GPU运算能力对(2022.4.5更新)

0. 简介
实验室最近出了一款芯片,想进行指标的对比,现在ai芯片加速器我记得峰值运算能力effiency已经达到了Tops(一般也就几或者十几,effiency一般分为ops/w,ops/mm^2,ops/s等等),于是想看看GPU的运算能力,进行相应参照。
大多数网站都会贴这一张图,其实也没有错,就是不够细致,我们更想知道它的具体ops登记,而不是宽泛的level级别的计算能力数字。nvidia的显卡越来越强,CUDA运算核心越来越多,甚至也开始了他自家的深度学习学院DLI(赚钱),它强大的并行性,使得现在显卡GTX系列,RTX3090,丽台,Tesla系列,P40系列,K4200系列以及TITAN X/V,TITAN XP等等产品一个个成为热点,狂赚一波。
1. CUDA GPUs
最新信息见:https://developer.nvidia.com/cuda-gpus
1) CUDA-Enabled Tesla Products
Tesla Workstation Products
| GPU | Compute Capability |
|---|---|
| Tesla K80 | 3.7 |
| Tesla K40 | 3.5 |
| Tesla K20 | 3.5 |
| Tesla C2075 | 2.0 |
| Tesla C2050/C2070 | 2.0 |
Tesla Data Center Products
| GPU | Compute Capability |
|---|---|
| NVIDIA A100 | 8.0 |
| NVIDIA A40 | 8.6 |
| NVIDIA A30 | 8.0 |
| NVIDIA A10 | 8.6 |
| NVIDIA A16 | 8.6 |
| NVIDIA A2 | 8.6 |
| NVIDIA T4 | 7.5 |
| NVIDIA V100 | 7.0 |
| Tesla P100 | 6.0 |
| Tesla P40 | 6.1 |
| Tesla P4 6. | 1 |
| Tesla M40 | 5.2 |
| Tesla M40 | 5.2 |
| Tesla K80 | 3.7 |
| Tesla K40 | 3.5 |
| Tesla K20 | 3.5 |
| Tesla K10 | 3.0 |
2) CUDA-Enabled Quadro Products
Quadro Desktop Products
| GPU | Compute Capability |
|---|---|
| RTX A6000 | 8.6 |
| RTX A5000 | 8.6 |
| RTX A4000 | 8.6 |
| T1000 | 7.5 |
| T600 | 7.5 |
| T400 | 7.5 |
| Quadro RTX 8000 | 7.5 |
| Quadro RTX 6000 | 7.5 |
| Quadro RTX 5000 | 7.5 |
| Quadro RTX 4000 | 7.5 |
| Quadro GV100 | 7.0 |
| Quadro GP100 | 6.0 |
| Quadro P6000 | 6.1 |
| Quadro P5000 | 6.1 |
| Quadro M6000 24GB | 5.2 |
| Quadro M6000 | 5.2 |
| Quadro K6000 | 3.5 |
| Quadro M5000 | 5.2 |
| Quadro K5200 | 3.5 |
| Quadro K5000 | 3.0 |
| Quadro M4000 | 5.2 |
| Quadro K4200 | 3.0 |
| Quadro K4000 | 3.0 |
| Quadro M2000 | 5.2 |
| Quadro K2200 | 5.0 |
| Quadro K2000 | 3.0 |
| Quadro K2000D | 3.0 |
| Quadro K1200 | 5.0 |
| Quadro K620 | 5.0 |
| Quadro K600 | 3.0 |
| Quadro K420 | 3.0 |
| Quadro 410 | 3.0 |
| Quadro Plex 7000 | 2.0 |
Quadro Mobile Products
| GPU | Compute Capability |
|---|---|
| RTX A5000 | 8.6 |
| RTX A4000 | 8.6 |
| RTX A3000 | 8.6 |
| RTX A2000 | 8.6 |
| RTX 5000 | 7.5 |
| RTX 4000 | 7.5 |
| RTX 3000 | 7.5 |
| T2000 | 7.5 |
| T1200 | 7.5 |
| T1000 | 7.5 |
| T600 | 7.5 |
| T500 | 7.5 |
| P620 | 6.1 |
| P520 | 6.1 |
| Quadro P5200 | 6.1 |
| Quadro P4200 | 6.1 |
| Quadro P3200 | 6.1 |
| Quadro P5000 | 6.1 |
| Quadro P4000 | 6.1 |
| Quadro P3000 | 6.1 |
