real-time APT Detection through Correlation of Suspicious Information Flow
- [论文阅读] (10)基于溯源图的APT攻击检测安全顶会总结
- [论文阅读] (11)ACE算法和暗通道先验图像去雾算法(Rizzi | 何恺明老师)
- [论文阅读] (12)英文论文引言introduction如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (13)英文论文模型设计(Model Design)如何撰写及精句摘抄——以入侵检测系统(IDS)为例
- [论文阅读] (14)英文论文实验评估(Evaluation)如何撰写及精句摘抄(上)——以入侵检测系统(IDS)为例
- [论文阅读] (15)英文SCI论文审稿意见及应对策略学习笔记总结
- [论文阅读] (16)Powershell恶意代码检测论文总结及抽象语法树(AST)提取
- [论文阅读] (17)CCS2019 针对PowerShell脚本的轻量级去混淆和语义感知攻击检测
- [论文阅读] (18)英文论文Model Design和Overview如何撰写及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (19)英文论文Evaluation(实验数据集、指标和环境)如何描述及精句摘抄——以系统AI安全顶会为例
- [论文阅读] (20)USENIXSec21 DeepReflect:通过二进制重构发现恶意功能(恶意代码ROI分析经典)
- [论文阅读] (21)S&P21 Survivalism: Systematic Analysis of Windows Malware Living-Off-The-Land (经典离地攻击)
- [论文阅读] (22)图神经网络及认知推理总结和普及-清华唐杰老师
- [论文阅读] (23)恶意代码作者溯源(去匿名化)经典论文阅读:二进制和源代码对比
一.NDSS18:二进制代码的作者去匿名化(代码风格+AST+RF)
原文作者:Aylin Caliskan-Islam, Fabian Yamaguchi, Edwin Dauber, et al.
原文标题:When Coding Style Survives Compilation: De-anonymizing Programmers from Executable Binaries
中文标题:当编码风格在编译中幸存下来时:从可执行二进制文件中对程序员进行去匿名化
原文链接:https://arxiv.org/abs/1512.08546
发表会议:2018 NDSS

1.摘要
根据代码风格(coding style)识别计算机程序作者的能力直接威胁到程序员的隐私和匿名性。
虽然最近的工作发现,源代码(source code)可以高精度地溯源至(attributed to)作者,但可执行二进制文件(executable binaries)作者的归属问题似乎要困难得多。因为源代码中存在许多显著的特征,例如变量名,但在编译过程中会被删除,并且编译器优化可能会改变程序的结构,进一步掩盖已知对确定作者身份(authorship)有用的特征。
本文从机器学习角度实现程序员去匿名化任务,使用一组新颖的特征,包括将可执行二进制文件反编译为源代码所获得的特征。同时采用来自源代码作者溯源领域的一组强大的技术以及嵌入在汇编中的风格表征,从而成功地对大量程序员进行去匿名化处理。
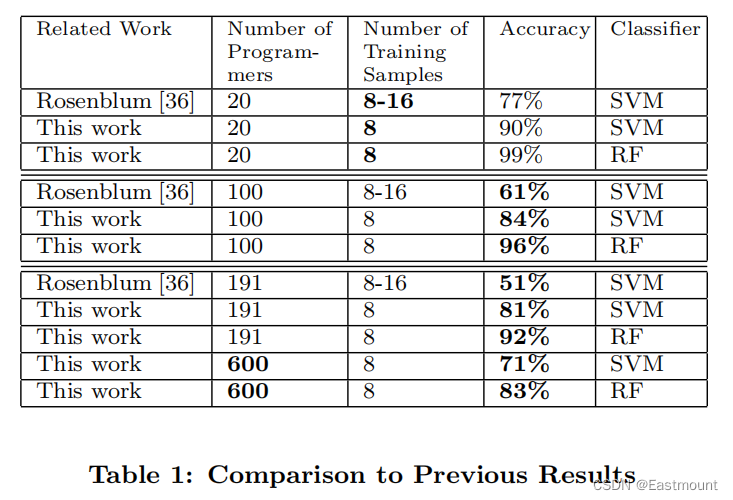
本文实验通过谷歌GCJ(Google Code Jam)数据集评估了方法的有效性,其中,100名候选程序员的溯源准确率高达96%,600名候选程序员的溯源准确率为83%。我们首次提出了一种可执行二进制文件的作者溯源方法,该方法对基本混淆、一系列编译器优化设置和去符号表的二进制文件具有鲁棒性。此外,本文使用混淆的二进制文件和在单作者GitHub存储仓库以及最近泄露在 Nulled.IO 黑客论坛中的“在野”真实代码来执行程序员去匿名化实验。结果表明,那些想要保持匿名的程序员需要采取极端的应对措施来保护他们的隐私。

2.引言
如果遇到一个“在野”可执行的二进制样本,我们可以从中学到什么?
