3D激光slam:LeGO-LOAM---基于广度优先遍历的点云聚类算法及代码分析

前言
广度优先遍历(BFS)算计介绍
广度优先遍历(BFS)和深度优先遍历(DFS)同属于两种经典的图遍历算法
广度优先遍历算法:首先从某个节点出发,一层一层的遍历,下一层必须等到上一层节点全部遍历完之后才会开始遍历
基本思想:尽最大程度辐射能够覆盖的节点,并对其进行访问。
用一道BFS的题来进行举例
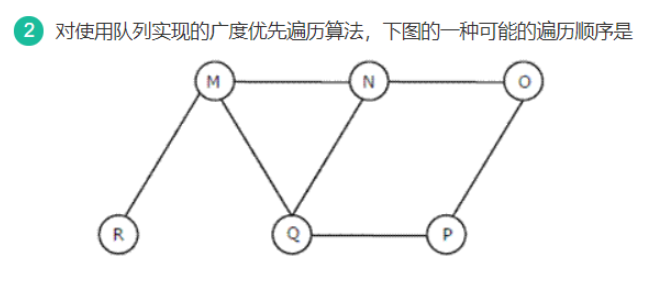
-
以M节点为顶点的话
则遍历顺序为:MNQP或MNPQ或MQNP或MQPN或MPQN或MPNQ -
以N节点为顶点的话
遍历顺序为:NMOQ或NMQO或NOQM或NOMQ或NQOM或NQMO -
以Q节点为顶点的话
遍历顺序为:QMNPR
进行BFS算法实现的时候都是以一个队列的形式进行
下面举一个节点多些的例子,以队列的形式更好理解算法是如何进行的
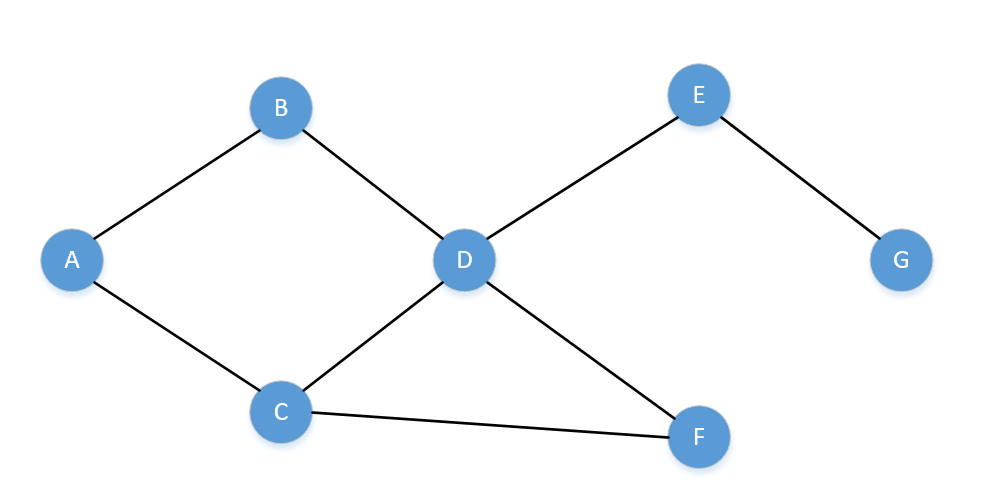
这是一个无向图,即用线连的两个节点均个互相到达对方,例如A可以到B,B也可以到A
以A为顶点,以队列的形式,走下BFS算法的流程如下:
- 第一个节点是A,先将A 入队列。当前队列为:A
- 从队列中取出A,通过A找到两个节点分是 B 和 C,将它俩如队列。当前队列为:BC
- 从队列中取出B,通过B可以找到A和D,A访问过,忽略,将D入队列。当前队列为:CD
- 从队列中取出C,通过C可以找到A、D、F,A和D访问过,忽略,将F入队列。当前队列为:DF
- 从队列中取出D,通过D可以找到BCEF,BCF已访问,忽略,将E入队列。当前队列为:FE
- 从队列中取出F,通过F可以找到CD,CD已访问,忽略,没有可以加入队列的。当前队列为:E
- 从队列中取出E,通过E可以找到DG,D已访问,忽略,G加入队列。当前队列为:G
- 从队列中取出G,通过G可以找到E,E已访问,忽略,没有可以加入队列的。当前队列为:空
- 判断队列为空,广度优先遍历结束。
所以上面图,访问的顺序为:ABCDFEG
基于BFS的点云聚类和外点剔除
点云聚类就是把空间上距离相近的点,作为一个集合,打上要给标签
集合中点数过少的集合,认为是杂点,需要剔除,在特征提取的时候不考虑这些点。
点云的聚类的方式就是基于广度优先遍历算法(BFS)
BFS算法适用于图数据结构,为了把单帧激光雷达点云运用上BFS算法,首先需要将其建模成一个图模型。
一帧点云建立图模型方法:
将一帧点云投影到一个平面地图上,比如velodyne-16的激光雷达(有16根线,每个线有1800个点),将其投影到16*1800大小的图上。

一个格子就代表一个点,格子里的值就是物体到雷达中心的距离
现在图有了,就该定义顶点和边了。
顶点:激光雷达一帧里面的每个点都作为一个顶点
边:一个点的上下左右,的点的连线,作为边,该点的上下左右也就是其邻接点
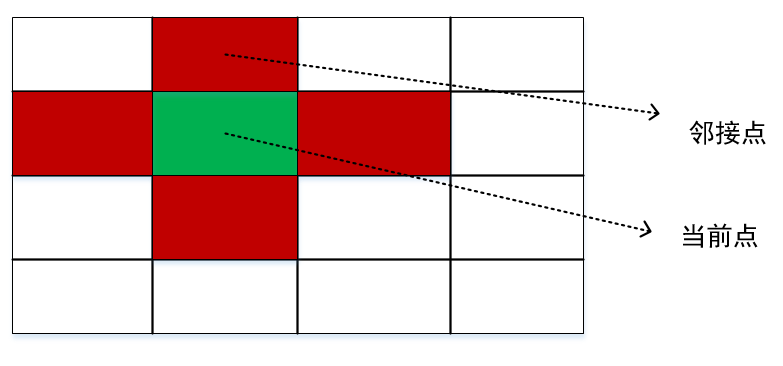
由于机械室激光雷达水平方向上是360°的,所以左右边界和另一个也构成邻接点。但是垂直方向上不连续的,所以不能把上下边界作为邻接点。
根据BFS算法,遍历可以从任意一个有效的点开始,至到所有的点都被遍历到
