精通Java事务编程(3)-弱隔离级别之快照隔离和可重复读

表面看,RC已满足事务所需的一切特征:支持中止(原子性),防止读取不完整的事务结果,并防止并发写的混乱。这点很关键!为我们的开发省去一大堆麻烦。
但此隔离级别仍有很多地方可能产生并发错误。如图-6说明RC可能发生的问题。
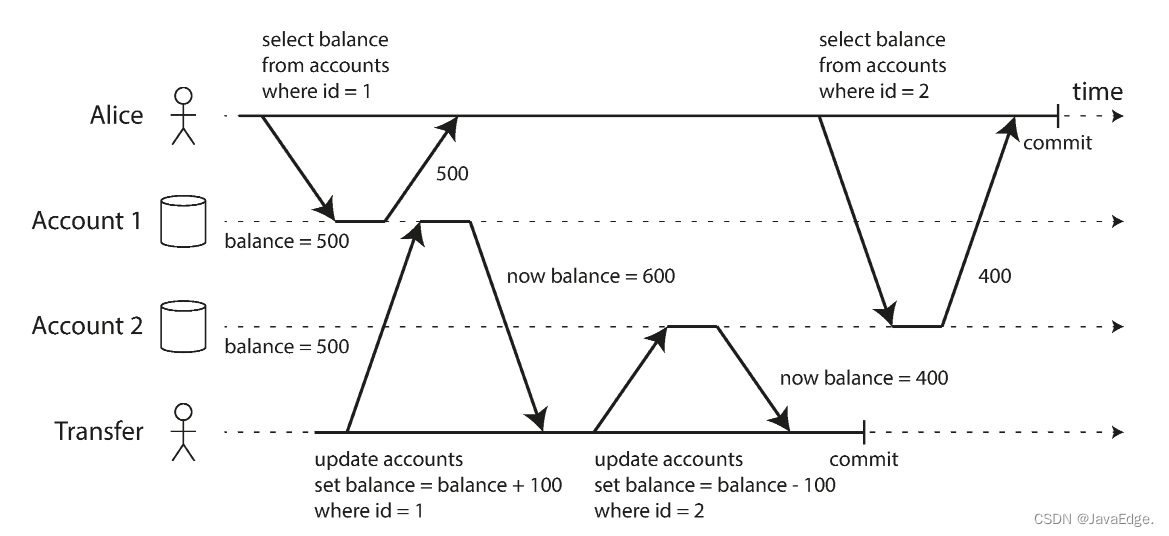
Alice在银行有1000存款,分为两个账户,每个500。现有一笔转账交易从账户1转移100到账户2。若她在提交转账请求后、银行DB系统执行转账的过程中间,查看两个账户的余额,她可能看到账号2在收到转账前的余额(500),和账户1在完成转账之后的余额(400)。对Alice,貌似她的账户总共只有900,100消失!
这种异常就是不可重复读(nonrepeatable read)或读倾斜(read skew):若Alice在交易结束时再读取账户1的余额,将看到和她之前的查询看到的不同的值(600)。RC下,不可重复读被认为是可接受的:Alice 看到的帐户余额的确都是账户当时的最新值。
术语 倾斜(skew) 这词有些滥用:以前使用它是因为热点的不平衡工作量,而在此意味着异常时序。
Alice案例不是长期持续的问题,几s后当她刷新银行页面,可能就看到一致的帐户余额。但有的场景不能容忍这种暂时的不一致:
-
备份
备份需复制整个DB,大型DB可能需数h。备份进程运行时,DB仍会接受写。因此镜像备份里可能包含一些旧版本数据和一些新版本数据。从这样的备份中恢复,最终就会导致永久性的不一致(如那些消失的存款)
-
分析查询和完整性检查
有时查询会扫描几乎大半个DB。这类查询在分析中很常见,也可能是定期的数据完整性检查(监视数据损坏情况)。若这些查询在不同时间点观察DB,则可能会返回无意义的结果
【快照隔离】是这类问题最常见解决方案。每个事务都从DB的一致性快照(consistent snapshot)中读取,即事务一开始所看到是最近提交的数据。即使这些数据随后被另一个事务更改,每个事务也只能看到该特定时间点的旧数据。
快照隔离对长时间运行的只读查询(如备份和分析)很有用。若数据在查询执行的同时变化,则很难理解查询结果的物理含义。而若查询的是DB在某特定时间点冻结时的一致性快照,则查询结果含义明确。
快照隔离很流行:PostgreSQL、InnoDB引擎的MySQL、Oracle、SQL Server 等都支持。
实现快照隔离
类似RC,快照隔离的实现通常使用写锁防止脏写,正在进行写入的事务会阻止另一个事务修改同一个对象。但读取则不无需加锁。性能角度,快照隔离的关键点:读不会阻塞写,写不会阻塞读。这允许DB可在正常处理写入的同时,在一致性快照上执行长时间的只读查询,且两者之间没有任何锁竞争。
