pytorch RNN 学习笔记

【摘要】
门控循环单元GRU:
PyTorch入门——门控循环单元(GRU) - 知乎
门控循环单元(GRU)
GRU与RNN的对比
RNN:
RNN
GRU:
重置门与更新门
更新候选隐状态
更新隐状态
GRU的从零开始实现
在RNN从零开始实现的基础上修改,主要的区别在模型定义部分
GRU相对RNN...
门控循环单元GRU:
门控循环单元(GRU)
GRU与RNN的对比
RNN:
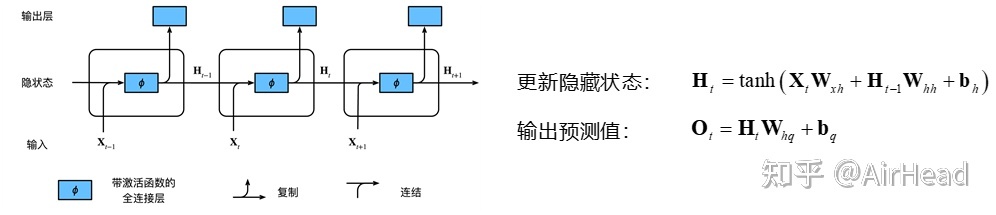
RNN
GRU:

重置门与更新门

更新候选隐状态

更新隐状态
GRU的从零开始实现
在RNN从零开始实现的基础上修改,主要的区别在模型定义部分
GRU相对RNN多了许多权重矩阵,因此需要修改初始化模型参数的函数
-
# # 初始化循环神经网络模型的模型参数
-
def get_params(vocab_size, num_hiddens, device):
-
num_inputs = num_outputs = vocab_size
-
-
def normal(shape):
-
"""均值为0,方差为0.01的正态分布"""
-
return torch.randn(size=shape, device=device) * 0.01
-
-
def three():
-
return (normal((num_inputs, num_hiddens)),
-
normal((num_hiddens, num_hiddens)),
-
torch.zeros(num_hiddens, device=device))
-
-
W_xz, W_hz, b_z = three()
-
W_xr, W_hr, b_r = three()
-
W_xh, W_hh, b_h = three()
-
-
# 输出层参数 q_t = Phi(W_hq * ht + b_q)
-
W_hq = normal((num_hiddens, num_outputs)) # 由 h_t 到 q_t
-
b_q = torch.zeros(num_outputs, device=device)
-
# 附加梯度
-
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
-
for param in params:
-
param.requires_grad_(True)
-
return params

将rnn()替换为gru(),gru()是按照上述原理实现的矩阵运算
-
# # 一个时间步内计算隐藏状态和输出
-
def gru(inputs, state, params):
-
# inputs的形状 (步数,批量大小,vocab_size) 步数是时间维度
-
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params
-
H, = state
-
outputs = []
-
-
for X in inputs: # 遍历每个步数
-
R = torch.sigmoid(X @ W_xr + H @ W_hr + b_r)
-
Z = torch.sigmoid(X @ W_xz + H @ W_hz + b_z)
-
H_tilda = torch.tanh(X @ W_xh + (R * H) @ W_hh + b_h)
-
H = Z * H + (1 - Z) * H_tilda
-
Y = torch.mm(H, W_hq) + b_q
-
outputs.append(Y)
-
return torch.cat(outputs, dim=0), (H,)
由于沐神的代码中,RNNModelScratch类定义的十分通用,因此只需在实例化RNNModelScratch类的时候将gru()传入即可
-
# # 检查torch.cuda是否可用,否则继续使用CPU
-
device = 'cuda' if torch.cuda.is_available() else 'cpu'
-
print(f'-------------------------------\n'
-
f'Using {device} device\n'
-
f'-------------------------------')
-
-
batch_size = 32
-
num_steps = 35
-
num_hiddens = 512
-
num_epochs = 500
-
lr = 1
-
use_random_iter = True
-
-
train_iter, vocab = load_data_time_machine(batch_size, num_steps,
-
use_random_iter=use_random_iter)
-
net = RNNModelScratch(len(vocab), num_hiddens, device,
-
get_params, init_rnn_state, gru)
-
train(net, train_iter, vocab, lr, num_epochs, device,
-
use_random_iter=use_random_iter)
-
plt.show()
GRU的简洁实现
简洁实现与从零开始实现类似,也是在RNN简洁实现代码的基础上,修改模型的定义
将rnn层替换为gru层
-
# 定义RNN层,输出的形状为(num_steps, batch_size, num_hiddens)
-
# rnn_layer = nn.RNN(len(vocab), num_hiddens)
-
gru_layer = nn.GRU(len(vocab), num_hiddens)
