Node.js 应用的内存泄漏问题的检测方法

Node.js 是一个基于 Chrome 的 V8 JavaScript 引擎构建的平台,用于轻松构建快速且可扩展的网络应用程序。
Google 的 V8 ——Node.js 背后的 JavaScript 引擎, 它的性能令人难以置信,并且 Node.js 在许多用例中运行良好的原因有很多,但您总是受到堆大小的限制。 当您需要在 Node.js 应用程序中处理更多请求时,您有两种选择:垂直扩展或者水平扩展。 水平扩展意味着您必须运行更多并发应用程序实例。 如果做得好,您最终能够满足更多请求。 垂直扩展意味着您必须提高应用程序的内存使用和性能或增加应用程序实例可用的资源。
Node.js Memory Leak Debugging Arsenal
MEMWATCH
如果您搜索“如何在 node.js 中查找泄漏”,您可能会找到的第一个工具是 memwatch。 原来的包早就废弃了,不再维护。 但是,您可以在 GitHub 的存储库分叉列表中轻松找到它的更新版本。 这个模块很有用,因为它可以在看到堆增长超过 5 次连续垃圾收集时发出泄漏事件。
HEAPDUMP
很棒的工具,它允许 Node.js 开发人员拍摄堆快照并在以后使用 Chrome 开发人员工具检查它们。
NODE-INSPECTOR
甚至是 heapdump 的更有用的替代方案,因为它允许您连接到正在运行的应用程序,进行堆转储,甚至可以即时调试和重新编译它。
Taking “node-inspector” for a Spin
不幸的是,您将无法连接到在 Heroku 上运行的生产应用程序,因为它不允许将信号发送到正在运行的进程。 然而,Heroku 并不是唯一的托管平台。
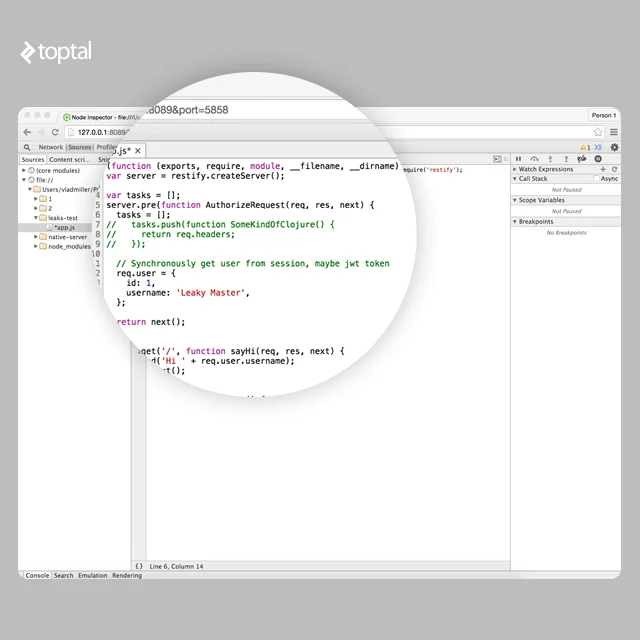
为了体验 node-inspector 的实际操作,我们将使用 restify 编写一个简单的 Node.js 应用程序,并在其中放置一些内存泄漏源。 这里所有的实验都是用 Node.js v0.12.7 进行的,它是针对 V8 v3.28.71.19 编译的。
var restify = require('restify');
var server = restify.createServer();
var tasks = [];
server.pre(function(req, res, next) {
tasks.push(function() {
return req.headers;
});
// Synchronously get user from session, maybe jwt token
req.user = {
id: 1,
username: 'Leaky Master',
};
return next();
});
server.get('/', function(req, res, next) {
res.send('Hi ' + req.user.username);
return next();
});
server.listen(3000, function() {
console.log('%s listening at %s', server.name, server.url);
});
这里的应用很简单,有很明显的泄露。 阵列任务会随着应用程序生命周期的增长而增长,导致它变慢并最终崩溃。 问题是我们不仅泄漏了闭包,还泄漏了整个请求对象。
V8 中的 GC 使用 stop-the-world 策略,因此这意味着内存中的对象越多,收集垃圾所需的时间就越长。 在下面的日志中,您可以清楚地看到,在应用程序生命周期开始时,收集垃圾平均需要 20 毫秒,但几十万个请求之后需要大约 230 毫秒。 由于 GC,试图访问我们应用程序的人现在必须等待 230 毫秒。 您还可以看到每隔几秒就会调用一次 GC,这意味着每隔几秒用户就会在访问我们的应用程序时遇到问题。 延迟会越来越大,直到应用程序崩溃。

当使用 –trace_gc 标志启动 Node.js 应用程序时,会打印这些日志行:
node --trace_gc app.js
让我们假设我们已经使用这个标志启动了我们的 Node.js 应用程序。 在将应用程序与节点检查器连接之前,我们需要将 SIGUSR1 信号发送给正在运行的进程。 如果您在集群中运行 Node.js,请确保您连接到从属进程之一。
kill -SIGUSR1 $pid # Replace $pid with the actual process ID
通过这样做,我们使 Node.js 应用程序(准确地说是 V8)进入调试模式。 在此模式下,应用程序会使用 V8 调试协议自动打开端口 5858。
我们的下一步是运行 node-inspector,它将连接到正在运行的应用程序的调试界面,并在端口 8080 上打开另一个 Web 界面。
$ node-inspector
Node Inspector v0.12.2
Visit http://127.0.0.1:8080/?ws=127.0.0.1:8080&port=5858 to start debugging.