| Quadro P2000 | 6.1 |
| Quadro P1000 | 6.1 |
| Quadro P600 | 6.1 |
| Quadro P500 | 6.1 |
| Quadro M5500M | 5.2 |
| Quadro M2200 | 5.2 |
| Quadro M1200 | 5.0 |
| Quadro M620 | 5.2 |
| Quadro M520 | 5.0 |
| Quadro K6000M | 3.0 |
| Quadro M5500M | 5.0 |
| Quadro K5200M | 3.0 |
| Quadro K5100M | 3.0 |
| Quadro M5000M | 5.0 |
| Quadro K500M | 3.0 |
| Quadro K4200M | 3.0 |
| Quadro K4100M | 3.0 |
| Quadro M4000M | 5.0 |
| Quadro K3100M | 3.0 |
| Quadro M3000M | 5.0 |
| Quadro K2200M | 5.0 |
| Quadro K2100M | 3.0 |
| Quadro M2000M | 5.0 |
| Quadro K1100M | 3.0 |
| Quadro M1000M | 5.0 |
| Quadro K620M | 5.0 |
| Quadro K610M | 3.5 |
| Quadro M600M | 5.0 |
| Quadro K510M | 3.5 |
| Quadro M500M | 5.0 |
3) CUDA-Enabled NVS Products
Desktop Products
| GPU | Compute Capability |
|---|---|
| NVIDIA NVS 810 | 5.0 |
| NVIDIA NVS 510 | 3.0 |
| NVIDIA NVS 315 | 2.1 |
| NVIDIA NVS 310 | 2.1 |
Mobile Products
| GPU | Compute Capability |
|---|---|
| NVS 5400M | 2.1 |
| NVS 5200M | 2.1 |
| NVS 4200M | 2.1 |
4) CUDA-Enabled GeForce Products
GeForce Desktop Products
Mobile Products
| GPU | Compute Capability |
|---|---|
| Geforce RTX 3060 Ti | 8.6 |
| Geforce RTX 3060 | 8.6 |
| GeForce RTX 3090 | 8.6 |
| GeForce RTX 3080 | 8.6 |
| GeForce RTX 3070 | 8.6 |
| GeForce GTX 1650 Ti | 7.5 |
| NVIDIA TITAN RTX | 7.5 |
| GeForce GTX 2080TI | 7.5 |
| GeForce GTX 2080 | 7.5 |
| GeForce GTX 2070 | 7.5 |
| GeForce GTX 2060 | 7.5 |
| NVIDIA TITAN Xp | 6.1 |
| NVIDIA TITAN X | 6.1 |
| GeForce GTX 1080TI | 6.1 |
| GeForce GTX 1080 | 6.1 |
| GeForce GTX 1070 | 6.1 |
| GeForce GTX 1060 | 6.1 |
| GeForce GTX TITAN X | 5.2 |
| GeForce GTX TITAN Z | 3.5 |
| GeForce GTX TITAN Black | 3.5 |
| GeForce GTX TITAN | 3.5 |
| GeForce GTX 980 Ti | 5.2 |
| GeForce GTX 980 | 5.2 |
| GeForce GTX 970 | 5.2 |
| GeForce GTX 960 | 5.2 |
| GeForce GTX 950 | 5.2 |
| GeForce GTX 780 Ti | 3.5 |
| GeForce GTX 780 | 3.5 |
| GeForce GTX 770 | 3.0 |
| GeForce GTX 760 | 3.0 |
| GeForce GTX 750 Ti | 5.0 |
| GeForce GTX 750 | 5.0 |
| GeForce GTX 690 | 3.0 |
| GeForce GTX 680 | 3.0 |
| GeForce GTX 670 | 3.0 |
| GeForce GTX 660 Ti | 3.0 |
| GeForce GTX 660 | 3.0 |
| GeForce GTX 650 Ti BOOST | 3.0 |
| GeForce GTX 650 Ti | 3.0 |
| GeForce GTX 650 | 3.0 |
| GeForce GTX 560 Ti | 2.1 |
| GeForce GTX 550 Ti | 2.1 |
| GeForce GTX 460 | 2.1 |