class RNNModel实例化时将gru_layer 传入即可
-
# # 检查torch.cuda是否可用,否则继续使用CPU
-
device = 'cuda' if torch.cuda.is_available() else 'cpu'
-
print(f'-------------------------------\n'
-
f'Using {device} device\n'
-
f'-------------------------------')
-
-
batch_size = 32
-
num_steps = 35
-
num_hiddens = 256
-
num_epochs = 500
-
learning_rate = 1
-
-
# 加载数据,并生成数据集的可迭代对象,train_iter访问一次的形状为(batch_size, num_steps)
-
train_iter, vocab = load_data_time_machine(batch_size, num_steps)
-
-
-
# 定义RNN层,输出的形状为(num_steps, batch_size, num_hiddens)
-
# rnn_layer = nn.RNN(len(vocab), num_hiddens)
-
gru_layer = nn.GRU(len(vocab), num_hiddens)
-
-
# # 完整的RNN模型
-
class RNNModel(nn.Module):
-
"""循环神经网络模型"""
-
-
def __init__(self, rnn_layer, vocab_size, **kwargs):
-
super(RNNModel, self).__init__(**kwargs)
-
self.rnn = rnn_layer
-
self.vocab_size = vocab_size
-
self.num_hiddens = self.rnn.hidden_size
-
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
-
if not self.rnn.bidirectional:
-
self.num_directions = 1
-
self.linear = nn.Linear(self.num_hiddens, self.vocab_size)
-
else:
-
self.num_directions = 2
-
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
-
-
def forward(self, inputs, state):
-
# inputs是通过访问一次train_iter得到的,形状为(batch_size, num_steps)
-
# inputs.T的形状为(num_steps, batch_size)
-
X = F.one_hot(inputs.T.long(), self.vocab_size) # X的形状为(num_steps, batch_size, vocab_size)
-
X = X.to(torch.float32)
-
# Y是所有时间步的隐藏状态,state是最后一个时间步的隐藏状态
-
Y, state = self.rnn(X, state) # Y的形状为(num_steps, batch_size, hidden_size),state为(1,batch_size, hidden_size)
-
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
-
# 它的输出形状是(时间步数*批量大小,词表大小)。
-
output = self.linear(Y.reshape((-1, Y.shape[-1])))
-
return output, state
-
-
def begin_state(self, device, batch_size=1):
-
if not isinstance(self.rnn, nn.LSTM):
-
# nn.GRU以张量作为隐状态
-
return torch.zeros((self.num_directions * self.rnn.num_layers,
-
batch_size, self.num_hiddens),
-
device=device)
-
else:
-
# nn.LSTM以元组作为隐状态
-
return (torch.zeros((
-
self.num_directions * self.rnn.num_layers,
-
batch_size, self.num_hiddens), device=device),
-
torch.zeros((
-
self.num_directions * self.rnn.num_layers,
-
batch_size, self.num_hiddens), device=device))
-
-
-
# 使用张量初始化隐藏状态
-
state = torch.zeros((1, batch_size, num_hiddens))
-
-
# 实例化RNNModel类,创建RNN模型
-
net = RNNModel(gru_layer, vocab_size=len(vocab))
-
net = net.to(device)
-
-
# 训练模型
-
train(net, train_iter, vocab, learning_rate, num_epochs, device)
-
plt.show()
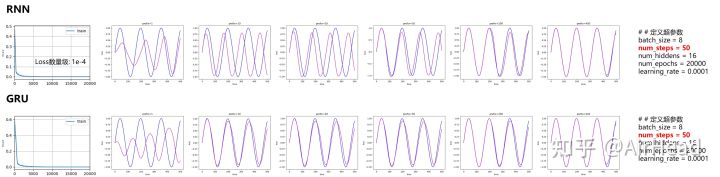
GRU实现简单的时间序列预测
与上面一样,在RNN实现简单时间序列预测的基础上,稍作改动。