基于BFS的点云聚类方法:
如果没有被处理说明这是一个新的聚类,然后执行BFS的步骤
将队列里的首个元素弹出,然后将该元素近邻塞入队列末尾,在代码中为了执行效率,没有使用std::queue,使用的是普通数组,用双指针实现的一个队列的加入和弹出。
元素近邻就是上面建立的图模型的上下左右
聚类判别原理—通过一个角度判断
没有通过距离判断的原因,就是应为水平角度分辨率和垂直角度分辨率差别很大。所以水平方向和垂直方向的近邻点的距离会小很多。
要判断的角度如下图所示,该角度越大,说明离得越近,角度越小,说明离得越远
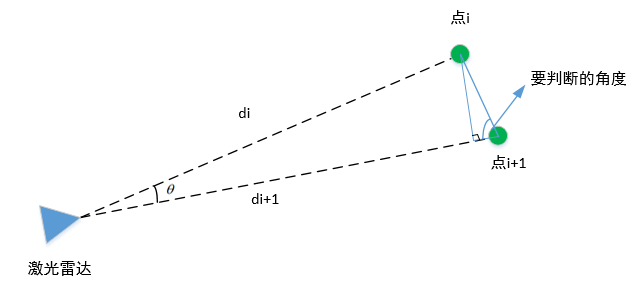
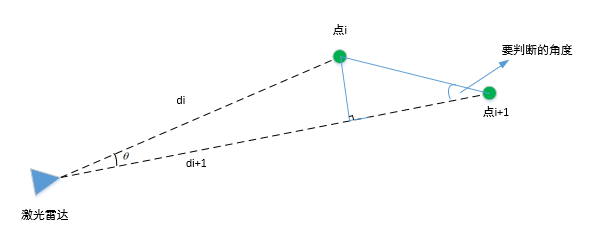
图中的,di和di+1与角度塞塔,是已知的,可以直接求得要判断的角度
代码讲解
LeGO-LOAM的代码中,基于BFS的点云距离分割代码在imageProjection.cpp中。
在cloudHandler函数中,调用了cloudSegmentation函数
void cloudHandler(const sensor_msgs::PointCloud2ConstPtr& laserCloudMsg){
// 1. Convert ros message to pcl point cloud
copyPointCloud(laserCloudMsg);
// 2. Start and end angle of a scan
findStartEndAngle();
// 3. Range image projection
projectPointCloud();
// 4. Mark ground points
groundRemoval();
// 5. Point cloud segmentation
cloudSegmentation();//点云分割
// 6. Publish all clouds
publishCloud();
// 7. Reset parameters for next iteration
resetParameters();
}
在里面完成了点云分割
在cloudSegmentation函数中,首先遍历每个点,判断该点不是地面点,并且没有遍历过,并且有效,那么则以该点为起始,进入BFS的聚类分割。
for (size_t i = 0; i < N_SCAN; ++i)
for (size_t j = 0; j < Horizon_SCAN; ++j)
if (labelMat.at<int>(i,j) == 0)
labelComponents(i, j);
下面来具体看看labelComponent函数中如何进行的BFS的聚类分割
void labelComponents(int row, int col){
// use std::queue std::vector std::deque will slow the program down greatly
float d1, d2, alpha, angle;
int fromIndX, fromIndY, thisIndX, thisIndY;