| GeForce GTS 450 | 2.1 |
| GeForce GTS 450* | 2.1 |
| GeForce GTX 590 | 2.0 |
| GeForce GTX 580 | 2.0 |
| GeForce GTX 570 | 2.0 |
| GeForce GTX 480 | 2.0 |
| GeForce GTX 470 | 2.0 |
| GeForce GTX 465 | 2.0 |
| GeForce GT 740 | 3.0 |
| GeForce GT 730 | 3.5 |
| GeForce GT 730 DDR3,128bit | 2.1 |
| GeForce GT 720 | 3.5 |
| GeForce GT 705* | 3.5 |
| GeForce GT 640 (GDDR5) | 3.5 |
| GeForce GT 640 (GDDR3) | 2.1 |
| GeForce GT 630 | 2.1 |
| GeForce GT 620 | 2.1 |
| GeForce GT 610 | 2.1 |
| GeForce GT 520 | 2.1 |
| GeForce GT 440 | 2.1 |
| GeForce GT 440* | 2.1 |
| GeForce GT 430 | 2.1 |
| GeForce GT 430* | 2.1 |
5) CUDA-Enabled TEGRA /Jetson Products
GeForce Notebook Products
| GPU | Compute Capability |
|---|---|
| GeForce RTX 3080 | 8.6 |
| GeForce RTX 3070 | 8.6 |
| GeForce RTX 3060 | 8.6 |
| GeForce RTX 3050 Ti | 8.6 |
| GeForce RTX 3050 | 8.6 |
| GeForce GTX 2080 | 7.5 |
| GeForce GTX 2070 | 7.5 |
| GeForce GTX 2060 | 7.5 |
| GeForce GTX 1080 | 6.1 |
| GeForce GTX 1070 | 6.1 |
| GeForce GTX 1060 | 6.1 |
| GeForce GTX 980 | 5.2 |
| GeForce GTX 980M | 5.2 |
| GeForce GTX 970M | 5.2 |
| GeForce GTX 965M | 5.2 |
| GeForce GTX 960M | 5.0 |
| GeForce GTX 950M | 5.0 |
| GeForce 940M | 5.0 |
| GeForce 930M | 5.0 |
| GeForce 920M | 3.5 |
| GeForce 910M | 5.2 |
| GeForce GTX 880M | 3.0 |
| GeForce GTX 870M | 3.0 |
| GeForce GTX 860M | 3.0/5.0(**) |
| GeForce GTX 850M | 5.0 |
| GeForce 840M | 5.0 |
| GeForce 830M | 5.0 |
| GeForce 820M | 2.1 |
| GeForce 800M | 2.1 |
| GeForce GTX 780M | 3.0 |
| GeForce GTX 770M | 3.0 |
| GeForce GTX 765M | 3.0 |
| GeForce GTX 760M | 3.0 |
| GeForce GTX 680MX | 3.0 |
| GeForce GTX 680M | 3.0 |
| GeForce GTX 675MX | 3.0 |
| GeForce GTX 675M | 2.1 |
| GeForce GTX 670MX | 3.0 |
| GeForce GTX 670M | 2.1 |
| GeForce GTX 660M | 3.0 |
| GeForce GT 750M | 3.0 |
| GeForce GT 650M | 3.0 |
| GeForce GT 745M | 3.0 |
| GeForce GT 645M | 3.0 |
| GeForce GT 740M | 3.0 |
| GeForce GT 730M | 3.0 |
| GeForce GT 640M | 3.0 |
| GeForce GT 640M LE | 3.0 |
| GeForce GT 735M | 3.0 |
| GeForce GT 635M | 2.1 |
| GeForce GT 730M | 3.0 |
| GeForce GT 630M | 2.1 |
| GeForce GT 625M | 2.1 |
| GeForce GT 720M | 2.1 |
| GeForce GT 620M | 2.1 |
| GeForce 710M | 2.1 |
| GeForce 705M | 2.1 |
| GeForce 610M | 2.1 |
| GeForce GTX 580M | 2.1 |
| GeForce GTX 570M | 2.1 |
| GeForce GTX 560M | 2.1 |