如果应用程序在生产环境中运行并且您有防火墙,我们可以通过隧道将远程端口 8080 连接到本地主机:
ssh -L 8080:localhost:8080 admin@example.com
现在,您可以打开 Chrome 网络浏览器并完全访问附加到远程生产应用程序的 Chrome 开发工具。
Let’s Find a Leak!
V8 中的内存泄漏并不是我们从 C/C++ 应用程序中知道的真正的内存泄漏。 在 JavaScript 中,变量不会成为 void,它们只会被“遗忘”。 我们的目标是找到这些被开发人员遗忘的变量。
在 Chrome 开发者工具中,我们可以访问多个分析器。 我们对记录堆分配特别感兴趣,它会随着时间的推移运行并拍摄多个堆快照。 这让我们可以清楚地看到哪些对象正在泄漏。
开始记录堆分配,让我们使用 Apache Benchmark 在我们的主页上模拟 50 个并发用户。
ab -c 50 -n 1000000 -k http://example.com/
在拍摄新快照之前,V8 会执行标记-清除垃圾收集,所以我们肯定知道快照中没有旧垃圾。
Fixing the Leak on the Fly
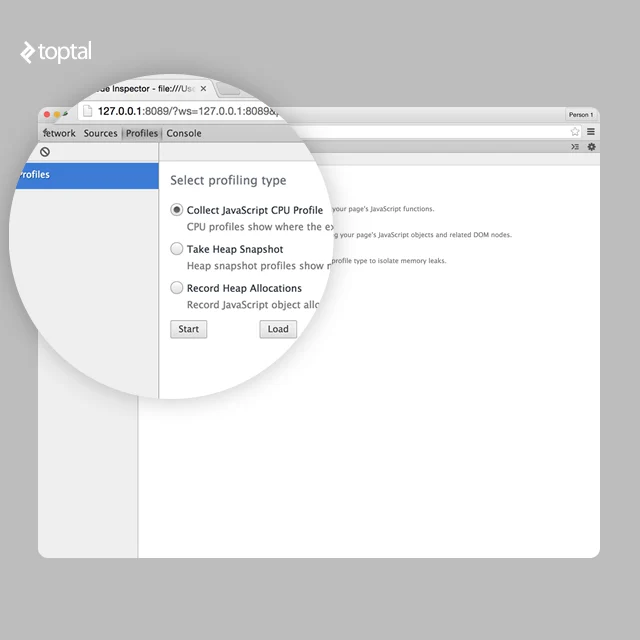
在 3 分钟内收集堆分配快照后,我们最终得到如下结果:

我们可以清楚地看到,堆中有一些巨大的数组,还有很多 IncomingMessage、ReadableState、ServerResponse 和 Domain 对象。让我们尝试分析泄漏的来源。
在图表上从 20 秒到 40 秒选择堆差异后,我们只会看到从您启动分析器时起 20 秒后添加的对象。这样您就可以排除所有正常数据。
记下系统中每种类型的对象有多少,我们将过滤器从 20 秒扩展到 1 分钟。我们可以看到,已经相当庞大的阵列还在不断增长。在“(array)”下我们可以看到有很多等距的对象“(object properties)”。这些对象是我们内存泄漏的源头。
我们也可以看到“(闭包)”对象也在快速增长。
查看字符串也可能很方便。在字符串列表下有很多“Hi Leaky Master”短语。这些也可能给我们一些线索。
在我们的例子中,我们知道字符串“Hi Leaky Master”只能在“GET /”路由下组装。
如果您打开保留器路径,您将看到此字符串以某种方式通过 req 引用,然后创建了上下文并将所有这些添加到一些巨大的闭包数组中。
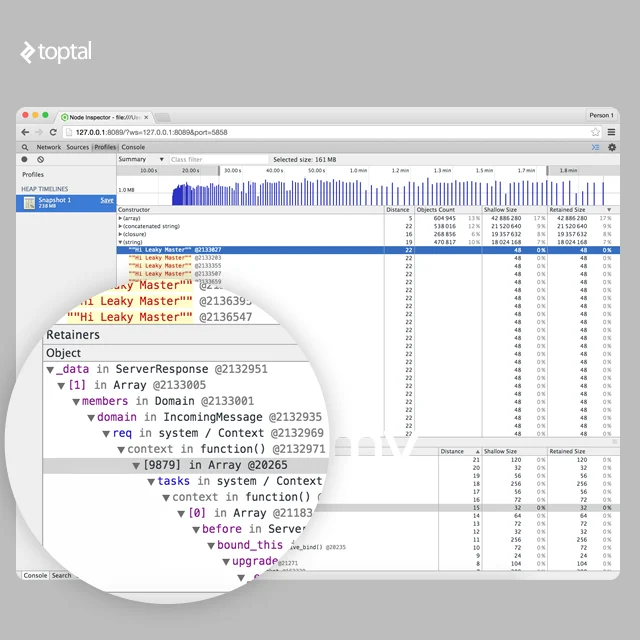
所以在这一点上我们知道我们有某种巨大的闭包数组。 让我们在“源”选项卡下实时为所有闭包命名。
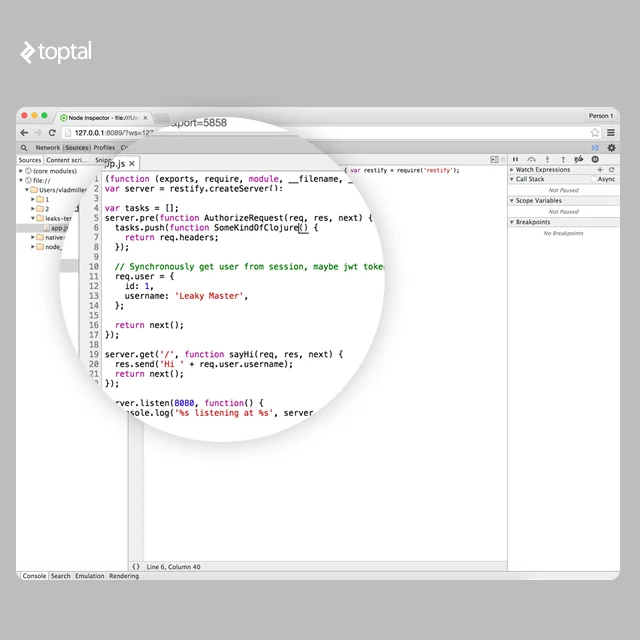
完成代码编辑后,我们可以按 CTRL+S 来保存和重新编译代码!
现在让我们记录另一个堆分配快照,看看哪些闭包正在占用内存。
很明显 SomeKindOfClojure() 是我们的 target。 现在我们可以看到 SomeKindOfClojure() 闭包被添加到全局空间中一些名为任务的数组中。