为实现快照隔离,DB用类似图-4防脏读但却更通用的机制。考虑到多个正在进行的事务可能在不同时间点查看数据库状态,所以DB保留对象的多个不同的提交版本,所以这种技术也称为多版本并发控制(MVCC, multi-version concurrency control)。
若只是为提供RC,而非完整的快照隔离,则只保留对象的两个版本即可:
- 已提交的旧版本
- 尚未提交的新版本
所以,支持快照隔离的存储引擎一般也直接使用MVCC实现RC。典型做法:
- 在RC下,为每个不同的查询单独创建一个快照
- 而快照隔离则是对整个事务使用相同的一个快照。
图-7说明如何在 PostgreSQL 中实现基于 MVCC 的快照隔离(其他实现基本类似)。当事务开始时,首先赋予一个唯一、单调递增 [^vii] 的事务ID(txid)。每当事务向DB写入新内容,所写入的数据都会被标记写入者的事务ID。
[^vii]: 事务ID是32位整数,所以大约在40亿次事务后溢出。 PostgreSQL 的 Vacuum 过程会清理老旧的事务 ID,确保事务 ID 溢出(回卷)不会影响到数据。
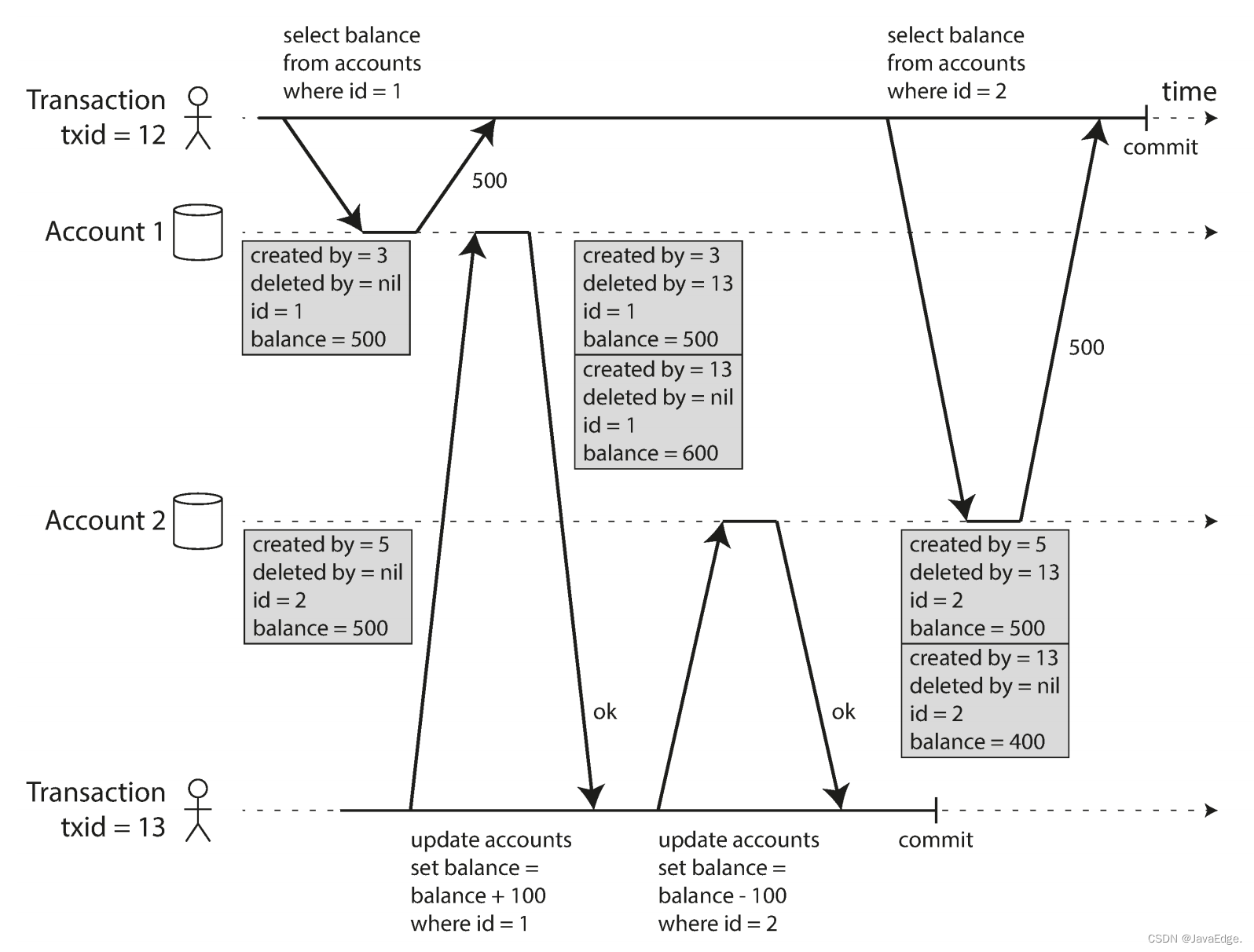 表中的每行都有个
表中的每行都有个 created_by 字段,其中包含将该行插入到表中的的事务ID。都有个 deleted_by 字段,最初是空的。如某事务删除了一行,那么该行实际上并未从数据库中删除,而是通过将 deleted_by 字段设置为请求删除的事务的 ID 来标记为删除。稍后时间,当确定没有事务可以再访问已删除的数据时,数据库中的gc过程会将所有带有删除标记的行移除,并释放其空间。
这样的一笔UPDATE 操作在内部会被转换为一个 DELETE 和一个 INSERT 。图-7中,事务13从账户2扣100,将余额从 500改为400。account 表会出现两条账户2的记录:
- 余额为500的行被标记为被事务13删除
- 余额为400的行由事务13创建
一致性快照的可见性规则
当事务读DB时,通过事务ID可决定哪些对象可见,哪些不可见。要想对上层应用维护好快照的一致性,需仔细定义可见性规则:
- 每个事务开始时,DB列出当时所有当时还在进行中(即尚未提交或中止)的其它事务,然后忽略这些事务完成的部分写入(尽管之后可能会被提交),即不可见
- 所有中止事务所做的任何修改全部不可见
- 较晚事务ID(即晚于当前事务开始)所做的任何修改不可见,而不管这些事务是否已完成提交
- 此外的所有其他写入都对应用查询可见