| GeForce GT 555M | 2.1 |
| GeForce GT 550M | 2.1 |
| GeForce GT 540M | 2.1 |
| GeForce GT 525M | 2.1 |
| GeForce GT 520MX | 2.1 |
| GeForce GT 520M | 2.1 |
| GeForce GTX 485M | 2.1 |
| GeForce GTX 470M | 2.1 |
| GeForce GTX 460M | 2.1 |
| GeForce GT 445M | 2.1 |
| GeForce GT 435M | 2.1 |
| GeForce GT 420M | 2.1 |
| GeForce GT 415M | 2.1 |
| GeForce GTX 480M | 2.0 |
| GeForce 710M | 2.1 |
| GeForce 410M | 2.1 |
6) Tegra Mobile & Jetson Products
Tegra Mobile & Jetson Products
GeForce Notebook Products
| GPU | Compute Capability |
|---|---|
| Jetson AGX Xavier | 7.2 |
| Jetson Nano | 5.3 |
| Jetson TX2 | 6.2 |
| Jetson TX1 | 5.3 |
| Jetson TK1 | 3.2 |
| Tegra X1 | 5.3 |
| Tegra K1 | 3.2 |
Notes
(*) 仅OEM产品
(**) GeForce GTX860和GTX870有两个版本,具体取决于SKU,请与OEM联系以确定系统中的版本
2. GPU算力计算以及选择
计算能力换算
理论峰值 = GPU芯片数量GPU Boost主频核心数量*单个时钟周期内能处理的浮点计算次数
只不过在GPU里单精度和双精度的浮点计算能力需要分开计算,以最新的Tesla P100为例:
双精度理论峰值 = FP64 Cores * GPU Boost Clock * 2 = 1792 *1.48GHz*2 = 5.3 TFlops
单精度理论峰值 = FP32 cores * GPU Boost Clock * 2 = 3584 * 1.58GHz * 2 = 10.6 TFlop
TFLOPS
但是现在衡量计算速度的标准是TFLOPS**(每秒万亿次浮点运算),注意GPU它是浮点运算。
重点就是关注它的flops是怎么计算的。
这里先参考一下某博主写的粗浅见解:
https://blog.csdn.net/wesley_2013/article/details/11910117
- GPU设备的单精度计算能力的理论峰值计算公式:
单精度计算能力的峰值 = 单核单周期计算次数 × 处理核个数 × 主频
例如: 以GTX680为例, 单核一个时钟周期单精度计算次数为两次(一般都是2),处理核个数 为1536, 主频为1006MHZ,那他的计算能力的峰值P 为
P = 2 × 1536 × 1006MHZ = 3.09TFLOPS
这里1MHZ = 1000000HZ, 1T为1兆,也就是说,GTX680每秒可以进行超过3兆次的单精度运算。
同样,双精度的处理核为64个,不难算出,GTX680的双精度运算能力为0.13TFLOPS。
同理
- GPU设备的数据通信时间的计算公式:
通信时间 = 通信量 ÷ 通信速度
例如,单个处理核的输入数据以4个4byte为例,输出为1个4byte,GTX680所有处理核100%利用的情况下,通信量为5× 4 × 1536 byte,GTX680的通信速度为192…2GB/S,所以它的通信时间为
---------- 5× 4 × 1536 byte ÷ 192.2GB/S = 1.49e-7 s
如果这4个4byte的数据进行10次运算的话,以GTX680为例,他的主频为1006MHZ,也就是他每1e-9s为一个时钟周期,每个周期可进行两次单精度计算,也就是5个时钟周期即5e-9s可完成计算,为通信时间的几十分之一,故可忽略不计。所以,从内存访问看计算能力:
单精度计算能力 = 单核单精度符点计算次数 × 处理核个数 ÷ ( 通信时间 + 计算时间) 注:此处计算时间忽略不计
即 10 × 1536 ÷ 1.49e-7s = 103GFLOPS
即为普通PC10倍的计算速度。
- SP总数=TPC&GPC数量每个TPC中SM数量每个SM中的SP数量;
TPC和GPC是介于整个GPU和流处理器簇之间的硬件单元,用于执行CUDA计算。特斯拉架构硬件将SM组合成TPC(纹理处理集群),其中,TPC包含有纹理硬件支持(特别包含一个纹理缓存)和2个或3个SM,后面会有详细描述。费米架构硬件组则将SM组合为GPC(图形处理器集群),其中,每个GPU包含有一个光栅单元和4个SM。
- 单精度浮点处理能力=SP总数SP运行频率每条执行流水线每周期能执行的单精度浮点操作数;
该公式实质上是3部分相乘得到的,分别为计算单元数量、计算单元频率和指令吞吐量。
前两者很好理解,指令吞吐量这里是按照FMA(融合乘法和增加)算的,也就是每个SP,每周期可以有一条FMA指令的吞吐量,并且同时FMA因为同时计算了乘加,所以是两条浮点计算指令。