在本文的工作中,我们展示了程序员的风格指纹或编程风格在编译过程中是能被保留下来的,并且可以从可执行的二进制文件中提取。这意味着,如果我们有一组已知的潜在候选程序员,以及由这些候选程序员编写的可执行二进制样本(或源代码),就可以推断出程序员的身份。
可执行二进制文件的作者去匿名化影响了隐私和匿名性。但在软件取证、版权、审查等领域中需要实现作者溯源,我们的工作能有效实现二进制文件的去匿名化。此外,白宫和DARPA指出“需要增强溯源能力以识别不同端设备和C2基础设施的虚拟角色和恶意网络运营商”。
方法对比突出本文贡献:
- Rosenblum经典工作:可以直接从可执行二进制文件中提取控制流图等结构,首次针对二进制代码提出一种自动检测代码风格特征的方法并确定程序作者
- 本文工作:首次证明可执行二进制文件的自动反编译(automated decompilation)提供了额外有用的特征。具体而言,我们生成反编译源代码的抽象语法树(abstract syntax trees),利用随机森林分类器能有效地组合特征,从而提升作者溯源的准确性。
具体方法为:分析人员需要将每个标记的二进制样本转换为一个数值特征向量,再利用机器学习技术推导出一个分类器,并预测匿名二进制文件最有可能的程序员。此外,我们发现二进制混淆、启用编译器优化或剥离可执行二进制文件的调试符号会降低去匿名化的准确性。
- 关键点:经过分解和反编译获得的特征向量如何来预测源代码中的特征,如何重构二进制代码的编程风格特征(指纹)
N. Rosenblum, X. Zhu, and B. Miller. Who wrote this code? Identifying the authors of program binaries. Computer Security–ESORICS, 2011.
相关工作:
- Linguistic stylometry
- Source code stylometry
- Executable binary stylometry
3.本文方法
Our ultimate goal is to automatically recognize programmers of compiled code.
数据表示对于机器学习的成功至关重要。 因此,我们为可执行二进制作者溯源设计了一个特征集,目标是准确地表示与程序员风格相关的可执行二进制文件的属性。我们通过使用额外的字符串和符号信息来增强从反汇编器中提取的低级特征,从而获得该特征集,最重要的是,该方法结合了从反编译器获得的高级语法特征(syntactical features)。
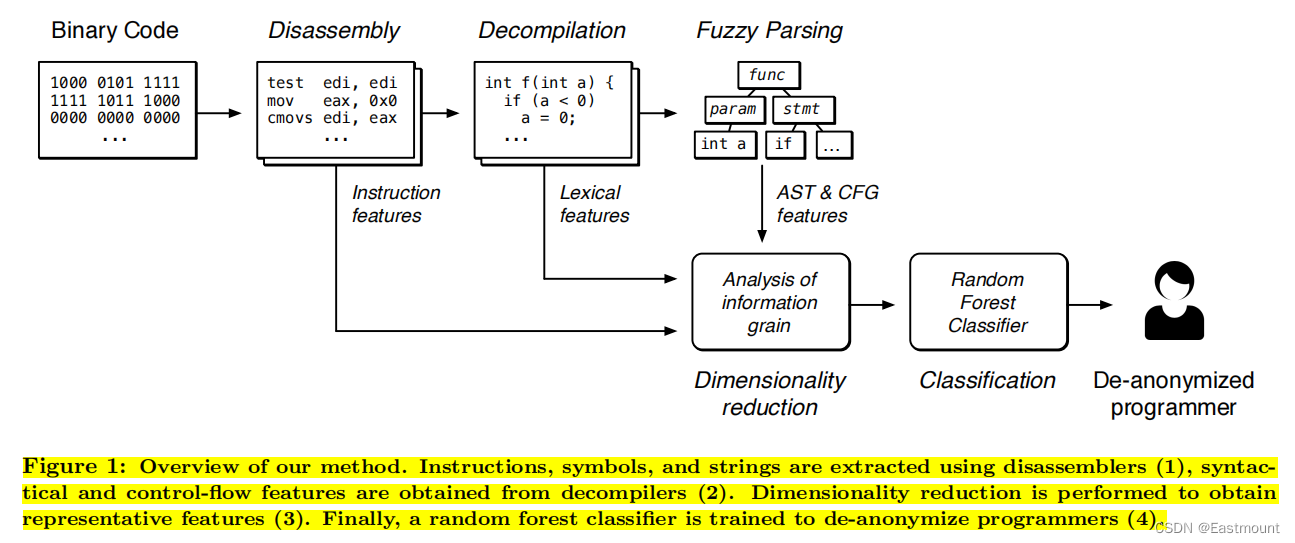
本文方法的框架图如下所示,包括四个关键步骤:
- Disassembly(反汇编)。我们首先对二进制程序进行反汇编,以获得基于机器代码指令、引用字符串、符号信息和控制流图(CFG)的特征(第 4.1 节)。
- Decompilation(反编译)。 我们继续通过反编译将程序翻译成类似C语言的伪代码。随后将代码传递给C语言的模糊解析器,因此,我们获得了可以从中提取语法特征和n-gram的抽象语法树(第 4.2 节)。如图中函数f声明及变量a定义。
- Dimensionality reduction(降维)。 借助反汇编器和反编译器的特征,我们利用基于信息增益和相关性的特征选择技术,选择其中对分类特别有用的特征(第 4.3 节)。
- Classification(分类)。最后,在相应的特征向量上训练一个随机森林分类器,生成一个可用于自动执行二进制作者溯源的程序(第4.4节)。
关键特征:
- Instruction features
- Lexical features
- AST & CFG features
(1) Feature extraction via disassembly
利用反汇编器提取低级特征。按照Rosenblum方法从可执行二进制中提取原始指令轨迹,同时反汇编程序会提供符号信息以及代码中引用的字符串,再从反汇编器中获得函数的控制流图,提供基于程序基本块的特征。
- The netwide disassembler:基本的反汇编器,能够解码指令。从头到尾反汇编二进制文件,遇到无效指令时跳过该字节。
- The radare2 disassembler:从动态和静态符号表中提取符号并获得动态库函数知识,生成相应的控制流图。
(2) Feature extraction via decompilation
与反汇编器相比,反编译器不仅揭示程序的机器代码指令,而且还额外重构更高层次的结构,试图将可执行二进制文件转换为等价的源代码。特别而言,反编译器可以重构控制结构,如不同类型的循环和分支结构。我们利用了代码的这些语法特性,因为它们在源代码作者身份溯源的上下文中已经被证明是有价值的。我们从伪代码中提取了两种类型的特征:
- lexical features(词法特征):单词组合以捕获程序中使用的整数类型、库函数名称,以及当符号信息可用时内部函数的名称。
- syntactical features(语法特征):抽象语法树。
(3) Dimensionality reduction
特征提取会产生大量特征,从而产生具有数千个元素的稀疏特征向量。然而,并不是所有的特征都具有同样的信息来表达程序员的风格。因此,需要进行特征选择的降维操作。我们使用信息增益准则,然后基于相关性的特征选择来识别将每个作者表示为一个类的信息量最大的属性。
- 方法一:information gain(WEKA编写代码)
- 方法二:correlation based feature selection
We use information gain criteria followed by correlation based feature selection to identify the most informative attributes that represent each author as a class.
