EdgeNeXt打出了一套混合拳:集CNN与Transformer于一体的轻量级架构

edgenext_xx_small 这个模型权重20M
| edgenext_small_usi | 81.07 | 5.59M | 1.26G | model |
| edgenext_small | 79.41 | 5.59M | 1.26G | model |
| edgenext_x_small | 74.96 | 2.34M | 538M | model |
| edgenext_xx_small | 71.23 | 1.33M | 261M | model |
| edgenext_small_bn_hs | 78.39 | 5.58M | 1.25G | model |
| edgenext_x_small_bn_hs | 74.87 | 2.34M | 536M | model |
| edgenext_xx_small_bn_hs | 70.33 | 1.33M | 260M | model |
本文从减轻计算资源消耗以部署于边缘设备入手,提出EdgeNeXt混合架构,该架构引入分割深度转置注意力(SDTA)编码器,通过通道组分割与合理的注意力机制来提高资源利用率。该架构凭借1.3M的参数量在ImageNet-1K上表现超过MobileViT,扩容后凭借5.6M的参数量在ImageNet-1K上达到79.4%的最高精度。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
写在前面的话
本文从减轻计算资源消耗以部署于边缘设备入手,提出EdgeNeXt混合架构,该架构引入分割深度转置注意力(SDTA)编码器,通过通道组分割与合理的注意力机制来提高资源利用率。该架构凭借1.3M的参数量在ImageNet-1K上表现超过MobileViT,扩容后凭借5.6M的参数量在ImageNet-1K上达到79.4%的最高精度。

论文地址:https://arxiv.org/abs/2206.10589
代码链接:https://github.com/mmaaz60/EdgeNeXt
一、为什么会想到分割深度转置注意力?
EdgeNeXt是一种集CNN与Transformer于一体的混合架构,鉴于现有大多流行方法,在追求更高精度的同时并不能很好的保持更快推理速度,以至于在资源受限设备上的部署表现不足。
