旋转目标检测 校准的深度特征用于目标检测SSA

目录
旋转目标检测rotation-yolov5
旋转目标检测rotation-yolov5笔记_AI视觉网奇的博客-CSDN博客_yolov5旋转目标检测
旋转目标检测综述
旋转目标检测综述(持续更新中)_杀生丸变大叔了的博客-CSDN博客_旋转目标检测
七、R3det(19单阶)
1.表示方法、框架:
2.Rotation RetinaNet
3.Refined Rotation RetinaNet
4.Feature Refinment Module
5.实验
八、CAD-Net(19,69.9map)
1.整体组成
2.实验结果
九、 ROI-Transformer(CVPR19)
1.旋转anchor缺点
2.STN和可变形卷积
3.RoI transformer
3.1RRoI Learner
3.2 Rotated Position Sensitive RoI Align
4.实验结果
十、 RSDet(19.12,DOTA上mAP74.1)
十一、SCRDet(ICCV2019,75.35)
1.前身:R2CNN++
2.SCRDet:
1. SF-Net
2. MAD-Net
3. IoU-Smooth L1 Loss
4. 实验结果
十二.滑动顶点(Gliding vertex,2020CVPR,75.02)
1.网络结构
2.标签的生成
3.损失函数
4.测试与实验
十三.P-RSDet(CVPR2020,DOTA上mAP72.3)
1.framework
2.极值点提取(pole point extraction)
3.损失函数
4.实验结果
2.读入数据
SSA旋转目标检测
开源地址:

一、简要
为了解决这个问题,有研究者提出了一个Single-shot Alignment Network(S2A-Net),由两个模块组成:一个特征对齐模块(FAM)和一个定向检测模块(ODM)。FAM可以通过anchor优化网络生成高质量的anchor,并根据anchor boxes与新提出的对齐卷积来自适应对齐卷积特征。ODM首先采用主动active rotating filters对方向信息进行编码,然后产生方向敏感和方向不变的特征,以缓解分类分数与定位精度之间的不一致性。此外,研究者还进一步探索了在大尺寸图像中检测物体的方法,从而在速度和精度之间进行了更好的权衡。
大量的实验表明,新提出的方法可以在两个常用的数据集(DOTA和HRSC2016)上达到最先进的性能,同时保持高效率!
二、背景
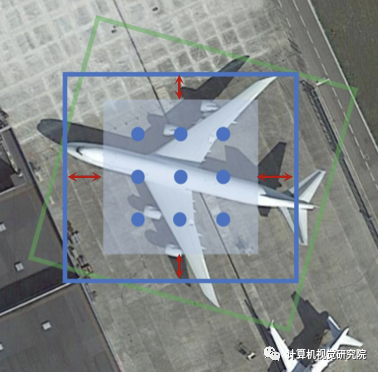
与基于R-CNN的探测器相比,one-stage探测器回归边界框,并直接用常规和密集的采样anchor对它们进行分类。这种架构具有很高的计算效率,但在精度上往往落后于[G.-S. Xia, X. Bai, J. Ding, Z. Zhu, S. Belongie, J. Luo, M. Datcu, M. Pelillo, and L. Zhang, “DOTA: A large-scale dataset for object detection in aerial images,” in CVPR, 2018]。如下图所示,认为one-stage探测器出现严重错位。
-
启发式定义的anchor质量低,不能覆盖目标,导致目标和anchor之间的错位。例如,桥的展宽比通常在1/3到1/30之间,只有少数anchor甚至没有anchor可以校准。这种错位通常加剧前景背景类的不平衡,阻碍性能。
-
主干网络的卷积特征通常与固定的接受场进行轴对齐,而航空图像中的目标则以任意的方向和不同的外观进行分布。即使是anchor boxes被分配给具有高可信度的实例(即IoU),anchor boxes与卷积特征之间仍然存在错位。换句话说,anchor boxes的相应特征在某种程度上难以表示整个目标。结果,最终的分类分数不能准确地反映定位精度,这也阻碍了后处理阶段的检测性能(如NMS)。
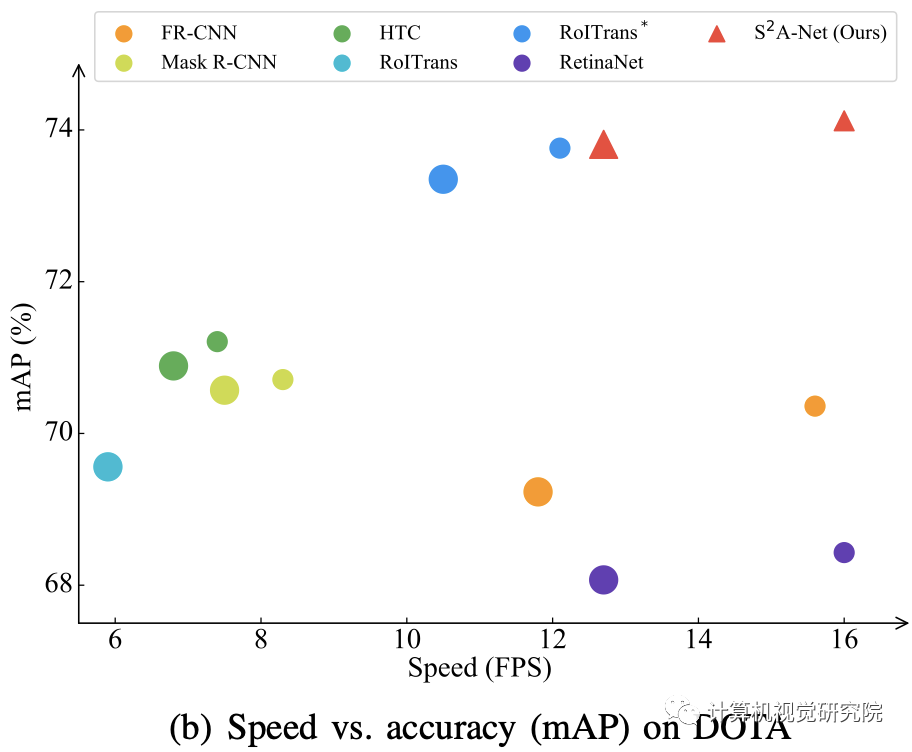
相同设置下不同方法的性能比较
三、新框架分析

