Flink实战:消费Wikipedia实时消息

【摘要】 Wikipedia Edit Stream是Flink官网提供的一个经典demo,该应用消费的消息来自维基百科,今天咱们就来一起实战这个demo的开发、部署、验证过程
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
关于Wikipedia Edit Stream
- Wikipedia Edit Stream是Flink官网提供的一个经典demo,该应用消费的消息来自维基百科,消息中包含了用户名对wiki的编辑情况,demo的官方资料地址:https://ci.apache.org/projects/flink/flink-docs-release-1.2/quickstart/run_example_quickstart.html
消息来源
-
消息的DataSource是个名为WikipediaEditsSource的类,这里面建立了到irc.wikimedia.org的Socker连接,再通过Internet Relay Chat (IRC) 协议接收对方的数据,收到数据后保存在阻塞队列中,通过一个while循环不停的从队列取出数据,再调用SourceContext的collect方法,就在Flink中将这条数据生产出来了;
-
IRC是应用层协议,更多细节请看:https://en.wikipedia.org/wiki/Internet_Relay_Chat
-
关于WikipediaEditsSource类的深入分析,请参考《Flink数据源拆解分析(WikipediaEditsSource)》
实战简介
- 本次实战就是消费上述消息,然后统计每个用户十五秒内所有的消息,将每次操作的字节数累加起来,就得到用户十五秒内操作的字节数总和,并且每次累加了多少都会记录下来并最终和聚合结果一起展示;
和官网demo的不同之处
- 和官网的demo略有不同,官网用的是Tuple2来处理数据,但我这里用了Tuple3,多保存了一个StringBuilder对象,用来记录每次聚合时加了哪些值,这样在结果中通过这个字段就能看出来这个时间窗口内每个用户做了多少次聚合,每次是什么值:
环境信息
- Flink:1.7;
- 运行模式:单机(官网称之为Local Flink Cluster);
- Flink所在机器的操作系统:CentOS Linux release 7.5.1804;
- 开发环境JDK:1.8.0_181;
- 开发环境Maven:3.5.0;
操作步骤简介
- 今天的实战分为以下步骤:
- 创建应用;
- 编码;
- 构建;
- 部署运行;
创建应用
- 应用基本代码是通过mvn命令创建的,在命令行输入以下命令:
mvn archetype:generate -DarchetypeGroupId=org.apache.flink -DarchetypeArtifactId=flink-quickstart-java -DarchetypeVersion=1.7.0
- 按控制台的提示输入groupId、artifactId、version、package等信息,一路回车确认后,会生成一个和你输入的artifactId同名的文件夹(我这里是wikipediaeditstreamdemo),里面是个maven工程:
Define value for property 'groupId': com.bolingcavalry