因此EdgeNeXt希望可以在保持较小模型容量的同时提升模型性能。而CNN作为捕捉局部特征的经典代表,自然被作为架构设计的核心。然而随着现有研究的进行,一些经典的CNN有如下两个主要限制:
-
首先,CNN是使用局部感受野来进行特征捕获,因此无法直接对全局环境进行建模;
-
其次,CNN学习到的权重在推理时是静止的,这使得CNN不能灵活地适应不同输入内容。
现有方法试图将Vision Transformers(ViTs)的优良特性与CNN结合,以解决上述限制。然而大部分结合方式都不可避免的带来了一个新问题:由于自注意力计算方式的特点,架构推理速度被严重限制。
因此,EdgeNeXt试图在将CNN与ViTs结合的同时,兼顾模型性能与推理速度。作者等人通过引入一个分割深度转置注意力(SDTA)编码器,在做到高效结合的同时,不增加额外的参数量和乘法-加法运算量(MAdds)。一份简单的架构比较图如下所示:
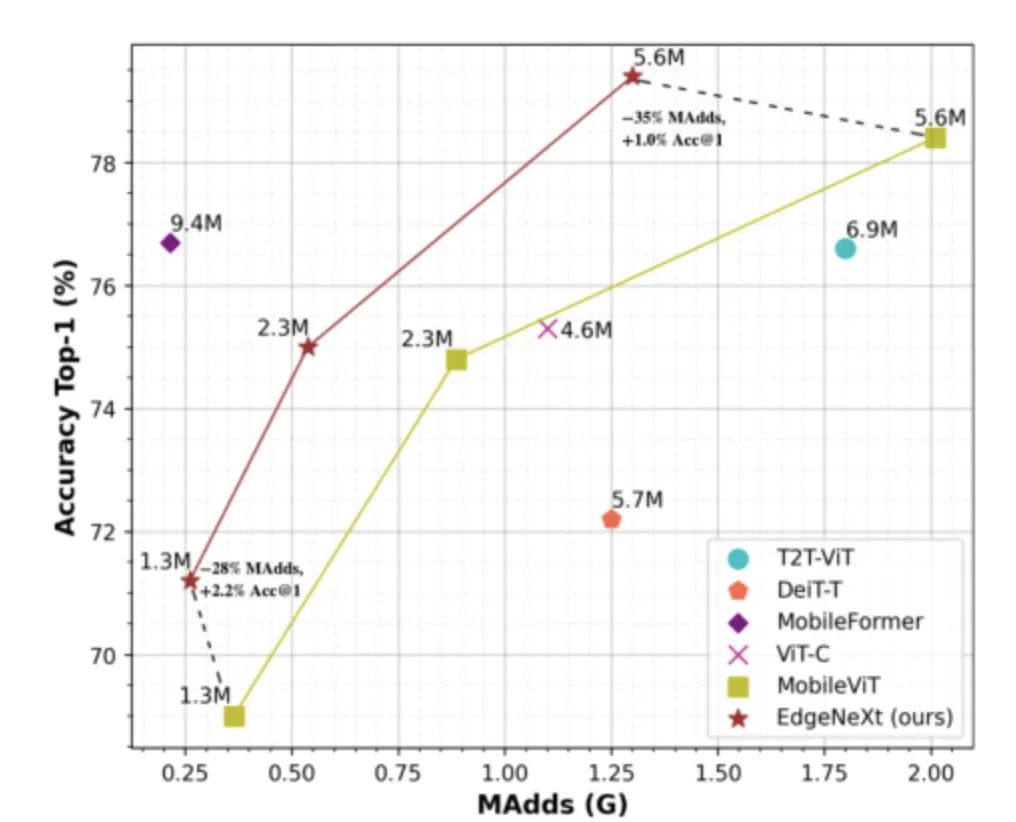
图1:EdgeNeXt模型与SOTA ViTs和混合架构设计的比较,数据集为ImageNet-1K。
图中1.3M参数量的EdgeNeXt在ImageNet-1K上的性能超过同样轻量级的混合架构MobileViT,而5.6M参数量的版本凭借适中的MAdds成为对比架构中的SOTA模型。
EdgeNeXt是如何结合CNN与ViTs的?又是如何做到在引入SDTA模块后不增加额外参数量的?
下面笔者带领大家一探究竟~
二、EdgeNeXt剖析

图2:EdgeNeXt架构整体示意图。
如图,EdgeNeXt同样采用标准的“四阶段”金字塔式设计规范,其主要包括卷积编码器和SDTA编码器两个核心模块。
从整体结构出发,输入大小为的特征图,在网络的起始部分,采用了与ViT、SwinTransformer类似的“Patchify”策略,即通过使用尺寸为的非重叠卷积来达到更好的池化效果,此时输出尺寸为。紧接着使用连续堆叠的3个核大小为的卷积编码器来提取局部特征(不改变特征图大小)。