-
RetinaNet as Baseline

注意,RetinaNet设计用于通用目标检测,输出水平边界框(如下图(a))表示为:

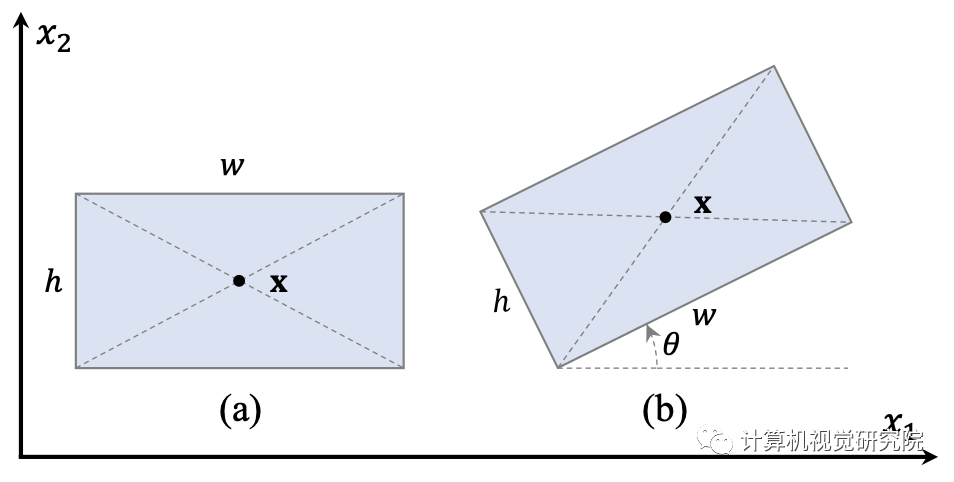
为了与面向目标检测相兼容,研究者将定向边界框代替RetinaNet的回归输出。如上图(b),表示为:

其实就是增加了一个角度参数,角度θ范围[-π/4,3π/4]。
-
Alignment Convolution
直接上图,看图说话。

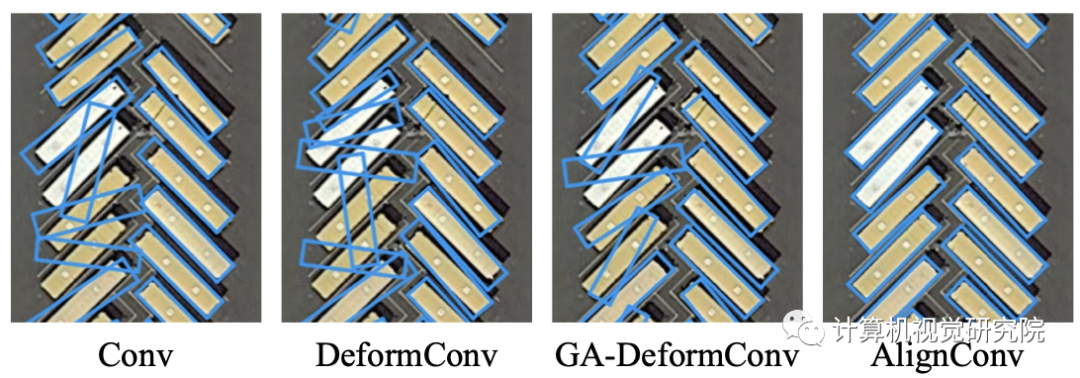
如图所示。通过规则网格在特征图上的标准卷积样本。DeformConv学习一个偏移场来增加空间采样位置。然而,它可能会在错误的地方采样,特别是对于包装密集的物体。研究者提出的AlignConv通过添加一个额外的偏移字段的anchor boxes引导来提取网格分布的特征。与DeformConv不同,AlignConv中的偏移字段是直接从anchor boxes推断出来的。上图中的例子。(c)和(d)说明了AlignConv可以在anchor boxes中提取准确的特征。
(a)是标准的常规采样位置二维卷积(绿点)。(b)为Deformable Convolution,具有可变形采样位置(蓝点)。(c)和(d)是研究者提出的具有水平和旋转anchor boxes(AB)的两个例子(橙色矩形),蓝色箭头表示偏移字段。
-
Feature Alignment Module (FAM)
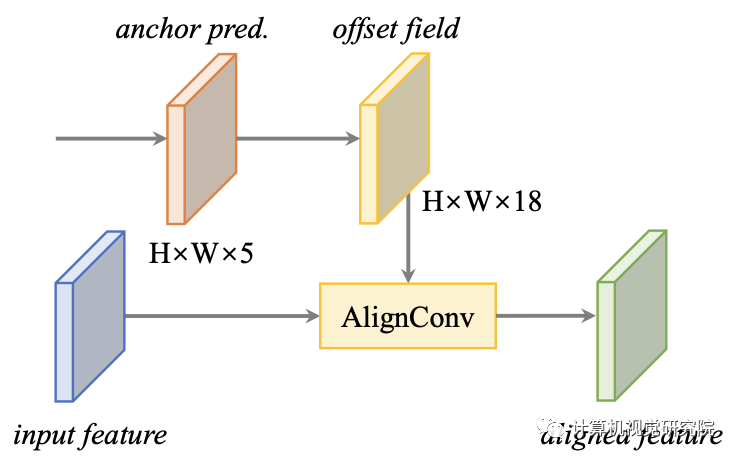
采用输入特征和anchor预测。映射为输入,并生成对齐的特征。
-
Oriented Detection Module (ODM)
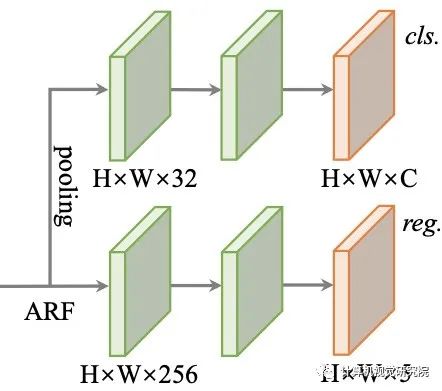
ODM以缓解分类分数和定位精度之间的不一致性,然后进行精确的目标检测。
四、实验及可视化
不同的RETINANET在DOTA数据集上的结果


研究者将一个大尺寸的图像裁剪成1024×1024chip图像,步长为824。将大尺寸图像和chip图像输入相同网络,以不调整大小即可产生检测结果(例如红框中的灰机)。

不同的方法在DOTA数据集上的结果

在HRSC2016数据上的测试结果
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/125696111

- 点赞
- 收藏
- 关注作者
评论(0)