bool lineCountFlag[N_SCAN] = {false};
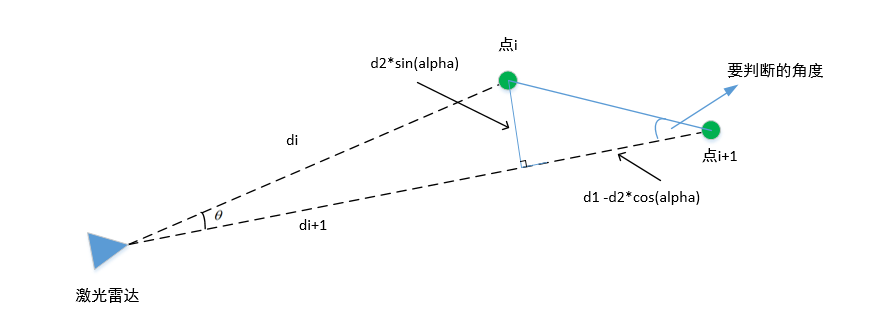
d1 d2 是距离 alpha 是激光束间的夹角 angle是判断角度
queueIndX[0] = row;
queueIndY[0] = col;
int queueSize = 1;
int queueStartInd = 0;
int queueEndInd = 1;
BFS的队列,这里队列把行和列分布设置了一个队列,行和列构成一个点元素。
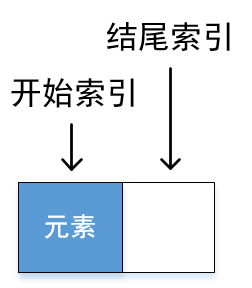
- queueSize 初始化队列的长度为1
- queueStartInd 开始索引 queueEndInd 结束索引

当前队列是这样的:
后面开始BFS操作

while(queueSize > 0){
判断队列的长度,当队列长度等于0,即遍历结束
fromIndX = queueIndX[queueStartInd];
fromIndY = queueIndY[queueStartInd];
--queueSize;
++queueStartInd;
首先取出队首的元素
队列长度减1
队列开始索引加1
labelMat.at<int>(fromIndX, fromIndY) = labelCount;
进行点云聚类的标记
labelCount就是聚类的id标签
然后开始遍历邻接顶点
for (auto iter = neighborIterator.begin(); iter != neighborIterator.end(); ++iter){
neighborIterator的定义是这样的:

[-1 0 ] [0 1] [0 -1] [1 0] 就是上下左右
//取出邻接点的 坐标
thisIndX = fromIndX + (*iter).first;
thisIndY = fromIndY + (*iter).second;
取出邻接点的 坐标
if (thisIndX < 0 || thisIndX >= N_SCAN)
continue;
垂直方向上,上下边界点不作为邻接
if (thisIndY < 0)
thisIndY = Horizon_SCAN - 1;
if (thisIndY >= Horizon_SCAN)
thisIndY = 0;
水平方向上,左右边界点为邻接
if (labelMat.at<int>(thisIndX, thisIndY) != 0)
continue;
判读该点是否被访问过,如果被访问过,或者是地面点等,该值就不是0
d1 = std::max(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));
d2 = std::min(rangeMat.at<float>(fromIndX, fromIndY),
rangeMat.at<float>(thisIndX, thisIndY));
取出这两点的d1和d2 ,d1是长的一边,d2是短的一边
if ((*iter).first == 0)
alpha = segmentAlphaX;