以及需要说明的是,并不是所有的单精度浮点计算都有这个峰值吞吐量,只有全部为FMA的情况,并且没有其他访存等方面的限制的情况下,并且在不考虑调度效率的情况下,才是这个峰值吞吐量。如果是其他吞吐量低的计算指令,自然达不到这个理论峰值。
- 双精度浮点处理能力=双精度计算单元总数SP运行频率每个双精度计算单元每周期能进行的双精度浮点操作数。
目前对于N卡来说,双精度浮点计算的单元是独立于单精度单元之外的,每个SP都有单精度的浮点计算单元,但并不是每个SP都有双精度的浮点单元。对于有双精度单元的SP而言,最大双精度指令吞吐量一样是在实现FMA的时候的每周期2条(指每周期一条双精度的FMA指令的吞吐量,FMA算作两条浮点操作)。
而具备双精度单元的SP数量(或者可用数量)与GPU架构以及产品线定位有关,具体为:
计算能力为1.3的GT200核心,第一次硬件支持双精度浮点计算,双精度峰值为单精度峰值的1/8,该核心目前已经基本退出使用。
GF100/GF110核心,有一半的SP具备双精度浮点单元,但是在geforce产品线中屏蔽了大部分的双精度单元而仅在tesla产品线中全部打开。代表产品有:tesla C2050,2075等,其双精度浮点峰值为单精度浮点峰值的一半;
geforce GTX 480,580,其双精度浮点峰值为单精度浮点峰值的大约1/8左右。
其他计算能力为2.1的Fermi核心,原生设计中双精度单元数量较少,双精度计算峰值为单精度的1/12。
kepler GK110核心,原生的双精度浮点峰值为单精度的1/3。而tesla系列的K20,K20X,K40他们都具备完整的双精度浮点峰值;geforce系列的geforce TITAN,此卡较为特殊,和tesla系列一样具备完整的双精度浮点峰值,geforce GTX780/780Ti,双精度浮点峰值受到屏蔽,具体情况不详,估计为单精度峰值的1/10左右。
其他计算能力为3.0的kepler核心,原生具备较少的双精度计算单元,双精度峰值为单精度峰值的1/24。
计算能力3.5的GK208核心,该卡的双精度效能不明,但是考虑到该核心定位于入门级别,大规模双精度计算无需考虑使用。
所以不同核心的N卡的双精度计算能力有显著区别,不过目前基本上除了geforce TITAN以外,其他所有geforce卡都不具备良好的双精度浮点的吞吐量,而本代的tesla K20/K20X/K40以及上一代的fermi核心的tesla卡是较好的选择。
GPU信息对比
1080TI
~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=0
~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024
batchCUBLAS Starting...
GPU Device 0: "GeForce GTX 1080 Ti" with compute capability 6.1
==== Running single kernels ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00037980 sec GFLOPS=5654.24
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00894690 sec GFLOPS=240.026
@@@@ dgemm test OK
==== Running N=10 without streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00294209 sec GFLOPS=7299.19
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.07993412 sec GFLOPS=268.657
@@@@ dgemm test OK
==== Running N=10 with streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00224590 sec GFLOPS=9561.78
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.05540895 sec GFLOPS=387.57
@@@@ dgemm test OK
==== Running N=10 batched ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00197387 sec GFLOPS=10879.6
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.05372214 sec GFLOPS=399.739
@@@@ dgemm test OK
Test Summary
0 error(s)
1080
liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ export CUDA_VISIBLE_DEVICES=1
liu@iridescent:~/NVIDIA_CUDA-8.0_Samples/7_CUDALibraries/batchCUBLAS$ ./batchCUBLAS -m1024 -n1024 -k1024
batchCUBLAS Starting...