只需要改3个字母:
将class RNNModel定义中的self.rnn = nn.RNN(input_size, num_hiddens)
改为self.rnn = nn.GRU(input_size, num_hiddens)
-
# # 完整的RNN模型,输入的input和输出的output都是一个tensor
-
class RNNModel(nn.Module):
-
"""循环神经网络模型"""
-
-
def __init__(self, num_hiddens, input_size, **kwargs):
-
super(RNNModel, self).__init__(**kwargs)
-
# # 定义RNN层
-
# 输入的形状为(num_steps, batch_size, input_size) # input_size 就是 vocab_size
-
# 输出的形状为(num_steps, batch_size, num_hiddens)
-
self.rnn = nn.GRU(input_size, num_hiddens)
-
self.input_size = self.rnn.input_size
-
self.num_hiddens = self.rnn.hidden_size
-
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
-
if not self.rnn.bidirectional:
-
self.num_directions = 1
-
self.linear = nn.Linear(self.num_hiddens, self.input_size)
-
else:
-
self.num_directions = 2
-
self.linear = nn.Linear(self.num_hiddens * 2, self.input_size)
-
-
def forward(self, inputs, state):
-
# inputs的形状为(num_steps, batch_size, input_size)
-
# Y是所有时间步的隐藏状态,state是最后一个时间步的隐藏状态
-
# Y的形状为(num_steps, batch_size, hidden_size),state为(1,batch_size, hidden_size)
-
Y, state = self.rnn(inputs, state)
-
# 全连接层首先将Y的形状改为(num_steps*batch_size, hidden_size)
-
# 它的输出形状是(num_steps*batch_size,input_size)。
-
output = self.linear(Y.reshape((-1, Y.shape[-1])))
-
return output, state
-
-
def begin_state(self, device, batch_size=1):
-
if not isinstance(self.rnn, nn.LSTM):
-
# nn.GRU以张量作为隐状态
-
return torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens),
-
device=device)
-
else:
-
# nn.LSTM以元组作为隐状态
-
return (torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens),
-
device=device),
-
torch.zeros((self.num_directions * self.rnn.num_layers, batch_size, self.num_hiddens),
-
device=device))
pytorch实现rnn:
以下内容转自:
-
class RNN:
-
# ...
-
def step(self, x, hidden):
-
# update the hidden state
-
hidden = np.tanh(np.dot(self.W_hh, hidden) + np.dot(self.W_xh, x))
-
return hidden
-
-
rnn = RNN()
-
# x: [batch_size * seq_len * input_size]
-
x = get_data()
-
seq_len = x.shape[1]
-
# 初始化一个hidden_state,RNN中的参数没有包括hidden_state,
-
# 只包括hidden_state对应的权重W和b,
-
# 所以一般我们会手动初始化一个全零的hidden_state
-
hidden_state = np.zeros()
-
# 下面这个循环就是RNN的工作流程了,看到没有,每次输入的都是一个时间步长的数据,
-
# 然后同一个hidden_state会在循环中反复输入到网络中。
-
for i in range(seq_len):
-
hidden_state = rnn(x[:, i, :], hidden_state)
原文链接:https://blog.csdn.net/ld_long/article/details/113784788
-
import torch
-
#简单RNN学习举例。
-
# RNN(循环神经网络)是把一个线性层重复使用,适合训练序列型的问题。单词是一个序列,序列的每个元素是字母。序列中的元素可以是任意维度的。实际训练中,
-
# 可以首先把序列中的元素变为合适的维度,再交给RNN层。
-
#学习 将hello 转为 ohlol。
-
-
dict=['e','h','l','o'] #字典。有4个字母