Stage 2中的DownSampling采用步长为(2,2)的卷积来实现,此时得到尺寸为的输出,经过连续堆叠的2个核大小为的卷积编码器后,在进入SDTA模块前以element-wise add的方式添加位置编码(为减少位置编码对检测、分割等任务的影响并提高模型推理速度,四个阶段仅需添加这一次即可)。
Stage 3和Stage 4则分别使用和的卷积编码层。不同的核大小应用实现了自适应的核大小机制,而作者等人这样设计的原因是希望大核来增加CNN的局部感受野,以提高模型性能,然而直接的大核应用会带来高昂的计算成本,因此使用这样金字塔式的设计是十分合理的。
现有研究工作表明,CNN浅层的更多特征体现为纹理、局部边缘等,深层则体现为抽象语义,更偏向全局信息。因此在浅层应用较小核,深层应用较大核是符合CNN结构特性的。
卷积编码器和SDTA编码器作为架构核心模块,将分成两个单独的小节进行讲解~
卷积编码器(Convolution Encoder)
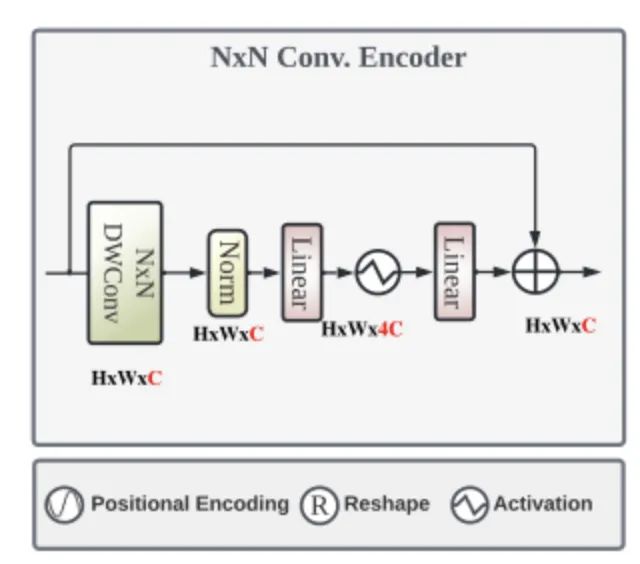
图3:卷积编码器示意图。
如图,编码器起始部分的N×N DWConv代表具有自适应核大小的Depth-wise卷积,如上所述,N在EdgeNeXt四个阶段中的数值分别为{3,5,7,9}。经过层归一化后使用逐点卷积(即图中的Linear)来扩展通道维度至原来的4倍,并辅以GELU来增加非线性,最后通过逐点卷积恢复通道维度后,添加残差连接来保障网络的正常学习。一份简单的pytorch代码示例如下所示:
-
import torch
-
import torch.nn as nn
-
class ConvEncoder(nn.Module):
-
def __init__(self, n, channels):
-
super(ConvEncoder, self).__init__()
-
-
self.identity = nn.Identity()
-
self.stem_conv = nn.Conv2d(channels, channels, kernel_size=(n, n), padding=(n // 2, n // 2), groups=channels)
-
self.norm = nn.LayerNorm(channels) # 这里可以直接调用,在forward中进行维度调整,也可以另写一个层归一化处理的函数再调用
-
