数据系统分区设计 - 分区与二级索引

目前的分区方案都依赖KV数据模型。KV模型简单,都是通过K访问记录,自然可根据K确定分区,并将读写请求路由到负责该K的分区。
但若涉及二级索引,就很复杂。二级索引通常并不能唯一标识一条记录,而是一种加速特定值的查询,如查询用户JavaEdge的所有操作,查找包含词语 java 的所有博客等。
许多KV存储(如HBase)为了减少实现复杂度而放弃二级索引,但一些(如 Riak)已开始支持它们,二级索引也是 Solr 和 ES 等搜索服务器的根本。
二级索引的主要挑战是不能整齐地映射到分区。有两种方案支持对二级索引进行分区:
- 基于文档的分区(document-based)
- 基于关键词(term-based)的分区
3.1 基于文档的二级索引进行分区
二手车销售网(如图-4)。 每个列表都有个唯一的文档ID,以此对DB进行分区,如分区0 中的ID 0~499,分区1中的 ID 500~999。
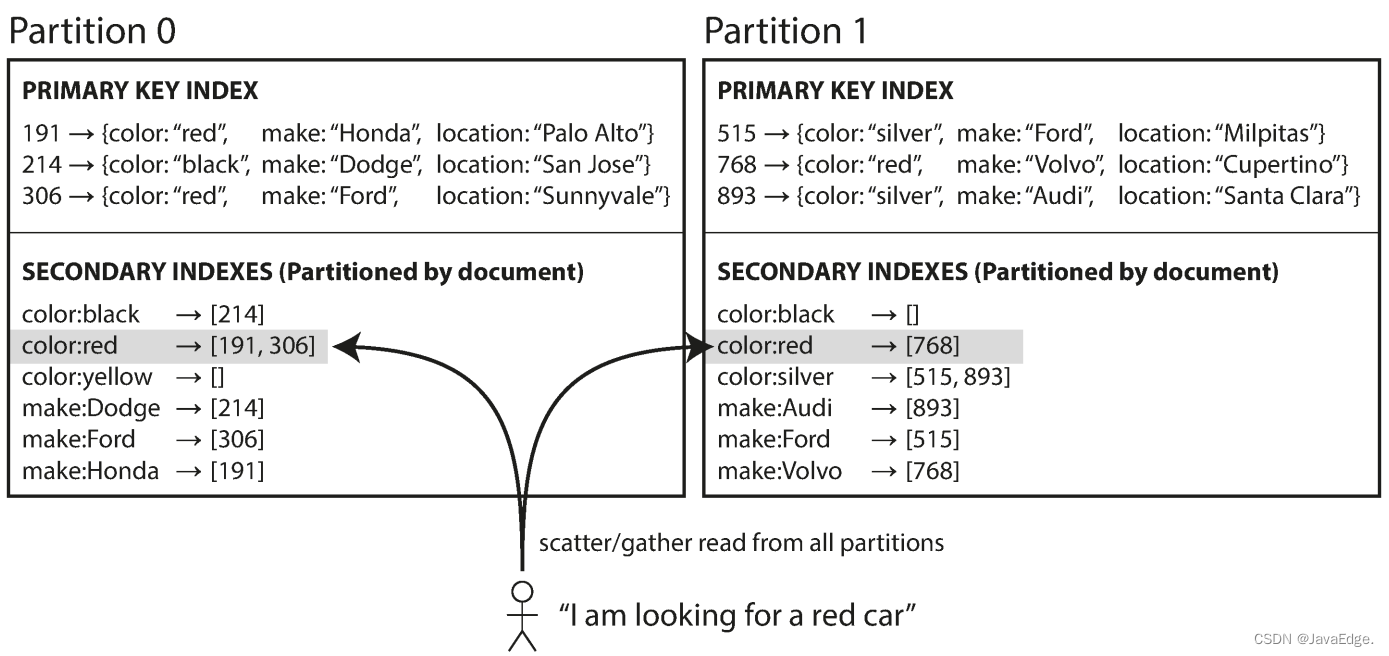
用户搜车,可按颜色和厂商过滤,所以需要在颜色和厂商设置二级索引(在文档DB中这些是字段(field),关系DB中这些是列(column))。每当将一辆红色汽车添加到DB,DB分区都会自动将其添加到索引条目 color:red 的文档ID列表。
[^ii]: 若DB仅支持KV模型,则你可能尝试在应用程序代码中创建从值到文档ID的映射来实现二级索引。 若沿着这条路,请确保你的索引与原 DB 系统保持数据一致。 竞争条件和中间写入失败(其中一些更改已保存,但其他更改未保存)都很容易导致数据不同步。
这种索引方法中,每个分区完全独立,各自维护自己的二级索引,且只负责自己分区内的文档,而不关心其他分区的数据。每当需要写DB(添加,删除或更新文档),只需处理包含你正在编写的目标文档ID的分区。因此,文档分区索引也被称为本地索引,而非全局索引。
但读时注意:除非对文档ID特别处理,否则不太可能将所有特定颜色或品牌的汽车放在同一分区。图-4中,红车出现在分区0、1。因此,若搜索红车,就需将查询发送到所有分区,然后合并所有返回的结果。