-
x_data=[1,0,2,2,3] #输入hello在字典中的引索
-
x_data=torch.LongTensor(x_data) #后面要用到把引索转化为高维向量的工具,那个工具要求输入是LongTensor而不是默认的floatTensor
-
y_data=torch.LongTensor([3,1,2,3,2]) #后面用到的交叉熵损失要求输入是一维longTensor。LongTensor的类型是长整型。
-
-
# 上边提到的把引索转为高维向量的工具,可以理解为编码器。引索是标量,编出的码可以是任意维度的矢量,在这个例子中
-
# 把从字典长度为4(只有4个不同的字母的字典)的字典中取出的5个字母hello构成一个序列,编码为5个(一个样本,这个样本有5个元素,也就是
-
# batch_size=1,seqlen(序列长度)=5,1*5=5)10维向量(bedding_size=10)。
-
# 然后通过RNN层,降维为5个8维向量(hidding_size=8)。RNN层的输入形状是样本数*序列长度*元素维度,(本例中是1*5*10)RNN的输入有两个,这里我们关心第一个输出
-
# 它的形状为样本数*序列长度*输出元素维度(本例中为1*5*8)。
-
# 然后把RNN层的输出视为(样本数*序列长度)*输出元素维度(本例:5*8)的向量交给全连接层降维为5*4。4是因为这是个多分类问题,输入的每个字母对应哪个分类。
-
# 这里输出分类类别只有4个。(num_class=4)
-
# 把得到5*4张量交给交叉熵损失计算预测与目标的损失。(后面的工作就是多分类的工作了)。
-
class rnnmodel(torch.nn.Module):
-
def __init__(self,dictionary_size,num_class):
-
super(rnnmodel, self).__init__()
-
self.hidden_size=8
-
self.bedding_size=10
-
self.dictionary_size=dictionary_size
-
self.num_class=num_class
-
self.embeddinger=torch.nn.Embedding(self.dictionary_size,self.bedding_size) #把5个引索转化为5个张量。并继承输入的维度。(本例中继承batch_size*seglen),
-
# 输出为batch_size*seglen*bedding_size
-
self.rnn=torch.nn.RNN(input_size=self.bedding_size,hidden_size=self.hidden_size,num_layers=1,batch_first=True)
-
# 指定batch_fisrt=True,则要求输入维度为batch_size*seglen*input_size,否则,要求输入为seglen*input_size。
-
# 指定batch_fisrt=True要求的输入形状更方便与构建数据集。数据集的原始维度就是这样的。
-
# batch_fisrt默认为false ,之所以为false,是因为seglen*input_size这样的形状更有利于RNN的实现。
-
self.linear=torch.nn.Linear(self.hidden_size,self.num_class) #10维降为4维。
-
def forward(self,x): #x 的形状为(样本数,序列长度)
-
h0=torch.zeros(1,x.size(0),self.hidden_size) #RNN要有两个输入,x为数据,h为序列中上一个元素计算的结果。由于第一个元素没有
-
#上一个元素,所以要指定一个初始值。如果没有先验数据,一般设置为全0。它的形状为num_layer*batch_size*hidden_size。num_layers是什么,本人很懒不想画图,其他博客对这个的解释
-
#非常清晰。
-
x=self.embeddinger(x)
-
x,_=self.rnn(x,h0) #x的形状为(样本数,序列长度,每个单元的维度)
-
x=x.view(-1,self.hidden_size) #合并前两个维度,放入全连接层计算。如果需要,计算完之后再拆分。
-
x=self.linear(x)
-
return x
-
-
if __name__=='__main__':
-
model=rnnmodel(4,4)
-
criterion=torch.nn.CrossEntropyLoss()
-
optimizer=torch.optim.Adam(model.parameters(),lr=0.1)
-
x_data=x_data.view(-1,5)
-
y_data=y_data.view(-1)
-
for epoch in range(15):
-
y_hat=model(x_data)
-
_,index=torch.max(y_hat,1)
-
index=index.data.numpy()
-
loss=criterion(y_hat,y_data)
-
-
print(epoch,' loss:', loss.item(),'guess:',''.join([dict[x] for x in index]))
-
optimizer.zero_grad()
-
loss.backward()
-
optimizer.step()
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/125494987

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)