李宏毅《机器学习》丨2. Regression(回归)

一、回归(Regression)
回归(Regression):找到一个函数Function,通过输入一个特征 ,输出一个数值 。
应用举例
-
股市预测(Stock market forecast)
-
自动驾驶(Self-driving Car)
-
商品推荐(Recommendation)
-
Pokemon精灵攻击力预测(Combat Power of a pokemon):
二、模型步骤
2.1 模型假设 - 线性模型
- 一元线性模型(单个特征)
模型表示:
- 多元线性模型(多个特征)
模型表示:
- :各种特征(fetrure)
- :各个特征的权重
- b:偏移量
2.2 模型评估 - 损失函数
单个特征: 。
定义 是进化前的CP值, 为进化后的CP值, 所代表的的是真实值。
收集10组真实值,有了这些真实的数据,那我们怎么衡量模型的好坏呢?从数学的角度来讲,我们使用距离。求【进化后的CP值】与【模型预测的CP值】差,来判定模型的好坏。也就是使用损失函数(Loss function) 来衡量模型的好坏。

▲ 损失函数(Loss Function)
将 和 在二维坐标中展示
- 图中每一个点代表着一个模型对应的 和 ;
- 颜色越深代表模型更优。
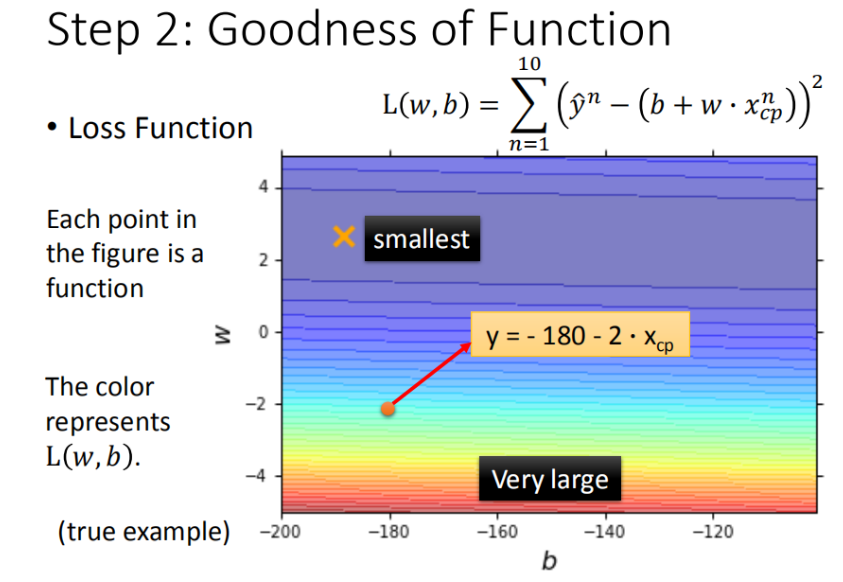
▲ w 和 b 在二维坐标中展示
2.3 模型优化 - 梯度下降
单个特征: 。
如何筛选出最优模型(即找出使得 Loss Function 最小的 和 )
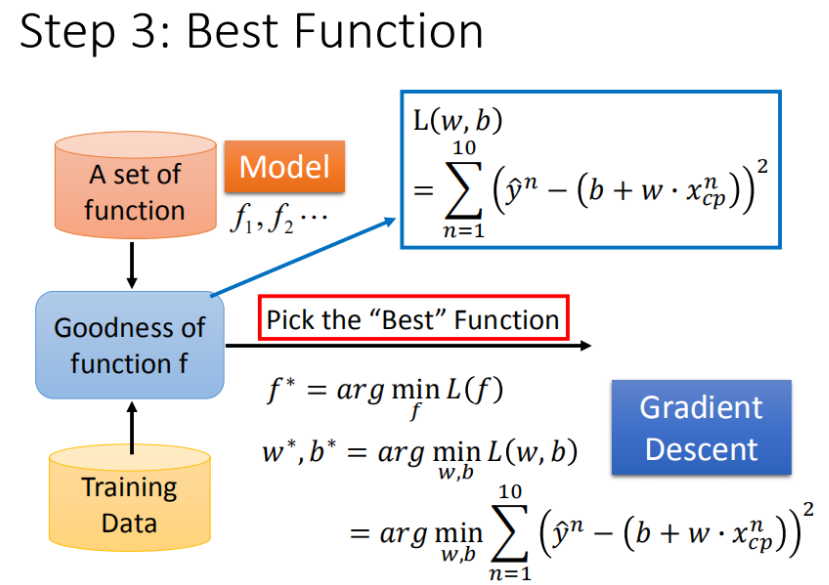
▲ 定义f*
- 先从最简单的只有一个参数 入手,定义
步骤1:随机选取一个
步骤2:计算微分,也就是当前的斜率,根据斜率来判定移动的方向
- 大于0向右移动(增加ww)
- 小于0向左移动(减少ww)
步骤3:根据学习率移动
重复步骤2和步骤3,直到找到最低点
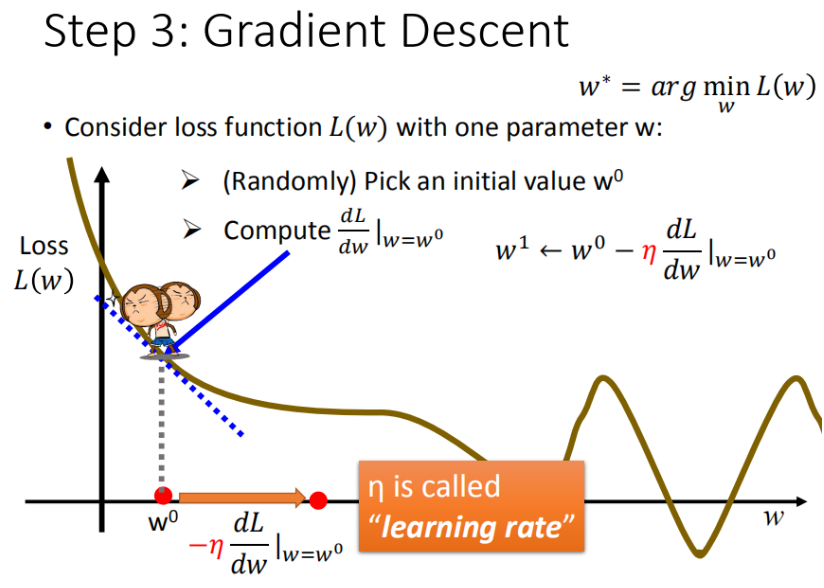
▲ 梯度下降过程
- 对于两个参数 和 ,过程与上述的一个参数类似,需要做的也是偏微分。