Define value for property 'artifactId': wikipediaeditstreamdemo
Define value for property 'version' 1.0-SNAPSHOT: :
Define value for property 'package' com.bolingcavalry: :
Confirm properties configuration:
groupId: com.bolingcavalry
artifactId: wikipediaeditstreamdemo
version: 1.0-SNAPSHOT
package: com.bolingcavalry
Y: :
- 用IEDA导入这个maven工程,如下图,已经有了两个类:BatchJob和StreamingJob,BatchJob是用于批处理的,本次实战用不上,因此可以删除,只保留流处理的StreamingJob:
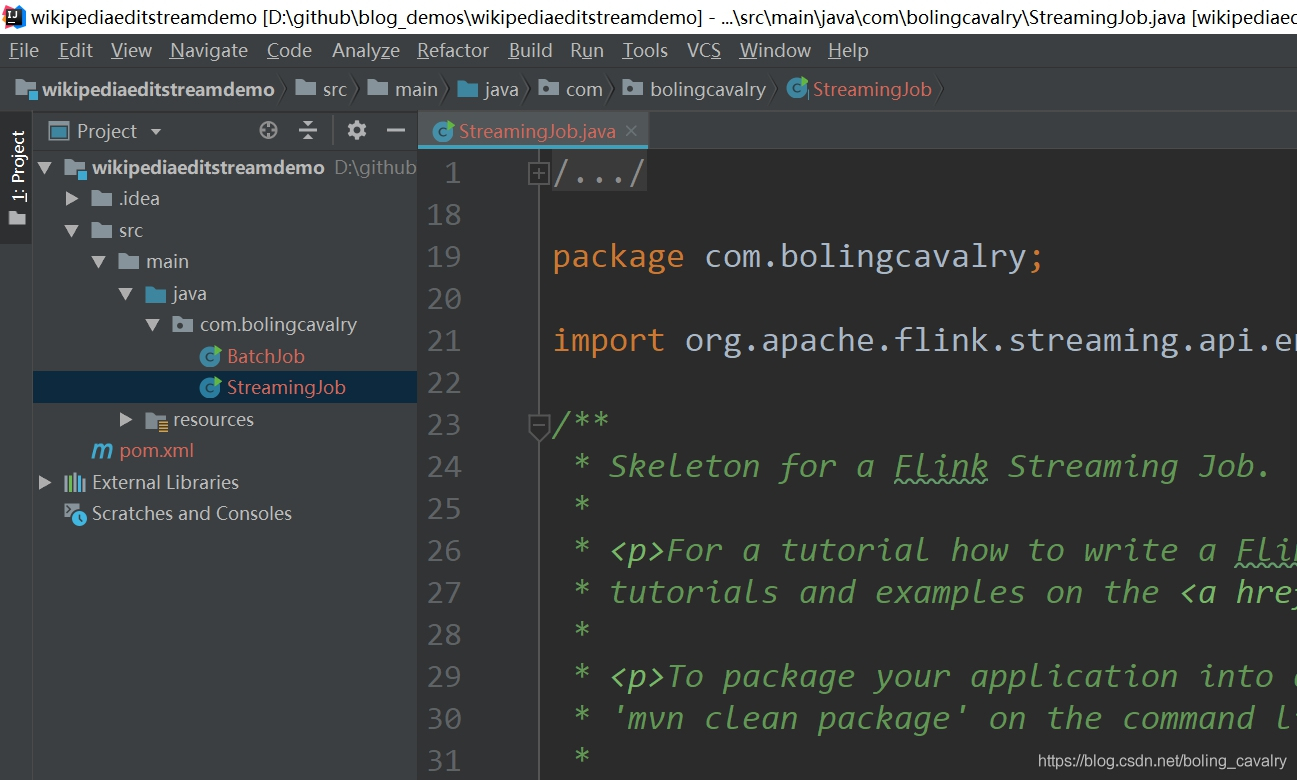
- 应用创建成功,接下来可以开始编码了;
编码
- 您可以选择直接从GitHub下载这个工程的源码,地址和链接信息如下表所示:
| 名称 | 链接 | 备注 |
|---|---|---|
| 项目主页 | https://github.com/zq2599/blog_demos | 该项目在GitHub上的主页 |
| git仓库地址(https) | https://github.com/zq2599/blog_demos.git | 该项目源码的仓库地址,https协议 |
| git仓库地址(ssh) | git@github.com:zq2599/blog_demos.git | 该项目源码的仓库地址,ssh协议 |