(4) Classification
我们使用随机森林分类器,它是由决策树集合构成的集成学习算法,其中每棵树都是在随机抽样获得的数据的子样本上进行训练。(kappa编写代码)
4.实验评估
(1) GCJ数据集
我们在一个基于年度编程竞赛GCJ的数据集上评估了可执行二进制作者溯源方法。本文的分析重点是已编译的C++代码,这是比赛中使用最流行的编程语言。我们收集了2008年至2014年的解决方案,以及作者名称和问题标识符。
- Google Code Jam Programming Competition. code.google.com/codejam.
为了创建实验数据集,我们首先用GNU编译器集合的gcc或g++编译了源代码,并且没有对二进制文件进行任何优化。我们还编译了具有1级、2级和3级优化的源代码,即O1、O2和O3标志。
- To create our experimental datasets, we first compiled the source code with GNU Compiler Collection’s gcc or g++ without any optimization to Executable and Linkable Format (ELF) 32-bit, Intel 80386 Unix binaries.
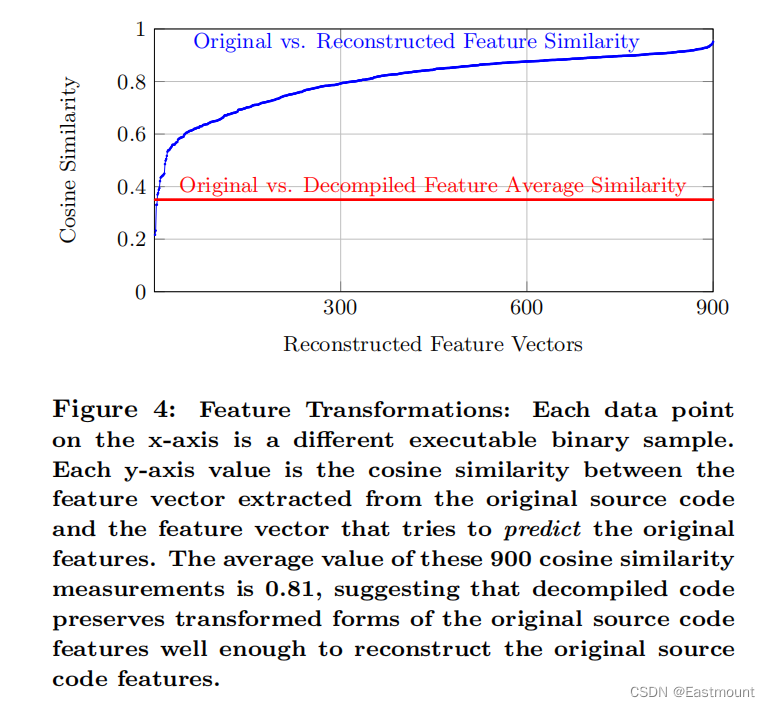
我们感兴趣的是识别二进制文件中的编码样式特征。应用当前方法,我们提取了100名作者的750,000种代码属性表示,最终保留了53个高度区分的特征。实验结果如下图所示:
通过源代码特征向量与预测原始特征向量的余弦相似度比较,我们得出如下图所示的实验结果,900个余弦相似度度量的平均值为0.81。该结果表明:
- 反编译代码很好地保留了原始源代码特征的转换形式,即重构的特征接近于源代码的特征。因此,本文方法可以重构原始源代码特征。
(2) 真实场景
此外,本文使用混淆的二进制文件和在单作者GitHub存储仓库以及最近泄露在 Nulled.IO 黑客论坛中的“在野”真实代码来执行程序员去匿名化实验。

5.讨论和结论
本文实现了二进制文件的作者溯源(去匿名化)研究,展现了代码方格是能在编译后提取的,并且在GCJ和Github真实数据集中进行了程序员去匿名化实验。其中,100名候选程序员的二进制溯源准确率高达96%,600名候选程序员的溯源准确率为83%。
同时,本文通过两种不同的反汇编器、控制流图和一个反编译器,获得了这种编码样式的精确表示,有效提取53个关键特征。程序员风格会以令人惊讶的程度嵌入到可执行的二进制文件中,即使它被混淆、编译器优化或符号被剥离降低了风格分析的准确性,但在仍能应用于程序员去匿名化任务中。结果表明,那些想要保持匿名的程序员需要采取极端的应对措施来保护他们的隐私。
Programmer style is embedded in executable binary to a surprising degree, even when it is obfuscated, generated with aggressive compiler optimizations, or symbols are stripped. Compilation, binary obfuscation, optimization, and stripping of symbols reduce the accuracy of stylistic analysis but are not effective in anonymizing coding style.
