图像特征计算与表示——基于内容的图像检索

【摘要】 1️⃣作业需求给定不少于100幅合适的图像集合,尺寸可不一,任意选一张图像,并人工给定图像中的一个目标区域,如人脸、楼房、狗等,要求设计一个基于内容的图像检索方法,它能在剩余的图像中找出5张包含最类似框出目标的图像。能大致框出检索出的图像的目标区域更好,不框也可以。2️⃣核心代码# coding:utf-8def extract_features(image_path, vector_siz...
| 1️⃣作业需求 |
|---|
| 2️⃣核心代码 |
|---|
# coding:utf-8
def extract_features(image_path, vector_size=32):
image = imageio.imread(image_path)
try:
# Using KAZE, cause SIFT, ORB and other was moved to additional module
alg = cv2.KAZE_create()
# Finding image keypoints
# 寻找图像关键点
kps = alg.detect(image)
# Getting first 32 of them.
# 计算前32个
# Number of keypoints is varies depend on image size and color pallet
# 关键点的数量取决于图像大小以及彩色调色板
# Sorting them based on keypoint response value(bigger is better)
# 根据关键点的返回值进行排序(越大越好)
kps = sorted(kps, key=lambda x: -x.response)[:vector_size]
# computing descriptors vector
# 计算描述符向量
kps, dsc = alg.compute(image, kps)
# Flatten all of them in one big vector - our feature vector
# 将其放在一个大的向量中,作为我们的特征向量
dsc = dsc.flatten()
# Making descriptor of same size
# 使描述符的大小一致
# Descriptor vector size is 64
# 描述符向量的大小为64
needed_size = (vector_size * 64)
if dsc.size < needed_size:
# if we have less the 32 descriptors then just adding zeros
# at the end of our feature vector
# 如果少于32个描述符,则在特征向量后面补零
dsc = np.concatenate([dsc, np.zeros(needed_size - dsc.size)])
except cv2.error as e:
print('Error: ', e)
return None
return dsc
| 3️⃣实验结果 |
|---|
我们从数据集中随意选取一张图片:

用鼠标框出图像中的一块区域:

然后回车会获取数据集中与框出的目标区域特征最相近的五张图片:

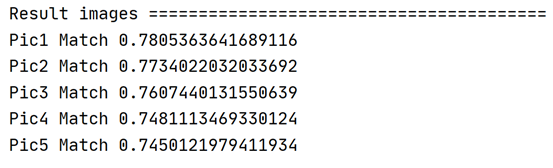
还会输出每张图片的匹配值,这里的匹配值就是计算目标区域的特征与数据库中的图片的余弦距离,如果想相似度更高,可以扩充数据集,使得特征更加适配:
| ⭐实验源码+报告⭐ |
|---|

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)