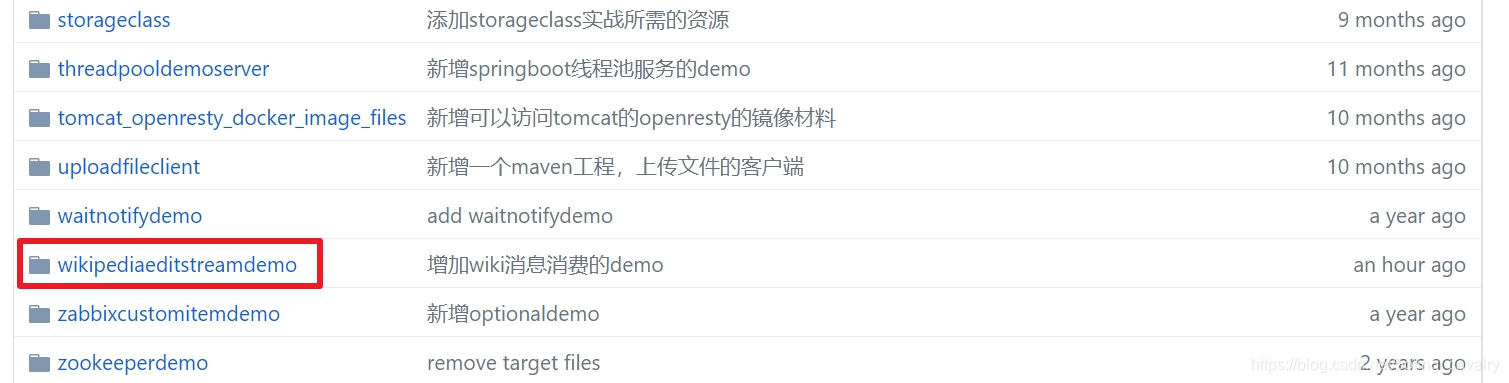
- 这个git项目中有多个文件夹,本章源码在wikipediaeditstreamdemo这个文件夹下,如下图红框所示:
-
接下来开始编码:
-
在pom.mxl文件中增加wikipedia相关的库依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-wikiedits_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
- 在类中增加代码,如下所示,源码中已加详细注释:
package com.bolingcavalry;
import org.apache.commons.lang3.StringUtils;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditEvent;
import org.apache.flink.streaming.connectors.wikiedits.WikipediaEditsSource;
public class StreamingJob {
public static void main(String[] args) throws Exception {
// 环境信息
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.addSource(new WikipediaEditsSource())
//以用户名为key分组
.keyBy((KeySelector<WikipediaEditEvent, String>) wikipediaEditEvent -> wikipediaEditEvent.getUser())