未来工作:
- 计划研究代码片段和功能级别的代码风格信息
- 对去匿名化协作生成的二进制文件开展多作者溯源研究
- 对高度复杂的编译和混淆方法开展研究
6.个人感受
写到这里,这篇论文就分享结束了,再次感谢论文作者及引文的老师们。接下来是作者的感受,由于是在线论文读书笔记,仅代表个人观点,写得不好的地方,还请各位老师和博友批评指正,感恩遇见,读博路漫漫,一起加油!
- 先前的工作多集中于源代码作者溯源,提取具有作者编程(代码)风格的特征是关键。然而,二进制代码会因为编译、混淆等处理导致编程风格丢失,并且恶意攻击中常以可执行二进制文件为主。因此,针对二进制代码的作者溯源或去匿名化研究直观重要。
- 该论文摘要的方法论部分似乎还可以补充下,同时摘要的实验部分没有之前看到的顶会论文清晰。
- 论文的方法比较简单,包括反汇编、反编译、降维和分类四个部分,所使用的分类方法为随机森林,提取的特征我们也能想到。从现在来看,很容易想到,但2018年能写到这样还是挺佩服的,也值得我们学习。个人认为,相比于模型的新旧,安全论文更看重模型如何解决实际问题以及是否贴合创新。
- 实验部分希望自己今后能复现下,包括GCJ数据集(源码编译二进制)和真实数据集,同时可以深入思考如何进一步提升性能,动态特征和静态特征如何更好地结合实现作者溯源,真正去解决恶意二进制代码作者溯源难点。此外,一篇好论文通常会有真实的实验支撑,实验需要和我们的方法论互补且结合。
- Caliskan-Islam和Rosenblum两个团队在代码去匿名化领域做了较多工作,推荐大家去系统学习。同时,APT溯源、作者溯源存在怎样的区别或关联呢?预计2023年初,我会详细写一篇文章总结各类溯源及检测技术 。
二.UsenixSec15:基于代码风格的源代码去匿名化(AST+RF+特征)
原文作者:Aylin Caliskan-Islam, Richard Harang, Andrew Liu, et al.
原文标题:De-anonymizing Programmers via Code Stylometry
原文链接:https://www.usenix.org/system/files/conference/usenixsecurity15/sec15-paper-caliskan-islam.pdf
发表会议:2015 Usenix Sec

1.摘要
源代码作者溯源是对匿名代码贡献者的一个重大隐私威胁。然而,它还可以将成功的攻击归因于受感染系统上遗留的代码,或帮助解决编程领域中的版权、著佐权和剽窃问题。
在这项工作中,我们研究了使用编码风格对 C/C++ 的源代码作者进行去匿名化的机器学习方法。我们的代码风格特征集是一种在源代码中发现的编码风格的新颖表示,它反映了来自抽象语法树的属性的编码风格。
我们基于随机森林和抽象语法树的方法溯源了更多的作者(1600和250),并且在更大的数据集(Google Code Jam)上具有比先前工作更高的准确率(94%和98%)。此外,这些新特征是健壮的,难以混淆的,并且可以用于其它编程语言,如Python。
我们还发现:
- (i)由困难的编程任务产生的代码比容易的任务更易于溯源;
- (ii)熟练的程序员(可以完成更困难的任务)比不熟练的程序员更容易溯源。

2.引言
程序员会在源代码中留下指纹吗?每位程序员都有一个独特的“编码风格”(coding style)吗?
或许,程序员更喜欢空格而不是标签,或者更喜欢while循环而不是for循环,再或者更微妙地说,比起单一代码更喜欢模块化代码。
这些问题有很强的隐私和安全影响。开源项目的贡献者可能会隐藏他们的身份,无论他们是Bitcoin的创造者,还只是一个不希望她的雇主知道她的业余活动的程序员。他们可能生活在一个禁止某些类型软件的制度中,比如审查规避工具。
另一方面,代码溯源可能会有帮助取证,比如发现代写、抄袭和版权纠纷调查等。它也可能给我们提供关于恶意软件作者身份的线索。警惕的攻击者可能只留下二进制文件,但其他的攻击者可能会留下脚本语言编写的代码或下载到被破坏系统中进行编译的源代码。
本文在先前研究的基础上,展示了抽象语法树能携带作者相关的“指纹”,从而提升准确率。本文的贡献如下:
- 首先,我们将语法特征(syntactic features)作用于代码风格(code stylometry)。
提取这些特征需要使用模糊解析器(fuzzy parsing)解析不完整的源代码以生成抽象语法树。这些特征为迄今为止几乎完全未开发的代码样式添加了一个组件。我们提供的证据表明,这些特征更为基础且更难混淆。我们的完整特征集由大约12万个基于 布局(layout)、词法(lexical)和语法(syntactic) 的特征组成。有了这个完整的特征集,我们比先前的工作具有更高的准确率。 - 其次,本文将该方法扩展到1600名程序员并且未损失很多准确率。
- 最后,该方法不是特定于C或C++的,可以应用于任何编程语言。
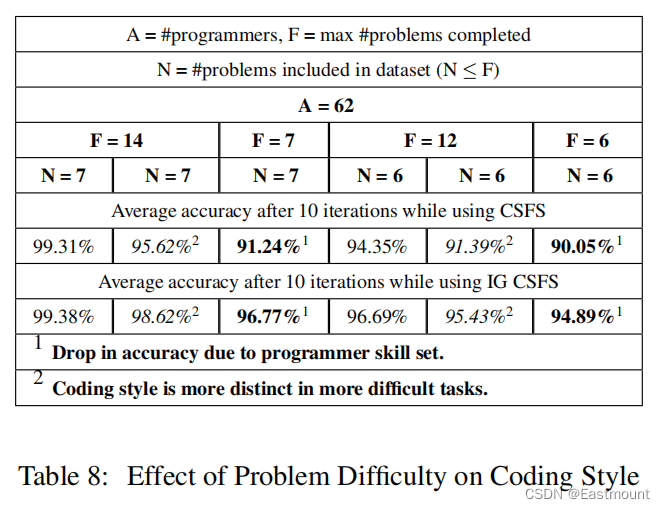
本文从GCJ比赛中收集C++源代码,利用基于词袋的随机森林分类器来实现源代码的程序员溯源。最后,我们分析了程序员的各种属性、编程任务类型,以及会影响溯源成功的特征。我们从12万个特征中确定了最重要的928个特征,其中44%是语法性的,1%是基于布局的,其余的特征是词汇性的。当使用词汇、布局和句法特征时,平均有70行代码的8个训练文件是足够的。我们还观察到,具有更高技能的程序员更容易识别,而且程序员的编码风格在困难任务的实现中比更容易的任务更独特。
研究动机:
- Programmer De-anonymization:bitcoin作者去匿名化
- Ghostwriting Detection:剽窃行为检测、学生作业抄袭判定(代码风格相似性)
- Software Forensics:恶意代码作者取证
- Copyright Investigation:版权调查和代码版权纠纷
- Authorship Verification:授权验证(one-class SVM)

3.本文方法
本文研究目标之一是创建一个分类器以自动确定源文件最有可能的作者。机器学习是解决该问题的一个选择,然而,它们的成功关键取决于一个具有代表性编程风格特征集的选择。为此,我们:
- 首先,解析源代码,从而获得广泛的反映编程语言用法的可能特征(第3.1节)。
- 然后,定义不同特征来表示程序代码的语法和结构(第3.2节)。
- 最后,训练一个随机森林分类器用于分类未知的源代码。
(1).Fuzzy Abstract Syntax Trees
迄今为止,源代码作者溯源的方法主要集中于代码的顺序特征表示上,如字节级和特征级的n-gram。虽然这些模型非常适合捕获命名约定和关键字的偏好,但它们完全是与语言无关,因此无法对仅在语言结构组合中明显的作者特征进行建模。例如,作者倾向于创建深度嵌套的代码、异常长的函数或较长的赋值链接,这不能单独使用n-gram来建模。
针对不完整代码,我们使用模糊解析器解析代码,从而生成对应的抽象语法树。生成的语法树构成了我们特征提取过程的基础。虽然它们很大程度上保留了创建n-grams或bag-of-words表示所需的信息,但它们允许提取大量特征,这些特征对代码结构中可见的程序员习惯进行编码。
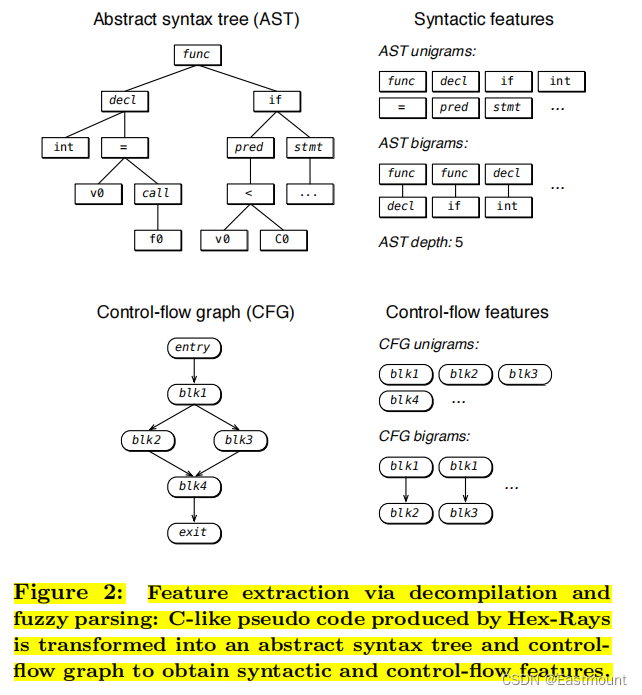
下图是一个源代码转换为抽象语法树的示例,抽象语法树都包含一个对应的节点,树的叶子节点使经典的语法特征如关键字、标识符和操作符,内部节点表示显示的操作如何组合这些基本元素来形成表达式和语句。

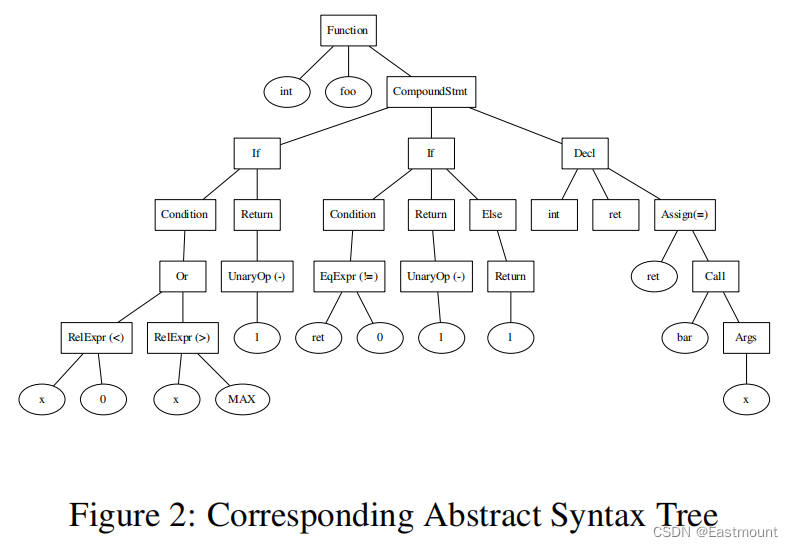
(2).Feature Extraction
为了更清晰地表达源代码的程序风格,本文提出了代码风格特征集(Code Stylometry Feature Set,CSFS),这是一种专门为代码风格开发的源代码表示方法。该特征集包括词汇特征、布局特征和语法特征。其中,词汇特征和布局特征只能从源代码中获得,而语法特征只能从AST中获得。
- Lexical Features
- Layout Features
- Syntactic Features
首先从源代码中提取数字特征,这些数字特征表达了对某些标识符和关键字的偏好,以及一些关于函数使用或嵌套深度的统计数据。词汇和布局特性可以从源代码计算,而不访问解析器,使用编程语言的基本知识。此外,我们对源文件进行标记化,以获得每个标记的出现次数,即所谓的单词单图。表2给出了词汇特征的概述。
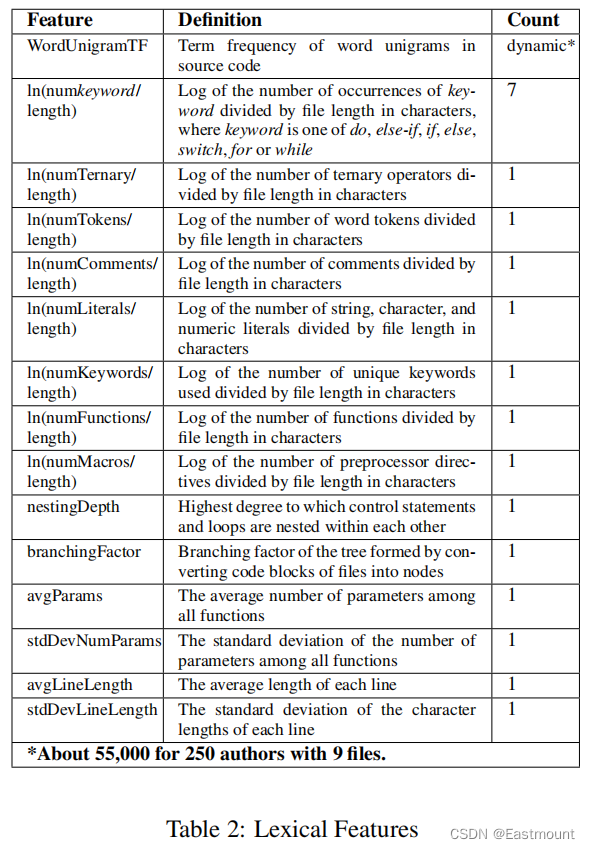
此外,我们还考虑了表示代码缩进的布局特性。例如,我们确定大多数缩进的行是以空白还是制表符开头,并确定空格与文件大小的比率。表3给出了对这些特征的详细描述。
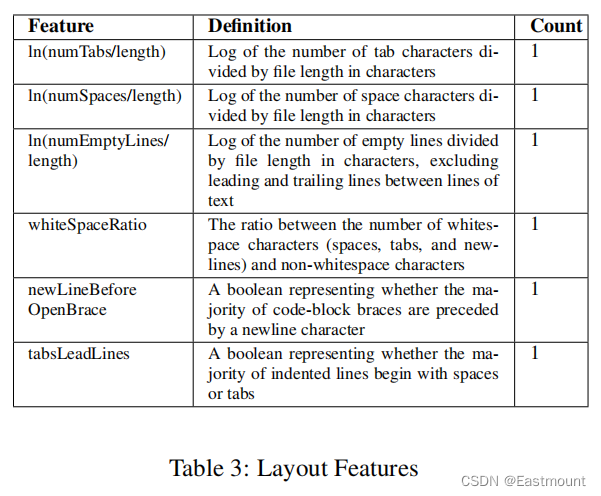
语法特征集描述了依赖于语言的抽象语法树和关键字的属性。计算这些特性需要访问一个抽象的语法树,所有这些特征对于源代码布局和注释的更改都是不变的。表4给出了语法特征的概述,我们通过对数据集中的所有C++源文件进行预处理来生成抽象语法树并获得这些特征(TF、IDF、TFIDF)。
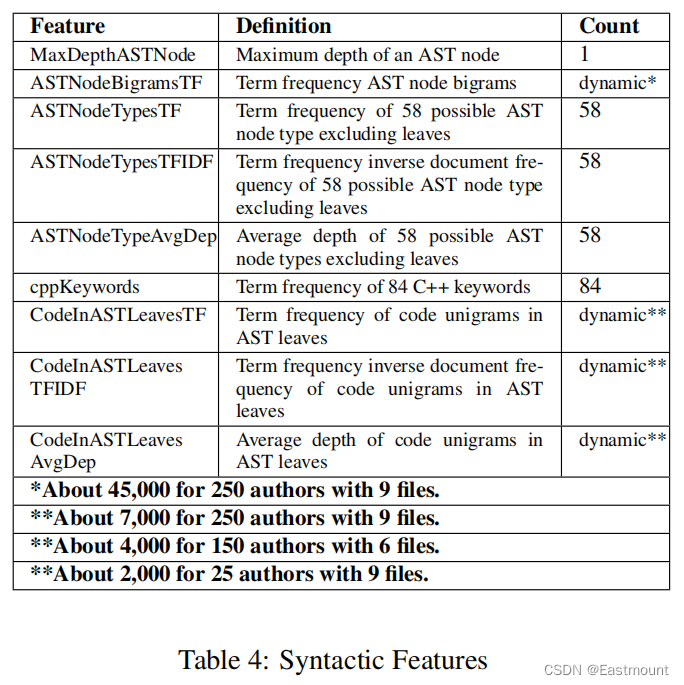
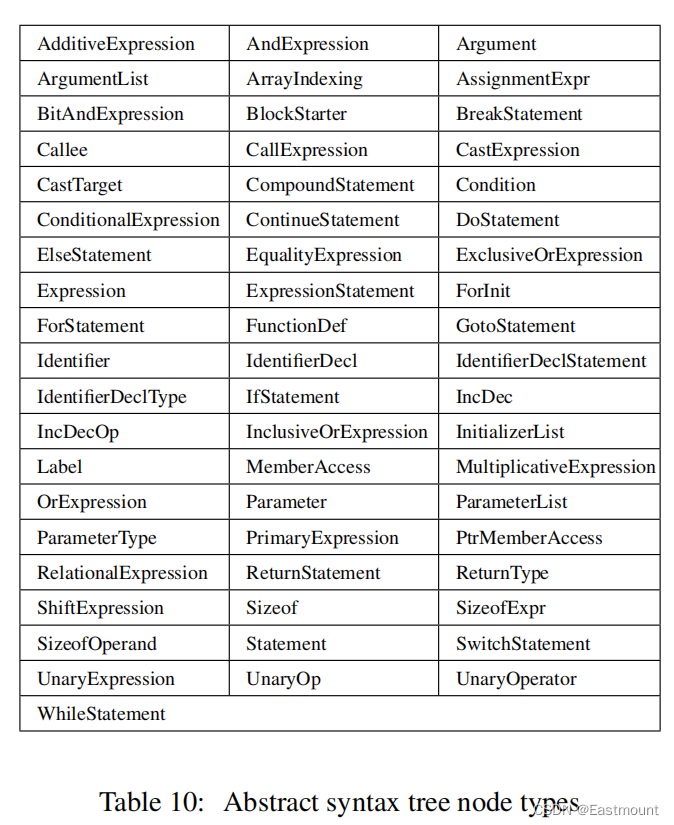