GPU Device 0: "GeForce GTX 1080" with compute capability 6.1
==== Running single kernels ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00060892 sec GFLOPS=3526.7
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00993085 sec GFLOPS=216.244
@@@@ dgemm test OK
==== Running N=10 without streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00369406 sec GFLOPS=5813.35
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.09741306 sec GFLOPS=220.451
@@@@ dgemm test OK
==== Running N=10 with streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00317717 sec GFLOPS=6759.12
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.07991505 sec GFLOPS=268.721
@@@@ dgemm test OK
==== Running N=10 batched ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00302100 sec GFLOPS=7108.51
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.07566714 sec GFLOPS=283.807
@@@@ dgemm test OK
Test Summary
0 error(s)
Jetson
$ ./batchCUBLAS -m1024 -n1024 -k1024
batchCUBLAS Starting...
GPU Device 0: "NVIDIA Tegra X2" with compute capability 6.2
==== Running single kernels ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.00372291 sec GFLOPS=576.83
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x0000000000000000, 0) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.10940003 sec GFLOPS=19.6296
@@@@ dgemm test OK
==== Running N=10 without streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbf800000, -1) beta= (0x00000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.03462315 sec GFLOPS=620.245
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 1.09212208 sec GFLOPS=19.6634
@@@@ dgemm test OK
==== Running N=10 with streams ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x40000000, 2) beta= (0x40000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.03504515 sec GFLOPS=612.776
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x0000000000000000, 0)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 1.09177494 sec GFLOPS=19.6697
@@@@ dgemm test OK
==== Running N=10 batched ====
Testing sgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0x3f800000, 1) beta= (0xbf800000, -1)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 0.03766394 sec GFLOPS=570.17
@@@@ sgemm test OK
Testing dgemm
#### args: ta=0 tb=0 m=1024 n=1024 k=1024 alpha = (0xbff0000000000000, -1) beta= (0x4000000000000000, 2)
#### args: lda=1024 ldb=1024 ldc=1024
^^^^ elapsed = 1.09389901 sec GFLOPS=19.6315
@@@@ dgemm test OK
Test Summary
0 error(s)
对比
1080ti 1080 Jetson Tx2
GFLOPS=5654.24 GFLOPS=3526.7 GFLOPS=576.83
GFLOPS=7299.19 GFLOPS=5813.35 GFLOPS=620.245
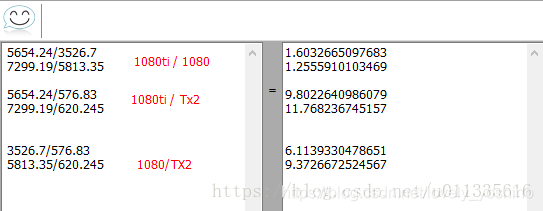
科学计算显卡的两个主要性能指标:
1、CUDA compute capability,这是英伟达公司对显卡计算能力的一个衡量指标;
2、FLOPS 每秒浮点运算次数,TFLOPS表示每秒万亿(10^12)次浮点计算;
3、另外,显存大小也决定了实验中能够使用的样本数量和模型复杂度。
当然了,网上也有很多贴吧或者论坛,视频,各种评测或者天梯图,讨论各种显卡的优劣,例如:RTX3090,RTX3080以及GTX2080ti的分析等,大家可以自行斟酌。
3.参考链接
https://blog.csdn.net/p312011150/article/details/83989674
https://www.expreview.com/52443-3.html
https://www.expreview.com/67453.html
http://tieba.baidu.com/p/5388310468
http://k.sina.com.cn/article_2934331057_aee656b1001004rc9.html?cre=oldpagepc&mod=g&loc=15&r=0&doct=0&rfunc=72&tj=none
https://bbs.csdn.net/topics/392311745
https://baijiahao.baidu.com/s?id=1597974095090413567&wfr=spider&for=pc
https://cudazone.nvidia.cn/forum/forum.php?mod=viewthread&tid=7722&extra=page%253D1
https://blog.csdn.net/ZIV555/article/details/51753985
讲的比较详细的是下面这一篇,里面有一些我也不知道怎么就输出的信息,可能是某种软件吧:
https://blog.csdn.net/enjoyyl/article/details/81529779#1080TI_33

- 点赞
- 收藏
- 关注作者
评论(0)