无主复制系统(1)-节点故障时写DB

单主、多主复制思路都是:客户端向一个主节点发写请求,而DB系统负责将写请求复制到其他副本。主节点决定写顺序,从节点按相同顺序应用主节点发送的写日志。
某些数据存储系统采用不同设计:放弃主节点,允许任何副本直接接受客户端的写。最早的复制数据系统就是无主节点的(或称之为去中心复制、无中心复制),但后来在关系数据库主导时代,这个想法几乎被忘却。在亚马逊将其用于其内部的Dynamo系统[^vi]后,它再一次成为流行的DB架构。 Riak,Cassandra和Voldemort都是由Dynamo启发的无主复制模型的开源数据存储,所以这类数据库也被称为Dynamo风格。
[^vi]: Dynamo不适用于Amazon以外的用户。 令人困惑的是,AWS提供了一个名为DynamoDB的托管数据库产品,它使用了完全不同的体系结构:它基于单领导者复制。
在一些无主实现中,客户端直接将写请求发到多副本,而另一些实现中,有一个协调者(coordinator)节点代表客户端进行写入,但与主节点的数据库不同,协调者不负责维护写入顺序。这种设计差异对DB使用方式有深远影响。
4.1 节点故障时写DB
假设三副本DB,其中一个副本当前不可用,或许正在重启以安装系统更新。在主节点复制模型下,若要继续处理写,则则需执行故障切换。
无主模型,则不存在这样的切换。
图-10:客户端(用户1234)将写请求并行发送到三副本,两个可用副本接受写,而不可用的那个副本无法处理。假设三副本的两个成功确认写,用户1234收到两个确定响应后,即可认为写成功。完全可以忽略其中一个副本无法写入的情况。
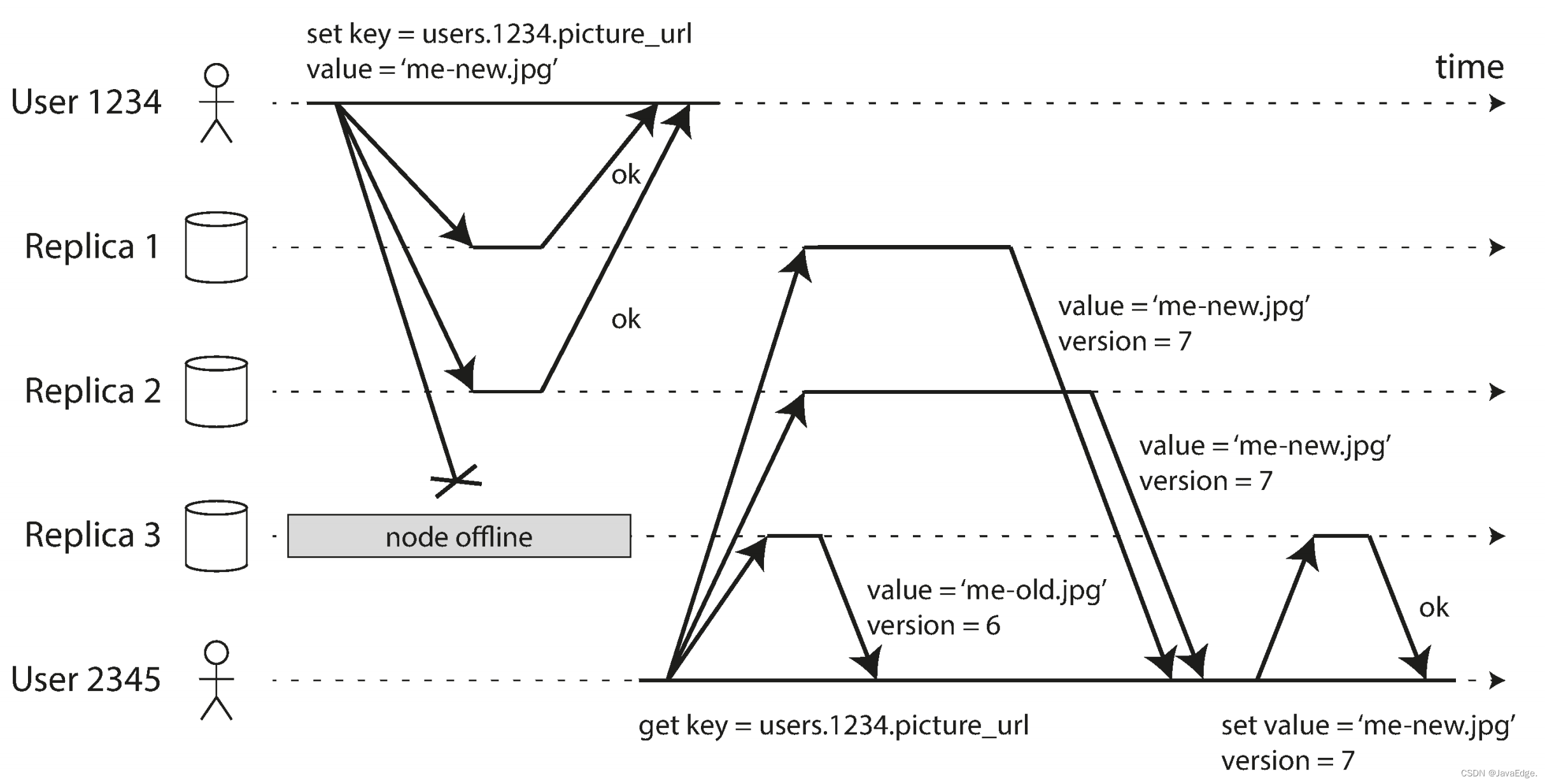
失效节点重新上线,而客户端开始读取它。节点失效期间发生的任何写入在该节点都尚未同步,因此读取可能得到过期数据。
为解决该问题,当一个客户端从DB读数据时,它不是向1个副本发送请求,而是并行发送到多副本。客户端可能会从不同节点获得不同响应,即来自一个节点的最新值和来自另一个节点的旧值。可利用版本号确定哪个值更新。
4.1.1 读修复和反熵
复制模型应确保所有数据最终复制到所有副本。在一个失效节点重新上线后,它如何赶上错过的写入呢?
Dynamo风格的数据存储系统常机制:
读修复(Read repair)
当客户端并行读取多副本时,可检测到过期的返回值。如图-10,用户2345获得来自R3的版本6,而从副本1和2得到版本7。客户端可判断副本3是过期值,然后将新值写入该副本。适用于读密集场景
反熵过程(Anti-entropy process)
一些数据存储有后台进程,不断查找副本之间的数据差异,将任何缺少的数据从一个副本复制到另一个副本。和基于主节点复制的复制日志不同,此反熵过程不保证任何特定的顺序复制写入,并且会引入明显的同步滞后
并非所有系统都实现这俩方案。如Voldemort目前无反熵过程。若无反熵过程,由于【读修复】只在发生读取时才可能执行修复,那些很少访问的数据有可能在某些副本中已丢失而无法再检测到,从而降低了写的持久性。

- 点赞
- 收藏
- 关注作者
评论(0)