//时间窗口为5秒
.timeWindow(Time.seconds(15))
//在时间窗口内按照key将所有数据做聚合
.aggregate(new AggregateFunction<WikipediaEditEvent, Tuple3<String, Integer, StringBuilder>, Tuple3<String, Integer, StringBuilder>>() {
@Override
public Tuple3<String, Integer, StringBuilder> createAccumulator() {
//创建ACC
return new Tuple3<>("", 0, new StringBuilder());
}
@Override
public Tuple3<String, Integer, StringBuilder> add(WikipediaEditEvent wikipediaEditEvent, Tuple3<String, Integer, StringBuilder> tuple3) {
StringBuilder sbud = tuple3.f2;
//如果是第一条记录,就加个"Details :"作为前缀,
//如果不是第一条记录,就用空格作为分隔符
if(StringUtils.isBlank(sbud.toString())){
sbud.append("Details : ");
}else {
sbud.append(" ");
}
//聚合逻辑是将改动的字节数累加
return new Tuple3<>(wikipediaEditEvent.getUser(),
wikipediaEditEvent.getByteDiff() + tuple3.f1,
sbud.append(wikipediaEditEvent.getByteDiff()));
}
@Override
public Tuple3<String, Integer, StringBuilder> getResult(Tuple3<String, Integer, StringBuilder> tuple3) {
return tuple3;
}
@Override
public Tuple3<String, Integer, StringBuilder> merge(Tuple3<String, Integer, StringBuilder> tuple3, Tuple3<String, Integer, StringBuilder> acc1) {
//合并窗口的场景才会用到
return new Tuple3<>(tuple3.f0,
tuple3.f1 + acc1.f1, tuple3.f2.append(acc1.f2));
}
})
//聚合操作后,将每个key的聚合结果单独转为字符串
.map((MapFunction<Tuple3<String, Integer, StringBuilder>, String>) tuple3 -> tuple3.toString())
//输出方式是STDOUT
.print();
// 执行
env.execute("Flink Streaming Java API Skeleton");
}
}
- 至此编码结束;
构建
- 在pom.xml文件所在目录下执行命令:
mvn clean package -U