很容易看出这个数组是没有用的。 我们可以注释掉。 但是我们如何释放已经占用的内存呢? 很简单,我们只需为任务分配一个空数组,下一次请求时它将被覆盖并在下一次 GC 事件后释放内存。

V8堆分为几个不同的空间:
- new space:这个空间比较小,大小在1MB到8MB之间。 大多数对象都在这里分配。
- old pointer space:具有可能具有指向其他对象的指针的对象。 如果对象在新空间中存活的时间足够长,它就会被提升到旧指针空间。
- old data space:仅包含原始数据,如字符串、装箱数字和未装箱双精度数组。 在新空间中在 GC 中存活足够长时间的对象也被移动到这里。
- large object space:在此空间中创建太大而无法放入其他空间的对象。 每个对象在内存中都有自己的 mmap 区域
- code space:包含由 JIT 编译器生成的汇编代码。
- Cell space, property cell space, map space:该空间包含单元格、属性单元格和地图。 这用于简化垃圾收集。
每个空间由页面组成。页面是从操作系统使用 mmap 分配的内存区域。除了大对象空间中的页面外,每个页面的大小始终为 1MB。
V8 有两个内置的垃圾收集机制:Scavenge、Mark-Sweep 和 Mark-Compact。
Scavenge 是一种非常快速的垃圾收集技术,可以处理 New Space 中的对象。 Scavenge 是切尼算法的实现。这个想法很简单,New Space 被分成两个相等的半空间:To-Space 和 From-Space。当 To-Space 已满时,会发生 Scavenge GC。它只是交换 To 和 From 空间并将所有活动对象复制到 To-Space 或将它们提升到旧空间之一,如果它们在两次清除中幸存下来,然后从空间中完全删除。清理速度非常快,但是它们具有保持双倍大小的堆和不断在内存中复制对象的开销。使用清除的原因是因为大多数对象都很年轻。
Mark-Sweep 和 Mark-Compact 是 V8 中使用的另一种类型的垃圾收集器。另一个名称是 full garbage collector. 它标记所有活动节点,然后清除所有死节点并整理内存碎片。
GC Performance and Debugging Tips
虽然对于 Web 应用程序来说,高性能可能不是什么大问题,但您仍然希望不惜一切代价避免泄漏。 在 full GC 的标记阶段,应用程序实际上会暂停,直到垃圾收集完成。 这意味着堆中的对象越多,执行 GC 所需的时间就越长,用户等待的时间也就越长。
ALWAYS GIVE NAMES TO CLOSURES AND FUNCTIONS
当所有闭包和函数都有名称时,检查堆栈跟踪和堆会容易得多。
db.query('GIVE THEM ALL', function GiveThemAllAName(error, data) {
...
})
AVOID LARGE OBJECTS IN HOT FUNCTIONS