这种查询分区DB的方法有时称为分散/聚集(scatter/gather),显然这种二级索引的查询代价高昂。即使并行查询分区,分散/聚集也容易导致尾部读延迟显著放大。但它依旧被广泛使用:MongoDB,Cassandra,ES都直至基于文档分区的二级索引。大多DB供应商建议用户自己构建合适的分区方案,尽量由单个分区满足二级索引查询,但这并不总是可行,尤其是当查询中使用多个二级索引时(例如同时需按颜色、制造商两个条件查询)。
3.2 基于词条(Term)的二级索引分区
可对所有的数据构建全局索引,而非每个分区维护自己的二级索引(本地索引)。为避免成为瓶颈,不能将全局索引存储在一个节点,否则就破坏了设置分区均衡的目的。所以,全局索引也必须分区,但可以采用与K不同的分区策略。
如图-5,所有数据分区的红车收录在索引color:red,而索引本身也是分区的,如从 a 到 r 开始的颜色在分区 0,s 到 z 分区 1。类似的,汽车制造商的索引也被分区(两个分区的边界分别是 f、 h)。
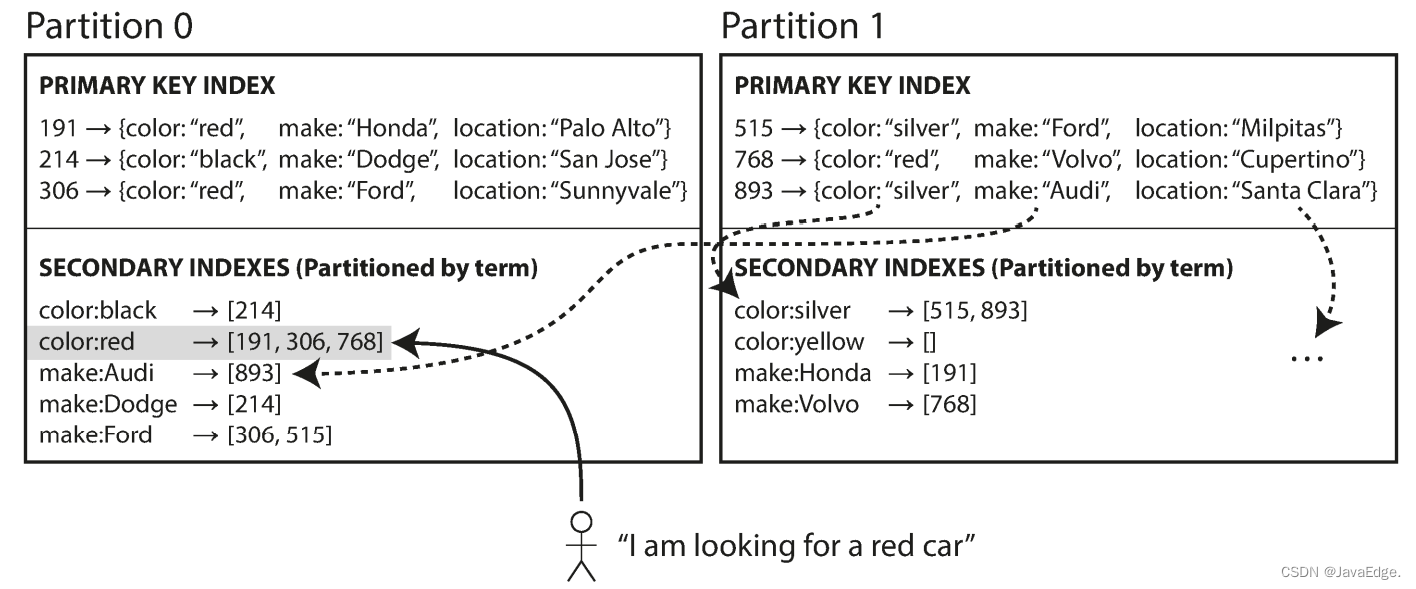
这种索引称为 词条分区(term-partitioned),以待寻找的关键词本身作为索引。如颜色:color:red。关键词(Term)这个名称源于全文索引(一种特殊的二级索引),term指文档中出现的所有单词集合。
可直接通过 关键词 本身来全局划分索引,或对其hash。根据关键词本身分区对范围扫描很有用(如对数值类的属性,e.g. 车报价),而对关键词hash分区可更均匀划分分区。
全局的词条分区 V.S 文档分区索引
- 它使读更高效,即无需分散 / 收集对所有分区都执行一遍查询。相反,客户端只需向含词条的分区发出读请求
- 全局索引的缺点,写速度较慢且复杂,因为单个文档的更新是,可能影响多个二级索引,而二级索引的分区可能位于不同分区或不同节点,
理想情况下,索引应时刻保持最新,即写入的每个数据要立即反映在最新的索引。但对词条分区,这需要跨分区的分布式事务,写入速度将受到极大影响,所以现有 DB 都不支持同步更新二级索引。
实践中,对全局二级索引的更新都是异步(即若在写入后马上读索引,则更新可能尚未反映在索引中)。

- 点赞
- 收藏
- 关注作者
评论(0)