理解卷积神经网络中的权值共享

【摘要】 首先介绍单层网络实行的权重共享袁力介绍简单从共享的角度来说:权重共享即filter的值共享卷积神经网络两大核心思想:1.网络局部连接(Local Connectivity)2.卷积核参数共享(Parameter Sharing)两者的一个关键作用就是减少参数数量,使运算变得简洁、高效,能够在超大规模数据集上运算。下面来用最直观的图示,来阐明两者的作用。CNN的正确打开方式,如下所示概括为:...
首先介绍单层网络实行的权重共享袁力介绍
简单从共享的角度来说:权重共享即filter的值共享
卷积神经网络两大核心思想:
1.网络局部连接(Local Connectivity)
2.卷积核参数共享(Parameter Sharing)
两者的一个关键作用就是减少参数数量,使运算变得简洁、高效,能够在超大规模数据集上运算。
下面来用最直观的图示,来阐明两者的作用。
CNN的正确打开方式,如下所示

概括为:一个 的卷积核在图像上扫描,进行特征提取。通常
的卷积核在图像上扫描,进行特征提取。通常 ,
, ![[公式]](https://img-blog.csdnimg.cn/20200704172851630.png) ,
, ![[公式]](https://img-blog.csdnimg.cn/2020070417290117.png) 的卷积核较为常用,如果channels为 [公式] 的话(32,64是较为常用的通道数),那么参数总量为
的卷积核较为常用,如果channels为 [公式] 的话(32,64是较为常用的通道数),那么参数总量为 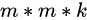 。
。
- 不进行parameter sharing
如果不用parameter sharing实现上图的运算,卷积核结构就会变成下图所示

这个是不难发现:卷积核的参数数量与图像像素矩阵的大小保持一致,即
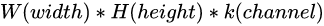
例如:Inception V3的输入图像尺寸是192192的,**如果把第一层3332的卷积核去掉参数共享,那么参数数目就会变成192192*32,约为120万个参数,是原来288个参数的50万倍。**
- 不进行local connectivity
如果不用局部连接,那当然就是全连接网络了(fully connect),即每个元素单元与隐层的神经原进行全连接,网络结构如下所示。

此时参数量变为 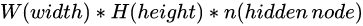 ,因为像素矩阵很大,所以也会选择较多的隐含层节点,这时一个单隐层的参数数目通常就超过了1千万个,导致网络很难进行训练。
,因为像素矩阵很大,所以也会选择较多的隐含层节点,这时一个单隐层的参数数目通常就超过了1千万个,导致网络很难进行训练。
以下是pytorch对多层网络实行的权重共享代码
import torch
import torch.nn as nn
import random
import matplotlib.pyplot as plt
# 绘制loss曲线
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'], loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
class DynamicNet(nn.Module):
def __init__(self, D_in, H, D_out):
super(DynamicNet, self).__init__()
self.input_linear = nn.Linear(D_in, H)
self.middle_linear = nn.Linear(H, H)
self.output_linear = nn.Linear(H, D_out)
def forward(self, x):
h_relu = self.input_linear(x).clamp(min=0)
# 重复利用Middle linear模块
for _ in range(random.randint(0, 3)):
h_relu = self.middle_linear(h_relu).clamp(min=0)
y_pred = self.output_linear(h_relu)
return y_pred
# N是批大小;D是输入维度
# H是隐藏层维度;D_out是输出维度
N, D_in, H, D_out = 64, 1000, 100, 10
# 模拟训练数据
x = torch.randn(N, D_in)
y = torch.randn(N, D_out)
model = DynamicNet(D_in, H, D_out)
criterion = nn.MSELoss(reduction='sum')
# 用平凡的随机梯度下降训练这个奇怪的模型是困难的,所以我们使用了momentum方法。
optimizer = torch.optim.SGD(model.parameters(), lr=1e-4, momentum=0.9)
loss_list = []
for t in range(500):
# 前向传播
y_pred = model(x)
# 计算损失
loss = criterion(y_pred, y)
loss_list.append(loss.item())
# 清零梯度,反向传播,更新权重
optimizer.zero_grad()
loss.backward()
optimizer.step()
plot_curve(loss_list)

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)