else
alpha = segmentAlphaY;
根据邻接点是垂直方向和是水平方向设置 激光束夹角
垂直方向是 2°
水平方向是 0.2°
angle = atan2(d2*sin(alpha), (d1 -d2*cos(alpha)));
计算要判断的角度
这个公式要回归到这个图了:
//如果角度大于阈值 阈值为60度 则认为是一个聚类
if (angle > segmentTheta){
//把该点加入队列
queueIndX[queueEndInd] = thisIndX;
queueIndY[queueEndInd] = thisIndY;
++queueSize;//队列长度增加1
++queueEndInd;//队列末尾索引加1
//给该点付上标签
labelMat.at<int>(thisIndX, thisIndY) = labelCount;
lineCountFlag[thisIndX] = true;//该行有被处理
//本次聚类的结果
allPushedIndX[allPushedIndSize] = thisIndX;
allPushedIndY[allPushedIndSize] = thisIndY;
++allPushedIndSize;
}
}
}
上面的部分都在一个while循环里面,直至队列的元素为0,代表本次作为开始点的然后BFS的点都被遍历到了,只有角度满足要求的才被加到队列中,所以被遍历的点都是那个点的聚类点
bool feasibleSegment = false;//初始化聚类是否有效 初始化为无效
if (allPushedIndSize >= 30)
feasibleSegment = true;
如果聚类点数大于30,即说明该聚类成功
else if (allPushedIndSize >= segmentValidPointNum){
int lineCount = 0;
for (size_t i = 0; i < N_SCAN; ++i)
if (lineCountFlag[i] == true)
++lineCount;
if (lineCount >= segmentValidLineNum)
feasibleSegment = true;
}
点数小于30,再做次判断,因为垂直方向,角分辨率较大,如果物体垂直,那么出现的点则会比较少,判断垂直方向上出现的聚类次数,如过大于阈值,认为聚类成功,代码中阈值为3
if (feasibleSegment == true){//如果聚类成功 将标签加1
++labelCount;
}
如果聚类成功 将标签加1
else{ // segment is invalid, mark these points
for (size_t i = 0; i < allPushedIndSize; ++i){
labelMat.at<int>(allPushedIndX[i], allPushedIndY[i]) = 999999;
}
}
如果 聚类失败,将聚类失败的点 打上标签 999999
以上完成了labelComponents函数的代码,将一帧里面可以聚类的点附上标签,不可以聚类的点付上999999.