▲ 两个参数偏微分过程
梯度下降算法在现实世界中面临的挑战
- 问题1:当前最优(Stuck at local minima)
- 问题2:等于0(Stuck at saddle point)
- 问题3:趋近于0(Very slow at the plateau)
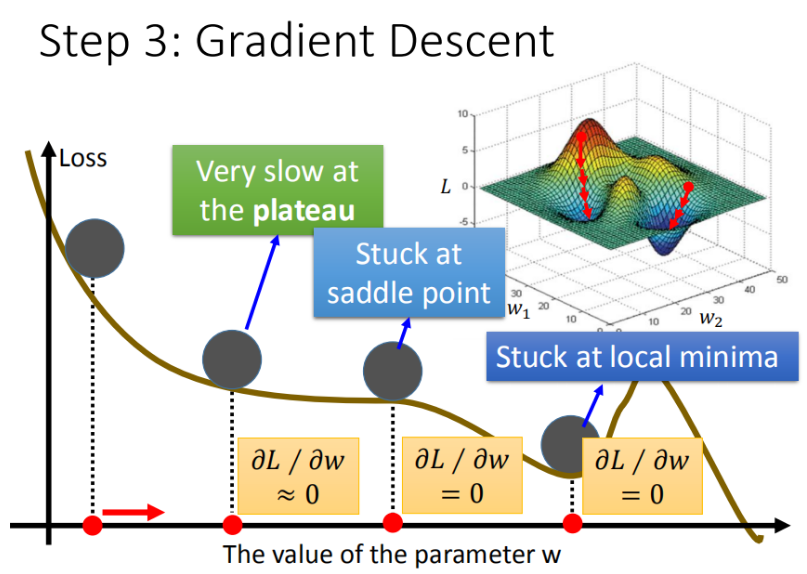
▲ 梯度下降面临的问题
在线性模型里面都是一个碗的形状(山谷形状),梯度下降基本上都能找到最优点,但是再其他更复杂的模型里面,就会遇到 问题2 和 问题3 。
验证模型好坏
使用训练集和测试集的平均误差来验证模型的好坏。
三、过拟合(Overfitting)
在简单的模型基础上,可以进行优化,选择更复杂的模型(一元N次线性模型),或者说使用多项式来拟合。
如果我们选择较高次方的模型,在训练集上面表现更为优秀的模型,在测试集上效果可能反而变差了。这就是模型在训练集上过拟合的问题。
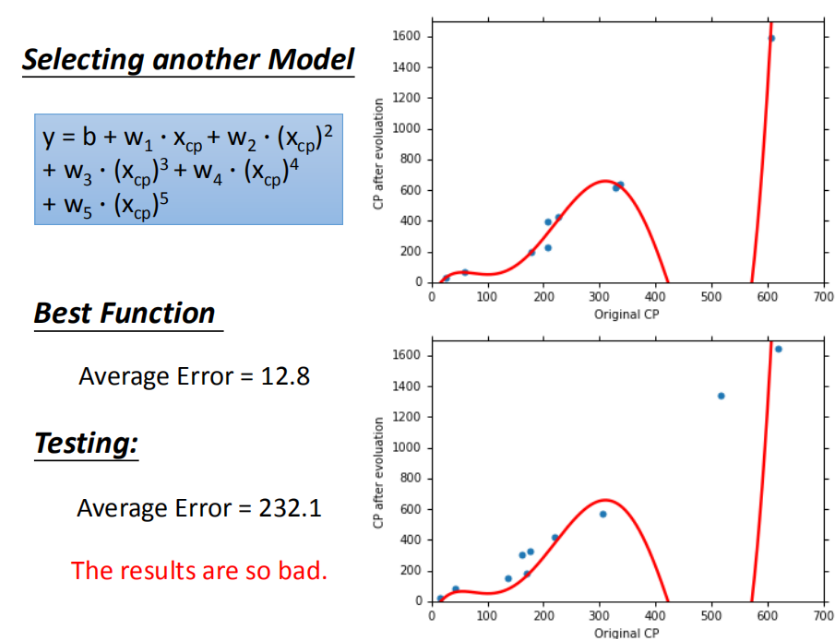
▲ 过拟合(Overfitting)的问题
四、正则化(Regularization)
对于更多特征,但是权重 可能会使某些特征权值过高,仍旧导致overfitting,可以加入正则化。