self.linear1 = nn.Conv2d(channels, channels * 4, kernel_size=1)
-
self.gelu = nn.GELU()
-
self.linear2 = nn.Conv2d(channels * 4, channels, kernel_size=1)
-
-
def forward(self, x):
-
identity = self.identity(x)
-
x = self.stem_conv(x)
-
x = self.norm(x.permute(0, 2, 3, 1)).permute(0, 3, 1, 2)
-
x = self.linear2(self.gelu(self.linear1(x)))
-
out = x + identity
-
return out
-
分割深度转置注意编码器(SDTA Encoder)
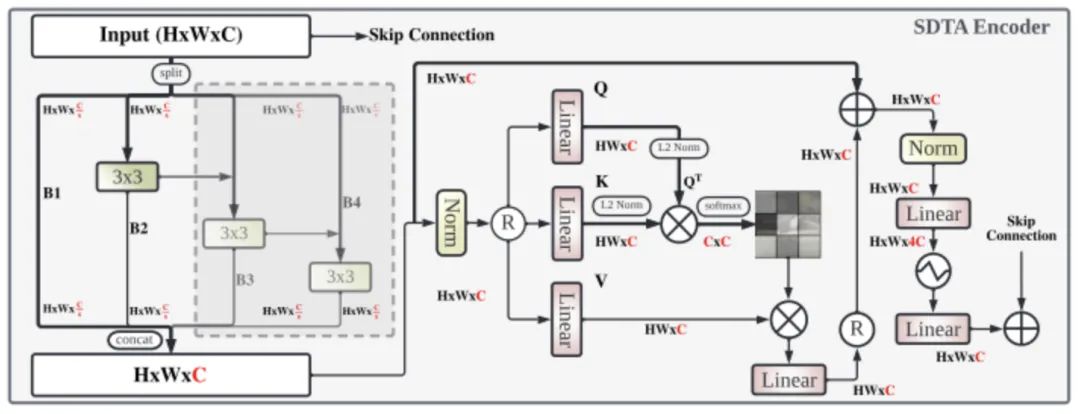
图4:SDTA编码器示意图。
如图,SDTA编码器包含两个主要组件:特征编码模块和自注意计算模块。
在第一个组件中,作者等人参考Res2Net的架构设计,希望能获得具有更灵活和自适应空间感受野的输出特征。首先输入特征通过直接的通道切分被划分为s个子集(图中s=4),每个子集的尺寸均为,接着每个子集的计算方式都是将上一个子集的输出特征融合后再经过3×3的depth-wise卷积。以图4中的4个子集为例,子集B1由于处在起始位置,故不做任何处理;子集B2将B1的输出进行特征融合,再经过3×3的depth-wise卷积进行特征编码;子集B3将B2的输出进行特征融合,再经过3×3的depth-wise卷积进行特征编码;子集B4将B3的输出进行特征融合,再经过3×3的depth-wise卷积进行特征编码.最终4个子集的输出特征被拼接后得到具有多尺度感受野的输出特征。
需要注意的是,特征通道的切分也可以使用逐点卷积来近似的完成,但作者等人希望进一步减少参数量,故采用直接的通道切分。
第二个组件是本文的核心,如图,输入特征通过reshape被修改为,辅以三个线性层得到Q、K、V,在计算交叉协方差注意力之前,通过对Q、K应用 L2 范数来稳定训练。之后,以往的计算在Q、K之间沿空间维度进行,即(HW × C)和(C × HW)运算后得到(HW × HW)。然而本文方法希望在通道维度上计算注意力,即仅对Q进行转置,因此(C×HW) ·(HW ×C)可得到(C × C),计算结果辅以softmax得到注意力得分矩阵,应用于V得到最终的注意力图。