- 命令执行完毕后,在target目录下的wikipediaeditstreamdemo-1.0-SNAPSHOT.jar文件就是构建成功的jar包;
在Flink验证
- Flink的安装和启动请参考《Flink1.7从安装到体验》;
- 我这边Flink所在机器的IP地址是192.168.1.103,因此用浏览器访问的Flink的web地址为:http://192.168.1.103:8081;
- 选择刚刚生成的jar文件作为一个新的任务,如下图:
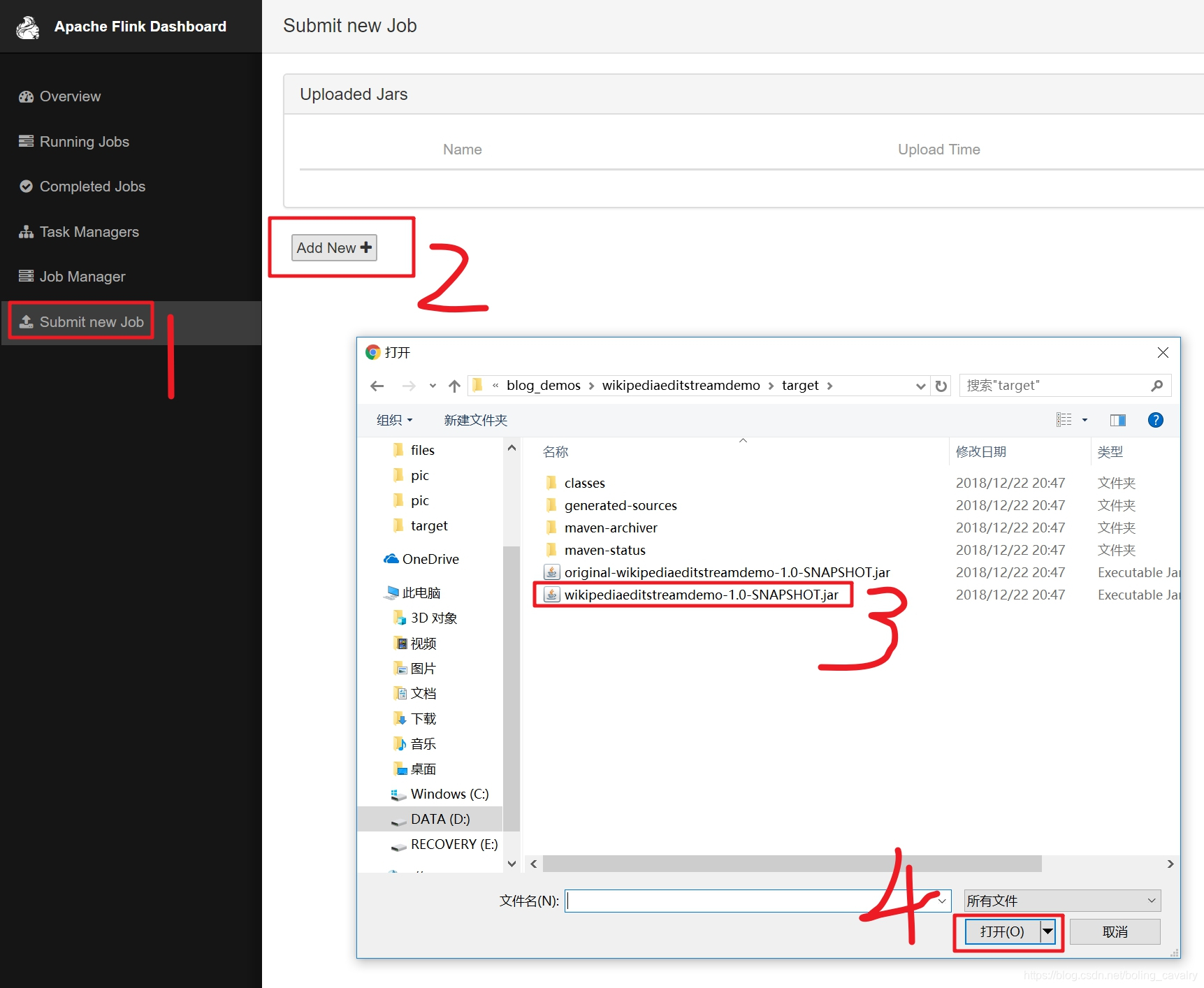
- 点击下图红框中的"upload",将文件提交:
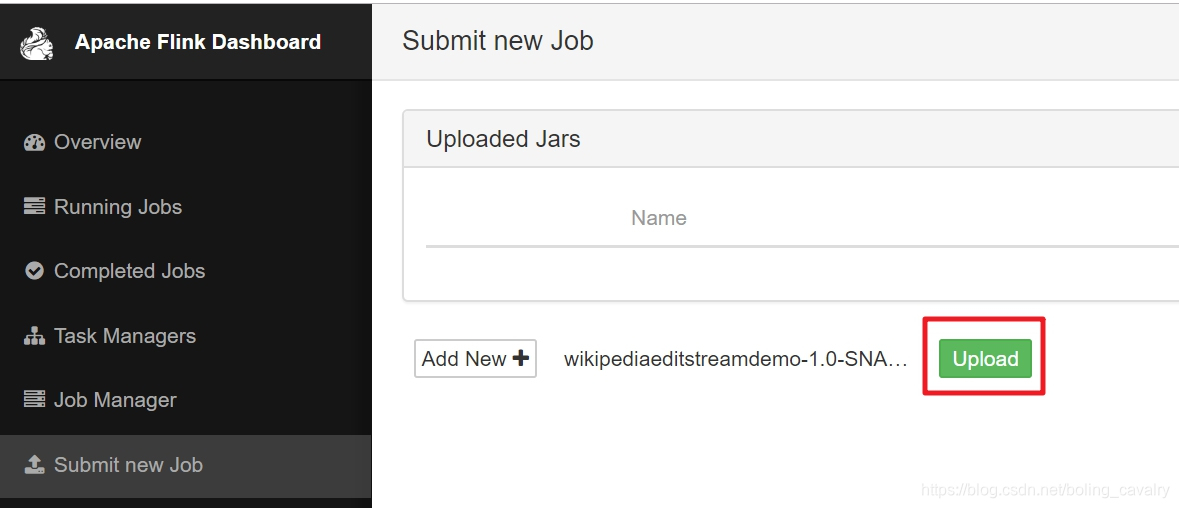
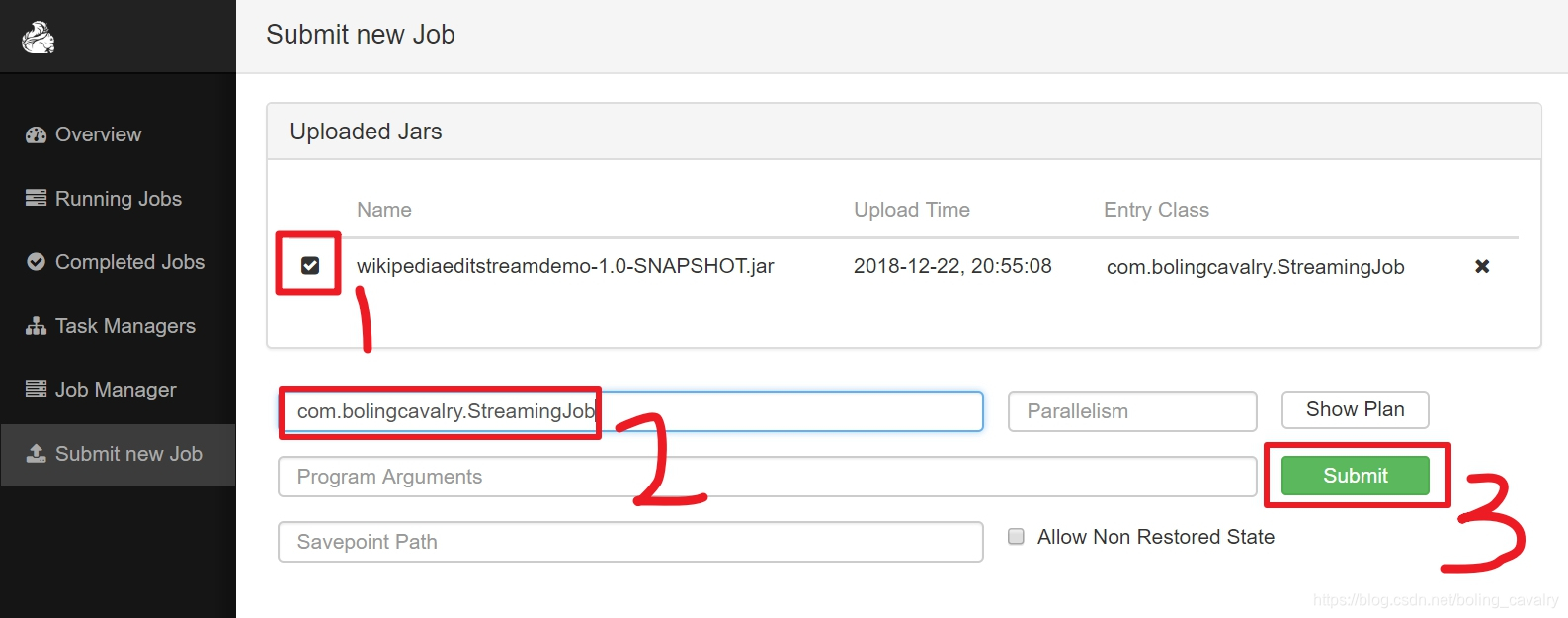
- 目前还只是将jar文件上传了而已,接下来就是手工设置执行类并启动任务,操作如下图,红框2中填写的前面编写的StreamingJob类的完整名称:
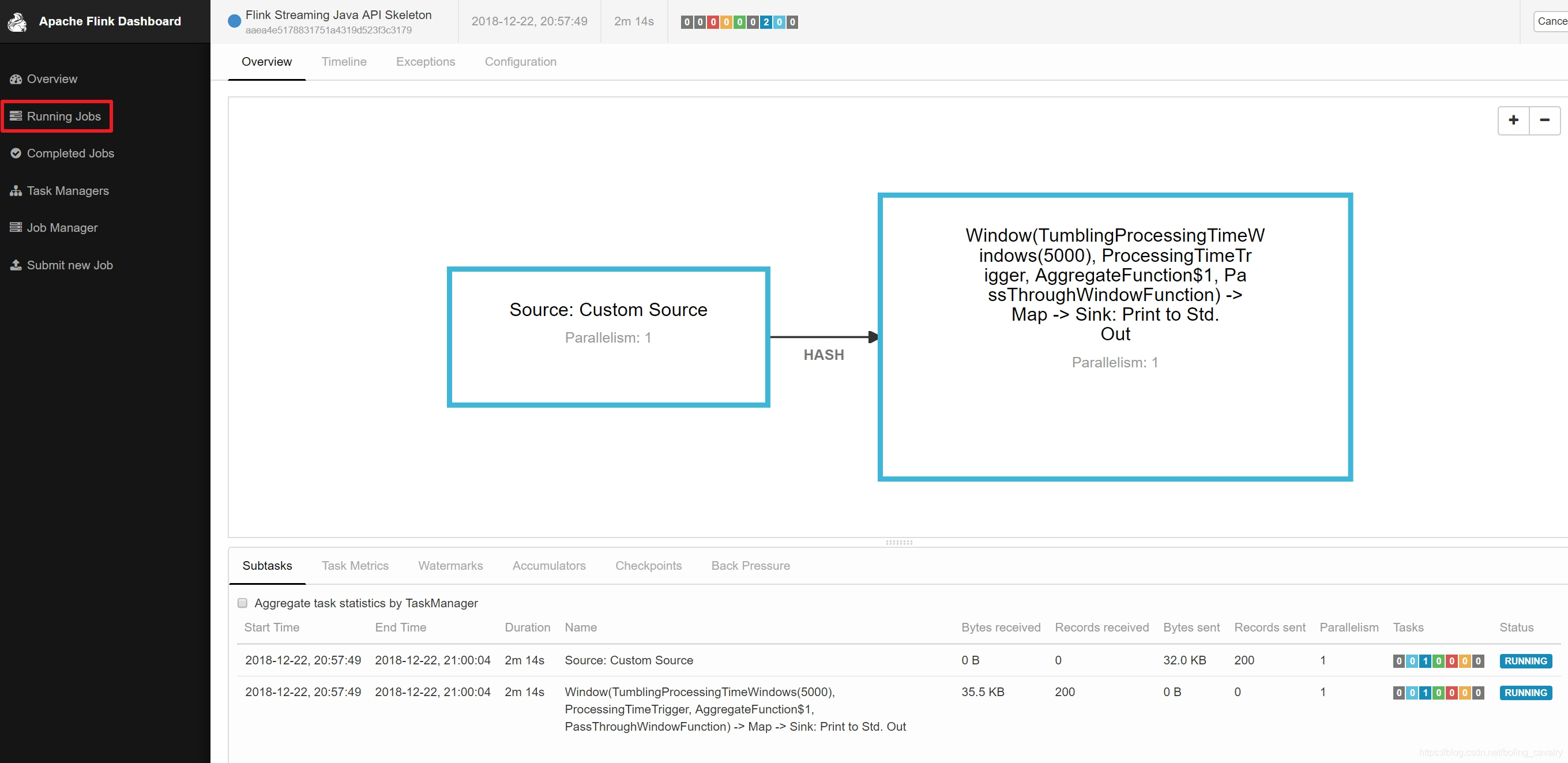
- 提交后的页面效果如下图所示,可见一个job已经在运行中了:
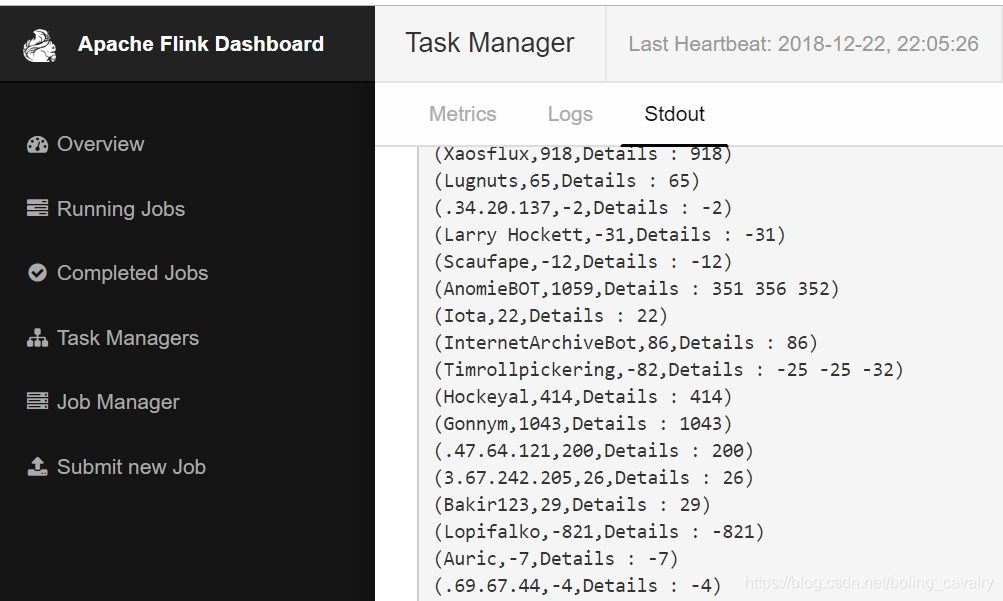
- 接下来看看我们的job的执行效果,如下图,以用户名聚合后的字数统计已经被打印出来了,并且Details后面的内容还展示了具体的聚合情况:
- 至此,一个实施处理的Flink应用就开发完成了,希望能给您的开发过程提供一些参考,后面的实战中咱们一起继续深入学习和探讨Flink;
欢迎关注华为云博客:程序员欣宸

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)