以上规则适用于创建、删除操作。图-7中,当事务12从账户2读时,会看到500余额,因为500余额的删除是由事务13完成的(根据规则 3,事务12看不到事务13执行的删除),同理400美元记录的创建也不可见。
即若如下两个条件都成立,则该数据对象对事务可见:
- 读事务开始的时刻,创建该对象的事务已完成提交
- 对象未被标记为删除或即使被标记为删除了,但删除事务在当前读事务开始时还没有完成提交
长时间运行的事务可能会使用快照很长时间,其他事务角度,它可能在持续访问正在被覆盖或删除的内容。由于没有就地更新,而是每次修改总创建一个新版本,因此DB可以以较小运行代价来维护一致性快照。
索引和快照隔离
多版本DB如何支持索引?一种方案是索引直接指向对象所有版本,并且需要索引查询过滤掉对当前事务不可见的对象版本。当后台的GC进程决定删除某个事务不可见的旧对象版本时,相应索引条目也随之删除。
实践中,许多细节决定了多版本并发控制的性能,如:
- 可将同一对象的不同版本放入同一内存页,PostgreSQL如此优化可避免更新索引
- CouchDB、Datomic 和 LMDB使用另一种方案。虽然也使用B树,但采用追加/写时复制(append-only/copy-on-write),当需要更新时,不会修改现有的页,而总是创建一个新的修改副本,拷贝必要的内容,然后让父结点或递归向上直到树root都指向新创建的结点。那些不受更新影响的页面都无需复制,保持不变并被父结点所指向。
这种使用追加的B树,每个写入事务(或一批事务)都会创建一个新的B 树,当创建时,从该特定树根生长的树就是该时刻DB的一致性快照。这时就没必要根据事务ID再去过滤对象,每个写入都会修改现有的B树,因为之后的 询可以直接作用于特定快照B-tree(有利于查询性能)。采用这种方案依然需要后台进程来执行压缩和GC。
可重复读与命名混淆
快照隔离对只读事务特别有效。但DB实现用不同名字来称呼:
- Oracle 中称为可串行化(Serializable)
- PostgreSQL 和 MySQL 中称为可重复读(repeatable read)
命名混淆原因是SQL标准未定义快照隔离,而仍是基于System R 1975年定义的隔离级别,那时还没快照隔离。而定义了 可重复读,表面看起来接近快照隔离。 所以PostgreSQL 和 MySQL 称快照隔离级别为可重复读(repeatable read),这符合标准要求。
但SQL标准对隔离级别的定义存在缺陷的,模糊,不精确,做不到独立于实现。有几个DB实现了可重复读,但它们实际提供的保证差异很大。IBM DB2 使用 “可重复读” 实现可串行化级别的隔离。
所以导致结果,无人真正知道可重复读到底啥意思。

- 点赞
- 收藏
- 关注作者
评论(0)