为什么要在通道维度进行点积运算?作者等人的解释是:传统自注意力层的开销对于边缘设备上的视觉任务是不可行的,因为它是以更高的 MAdd 和延迟为代价的。为了缓解这个问题并有效地编码全局上下文,提出在通道维度上应用点积。
模型整体的结构与参数量示意如下所示:
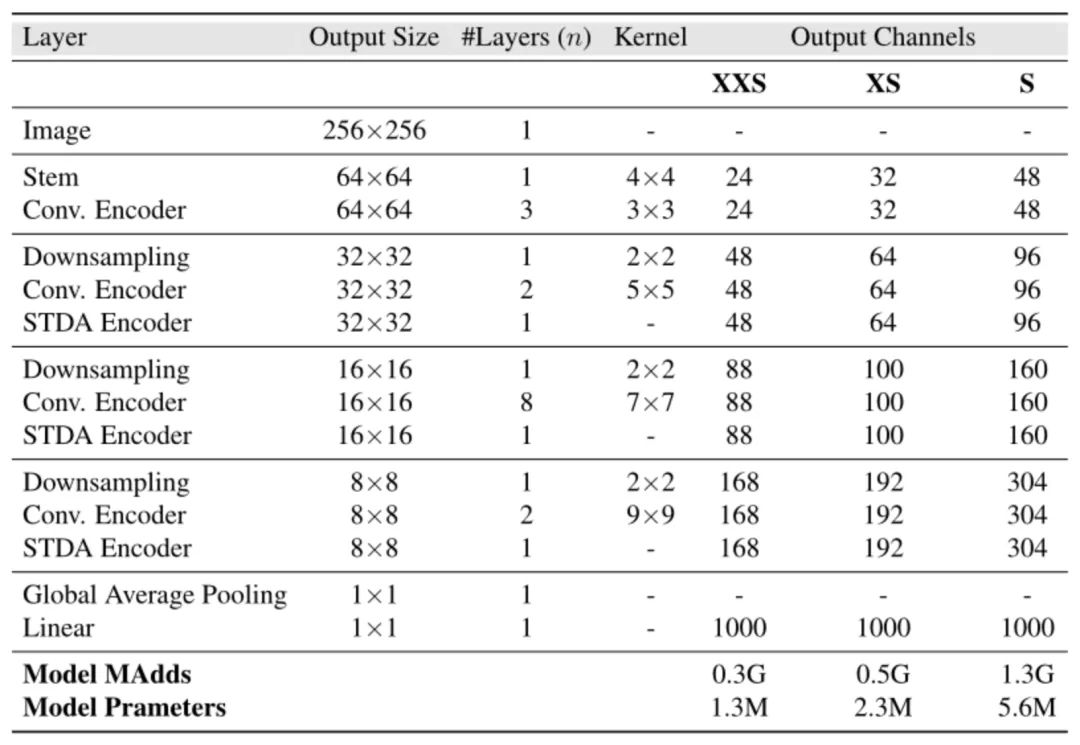
图5:EdgeNeXt 架构详细示意图。
三、性能对比
在实验部分,作者等人对图像分类(ImageNet-1K)、目标检测(COCO)、图像分割(Pascal VOC 2012)等下游任务均进行详细的性能对比。其对比结果如下所示:
图像分类:
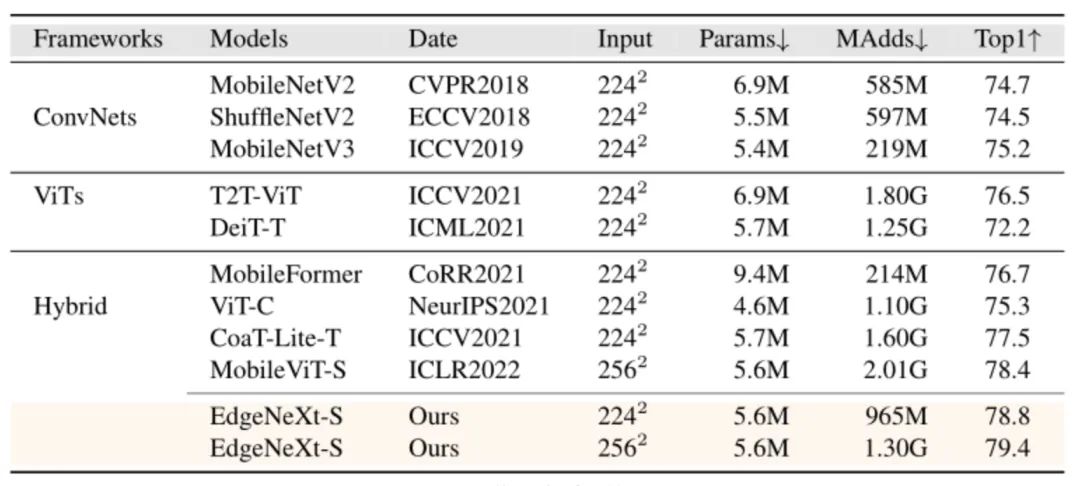
图6:图像分类对比结果。
目标检测:
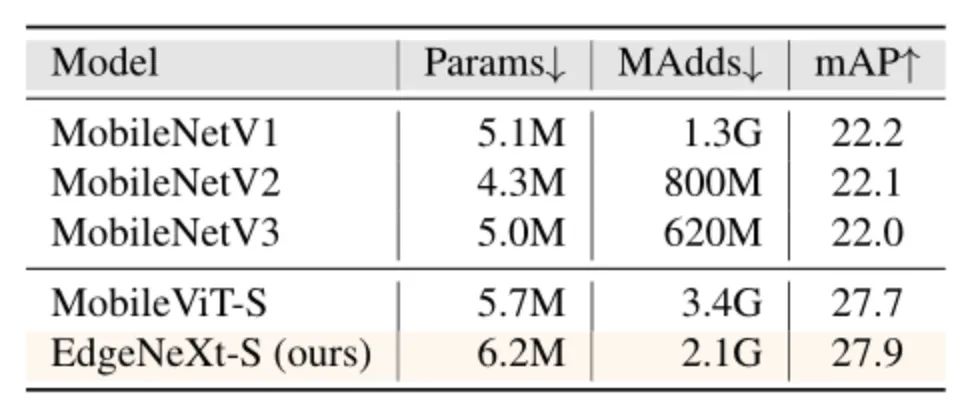
图7:目标检测对比结果。
图像分割:
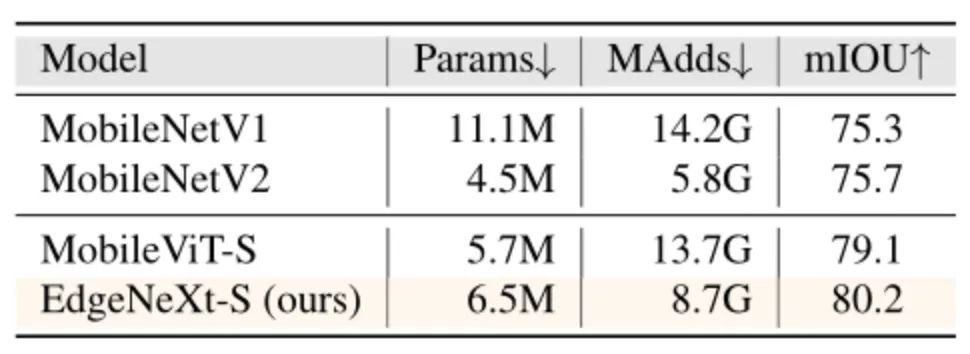
图8:图像分割对比结果。
四、思考与总结
本文从轻量化角度出发,设计了卷积与transformer的混合架构EdgeNeXt,兼顾了模型性能与模型大小/推理速度。
整体架构采取标准的“四阶段”金字塔范式设计,其中包含卷积编码器与SDTA编码器两个重要的模块。在卷积编码器中,自适应核大小的设计被应用,这与SDTA中的多尺度感受野的思想相呼应。而在SDTA编码器中,特征编码部分使用固定的3×3卷积,但通过层次级联实现多尺度感受野的融合,而此处若使用不同尺寸的卷积核是否会带来更好的效果有待考证。在自注意计算部分,通过将点积运算应用于通道维度,得到了兼顾计算复杂度与全局注意力的输出,是支撑本文的一个核心点。
从分类性能来看,效果确实很好,但结合检测、分割任务来看,供对比模型略少,仅提供了部分轻量级网络对比,希望以后能看到更多优秀工作的产出~
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/125569382

- 点赞
- 收藏
- 关注作者
评论(0)