抽象语法树得58种节点类型如下表所示。AST节点的平均深度显示了程序员倾向于使用特定结构片段的嵌套或深度。最后计算每个C++关键字的项频率,每个特征都被写入一个特征向量,以表示特定作者的解决方案文件,这些向量随后被用于机器学习分类器的训练和测试。
(3).Classification
由于会产生大量特征且存在矩阵稀疏问题。因此,我们采用WEKA的信息增益准则进行特征选择,该准则评估类的分布的熵与给定特定特征的类的条件分布的熵之间的差异:
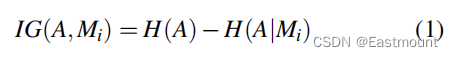
为了减少特征向量的总大小和稀疏性,我们只保留那些信息增益非零的特征。最后构建随机森林分类器进行源代码作者溯源。

4.实验评估
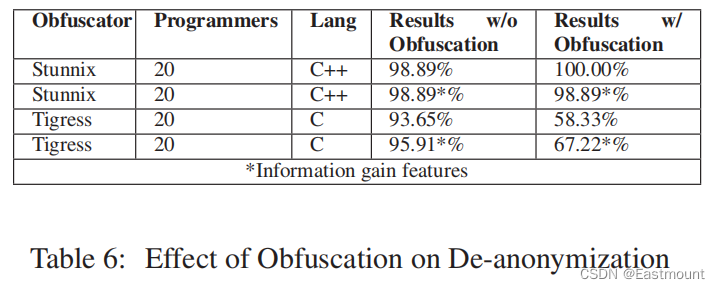
实验数据集是在Google Code Jam (GCJ)的基础上构建的数据集,包括1600名程序员,实验结果如下图所示:


同时进行了混淆、不同编程语言的实验。
5.结论
当前,源代码的编程风格已经被广泛应用于隐私、安全、软件取证、剽窃、版权侵权纠纷和作者验证领域。源代码编程风格对于代码去匿名化是一个迫在眉睫的问题。
本文首次系统性使用词法、布局和语法特征来研究源代码的编程风格,并对1600位作者进行分类,其准确率为94%,对250位作者进行分类,准确率为98%。本文方法提高了源代码作者溯源的准确率和规模。此外,传统方法仅能识别50个作者,分析的文本需要5000个单词,本文通过训练550行代码和8个解决方法即可实现。特别而言,本文的研究表明:
- 基于代码风格特征集(code Stylometry Feature Set)的源代码作者溯源比常规风格作者溯源更有效
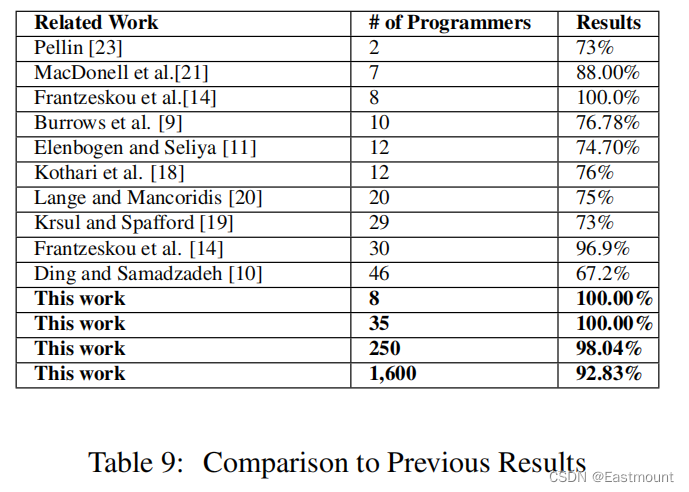
未来工作:
- 由于恶意代码通常只能使用二进制格式,因此研究二进制文件如何保留语法特征是一件有趣的工作
- 进一步提高分类精度,例如,我们想探讨使用具有联合信息增益的特性是否会提高性能
- 设计捕获抽象语法树更大片段的特征来提升性能,这些更改(以及添加词法和布局特征)可能会对Python的结果提供显著的改进
- 代码是否可以自动规范化以删除样式信息,同时保留功能和可读性
6.个人感受
这篇文章针对源代码去匿名化开展研究,完成于2015年,整个文章的亮点是:
- 源代码编程风格特征的总结,即(Code Stylometry Feature Set,CSFS),包括词汇、布局和语法三类特征,其中通过抽象语法树提取语法特征,词汇特征和布局特征从源代码中统计获得。
接着,通过特征提取、降维和向量表征来构建具有编程风格的源代码向量,最后构建随机森林分类器完成任务。方法论和前面二进制作者溯源比较相近,现在回头看,方法和实验略微简单,但仍有很多值得我们学习的地方,包括:
- 如何更少地结合人工经验(特征工程)完成该任务,是否能结合源代码本身特性来构建深度学习模型完成分类,深度学习又将如何实现呢?
- 如何解决代码混淆、编译优化等溯源问题,包括二进制溯源、多作者溯源等