然后可以回到cloudSegmentation函数中
for (size_t i = 0; i < N_SCAN; ++i) {
segMsg.startRingIndex[i] = sizeOfSegCloud-1 + 5;
for (size_t j = 0; j < Horizon_SCAN; ++j) {//遍历所有点
遍历所有点
if (labelMat.at<int>(i,j) > 0 || groundMat.at<int8_t>(i,j) == 1){//如果该点是有效点
// outliers that will not be used for optimization (always continue)
if (labelMat.at<int>(i,j) == 999999){//该点是一个没有聚类的噪点
if (i > groundScanInd && j % 5 == 0){//简单的过滤
outlierCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);//将该点加入噪点的点云中
continue;
}else{
continue;
}
}
// majority of ground points are skipped
if (groundMat.at<int8_t>(i,j) == 1){//如果该点是地面点
if (j%5!=0 && j>5 && j<Horizon_SCAN-5)
continue;//每5个点采一个点
}
// mark ground points so they will not be considered as edge features later
segMsg.segmentedCloudGroundFlag[sizeOfSegCloud] = (groundMat.at<int8_t>(i,j) == 1);//标志地面点
// mark the points' column index for marking occlusion later
segMsg.segmentedCloudColInd[sizeOfSegCloud] = j;
// save range info
segMsg.segmentedCloudRange[sizeOfSegCloud] = rangeMat.at<float>(i,j);
// save seg cloud
segmentedCloud->push_back(fullCloud->points[j + i*Horizon_SCAN]);
// size of seg cloud
++sizeOfSegCloud;
}
将噪声点做简单过滤,加入噪声点云
标记地面点
//可视化 聚类的点和 地面点
if (pubSegmentedCloudPure.getNumSubscribers() != 0){
for (size_t i = 0; i < N_SCAN; ++i){
for (size_t j = 0; j < Horizon_SCAN; ++j){
if (labelMat.at<int>(i,j) > 0 && labelMat.at<int>(i,j) != 999999){
segmentedCloudPure->push_back(fullCloud->points[j + i*Horizon_SCAN]);
segmentedCloudPure->points.back().intensity = labelMat.at<int>(i,j);
}
}
}
}
可视化 聚类的点
gazebo测试
gazebo的场景如下:
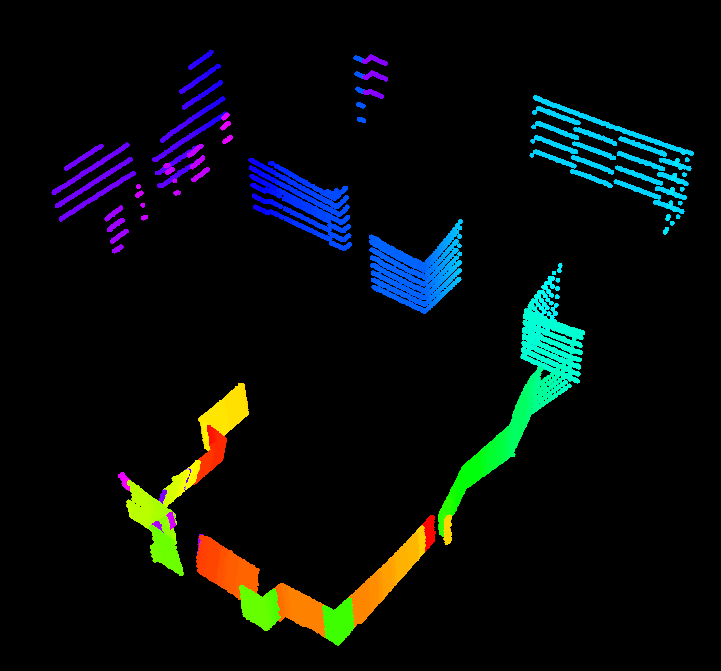
一帧激光雷达点云如下:

没有聚类的点如下:

聚类后的点如下:

- 点赞
- 收藏
- 关注作者
评论(0)