理想情况下,您希望避免在 hot function 内部使用大对象,以便所有数据都适合新空间。 所有 CPU 和内存绑定操作都应在后台执行。 还要避免 hot function 的去优化触发器,优化的 hot function 比未优化的 hot function 使用更少的内存。
AVOID POLYMORPHISM FOR IC’S IN HOT FUNCTIONS
内联缓存 ( Inline Caches ) 用于通过缓存对象属性访问 obj.key 或某些简单函数来加速某些代码块的执行。
function x(a, b) {
return a + b;
}
x(1, 2); // monomorphic
x(1, “string”); // polymorphic, level 2
x(3.14, 1); // polymorphic, level 3
当 x(a,b) 第一次运行时,V8 创建了一个单态 IC。 当您第二次调用 x 时,V8 会擦除旧 IC 并创建一个新的多态 IC,该 IC 支持整数和字符串两种类型的操作数。 当您第三次调用 IC 时,V8 重复相同的过程并创建另一个级别为 3 的多态 IC。
但是,有一个限制。 在 IC 级别达到 5(可以使用 –max_inlining_levels 标志更改)后,该函数变得超态,不再被认为是可优化的。
直观上可以理解,单态函数运行速度最快,内存占用也更小。
DON’T ADD LARGE FILES TO MEMORY
这是显而易见的,也是众所周知的。 如果您有大文件要处理,例如一个大 CSV 文件,请逐行读取并以小块处理,而不是将整个文件加载到内存中。 在极少数情况下,单行 csv 会大于 1mb,因此您可以将其放入新空间。
DO NOT BLOCK MAIN SERVER THREAD
如果您有一些需要一些时间来处理的热门 API,例如调整图像大小的 API,请将其移至单独的线程或将其转换为后台作业。 CPU 密集型操作会阻塞主线程,迫使所有其他客户等待并继续发送请求。 未处理的请求数据会堆积在内存中,从而迫使 full GC 需要更长的时间才能完成。
DO NOT CREATE UNNECESSARY DATA
我曾经对restify有过奇怪的经历。 如果您向无效 URL 发送数十万个请求,那么应用程序内存将迅速增长到数百兆字节,直到几秒钟后完全 GC 启动,此时一切都会恢复正常。 事实证明,对于每个无效的 URL,restify 会生成一个新的错误对象,其中包含长堆栈跟踪。 这迫使新创建的对象在大对象空间而不是新空间中分配。
在开发过程中访问这些数据可能非常有帮助,但在生产中显然不需要。 因此规则很简单——除非您确实需要,否则不要生成数据。
总结
了解 V8 的垃圾收集和代码优化器的工作原理是提高应用程序性能的关键。 V8 将 JavaScript 编译为原生程序集,在某些情况下,编写良好的代码可以获得与 GCC 编译的应用程序相当的性能。

- 点赞
- 收藏
- 关注作者
评论(0)