- 在特征工程中如何构建更好地降维方法识别更关键的特征,并提高作者溯源的可解释性(tanE)
- 如何与实际安全问题结合,包括APT溯源、无文件攻击溯源等
写一篇好的顶会真难,值得我们学习,继续加油!
三.总结
写到这里,这篇文章就分享结束了,再次感谢论文作者及引文的老师们。由于是在线论文读书笔记,仅代表个人观点,写得不好的地方,还请各位老师和博友批评指正。
后面作者将分享两篇基于深度学习的作者溯源论文,分别是:
- Mohammed Abuhamad, et al. Large-Scale and Language-Oblivious Code Authorship Identification, 2018 CCS.
- Saed Alrabaee, et al. CPA: Accurate Cross-Platform Binary Authorship Characterization Using LDA, 2020 IEEE TIFS.
最后,用川大吴鹏博士的论文进行总结,非常推荐大家学习且感谢吴老师。
- 吴鹏. 多形态软件代码同源判定技术研究[D]. 四川大学博士论文, 2021.
软件代码同源研究集中在恶意代码同源以及软件代码作者识别等方面,其中恶意代码同源分析为了发现未知恶意代码变种以及恶意代码家族及关联关系分析,软件作者识别为了判定软件代码是否出于同一人或相同团队,既有利于软件知识产权保护又可实现软件代码溯源。
软件代码作者编程过程中,不可避免会留下编程习惯,比如注释风格、排版布局等,编译过程尽管会损失部分代码风格特征,比如排版布局,但函数使用频率、代码模块架构模式等编程习惯依然会被保留,且不同软件代码编写者,鉴于其知识、经验、能力差异,其编程习惯几乎难以完全一致。以上特点确保了软件作者代码作者识别切实可行,加之其在软件知识产权保护、网络攻击溯源等领域极具应用前景,已对其展开了不少探索。
软件代码作者溯源通常划分为源代码作者识别和二进制代码作者识别。两者已围绕编程习惯、编程风格等特征从关键字符文本、抽象语法树以及代码结构图等多个维度进行了尝试;方法层面从经典距离计算到分类聚类算法再到神经网络模型不断进步;研究对象从单一作者到多作者,单一平台到跨平台均展开了研究;甚至从逃避检测角度也受到了足够重视。但源代码习惯易被篡改、二进制代码习惯难以捕获等问题依然没有很好地解决,整体而言,相关方法难以大规模应用,亟需对其展开深入研究。

这篇文章就写到这里,希望对您有所帮助。由于作者英语实在太差,论文的水平也很低,写得不好的地方还请海涵和批评。同时,也欢迎大家讨论,继续加油!感恩遇见,且看且珍惜。

(By:Eastmount 2022-08-02 周四夜于武汉 http://blog.csdn.net/eastmount/ )
文章来源: blog.csdn.net,作者:Eastmount,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/Eastmount/article/details/126045518

- 点赞
- 收藏
- 关注作者
评论(0)