▲ 正则化(Regularization)
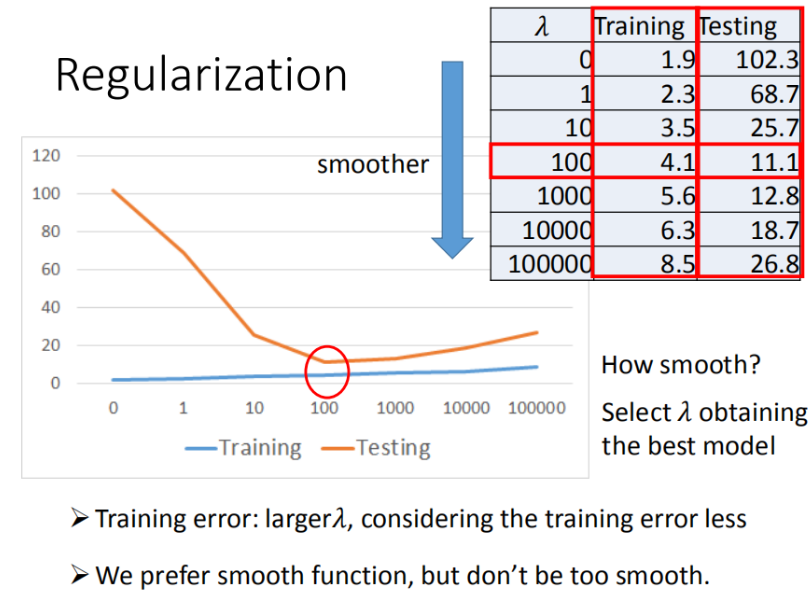
▲调节 λ 获得最好的模型
五、总结
Datawhale组队学习,李宏毅《机器学习》Task2. Regression(回归),主要包括回归的定义、创建模型的步骤、如何优化模型、优化模型过程中可能出现的问题以及使用正则化来解决过拟合的问题。

- 点赞
- 收藏
- 关注作者
评论(0)