DETR3D 多2d图片3D检测框架

最近在自动驾驶的圈子里掀起了一股在BEV(Bird's Eye View, 鸟瞰图)下对相机做目标检测的风潮,而掀起这股风潮的工作之一就是咱们MARS Lab与MIT, TRI还有理想汽车合作的CORL2021论文DETR3D。
下面就由陈炫耀同学来介绍我们的论文:DETR3D: 3D Object Detection from Multi-view Images via 3D-to-2D Queries[1]。
在自动驾驶的环视相机图像中做3D目标检测是一个棘手的问题,比如怎么去从单目相机2D的信息中预测3D的物体、物体形状大小随离相机远近而变化、怎么融合各个不同相机之间的信息、怎么去处理被相邻相机截断的物体等等。
将Perspective View转化为BEV表征是一个很好的解决方案,主要体现在以下几个方面:
- BEV是一个统一完整的全局场景的表示,物体的大小和朝向都能直接得到表达;
- BEV的形式更容易去做时序多帧融合和多传感器融合;
- BEV更有利于目标跟踪、轨迹预测等下游任务。
DETR3D方案

DETR3D模型的设计主要包括三部分:Encoder,Decoder和Loss。
Encoder
在nuScenes数据集中,每个样本含有6张环视相机图片。我们用ResNet去对每张图片进行encode来提取特征,然后再接一个FPN输出4层multi-scale features。
Decoder
Detection head共含有6层transformer decoder layer。类似于DETR,我们预先设置300/600/900个object query,每个query是256维的embedding。所有的object query由一个全连接网络预测出在BEV空间中的3D reference point坐标(x, y, z),坐标经过sigmoid函数归一化后表示在空间中的相对位置。
在每层layer之中,所有的object query之间做self-attention来相互交互获取全局信息并避免多个query收敛到同个物体。object query再和图像特征之间做cross-attention:将每个query对应的3D reference point通过相机的内参外参投影到图片坐标,利用线性插值来采样对应的multi-scale image features,如果投影坐标落在图片范围之外就补零,之后再用sampled image features去更新object queries。
经过attention更新后的object query通过两个MLP网络来分别预测对应物体的class和bounding box的参数。为了让网络更好的学习,我们每次都预测bounding box的中心坐标相对于reference points的offset(△x,△y,△z) 来更新reference points的坐标。
每层更新的object queries和reference points作为下一层decoder layer的输入,再次进行计算更新,总共迭代6次。
Loss
损失函数的设计也主要受DETR的启发,我们在所有object queries预测出来的检测框和所有的ground-truth bounding box之间利用匈牙利算法进行二分图匹配,找到使得loss最小的最优匹配,并计算classification focal loss和L1 regression loss。
实验结果
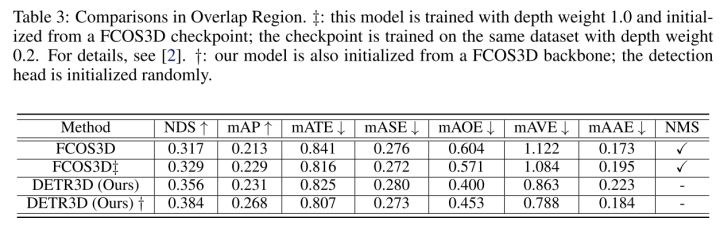
我们基于FCOS3D预训练的backbone进行训练,在没有使用NMS和test-time augmentation的情况下超过了FCOS3D的结果。

我们基于DD3D预训练的backbone进行训练,在nuScenes test set上得到了最好的结果。

对相邻环视相机重叠部分中被截断物体的的检测一直以来是一个难点,DETR3D通过直接在BEV下做检测的方法避免了相机之间的后处理过程,有效地缓解了这一问题。我们在重叠部分的mAP超过FCOS3D约4个点。
近期相关工作
DETR3D在去年10月在nuScenes上达到了第一的成绩。最近几个月在nuScenes的榜单上涌现了很多在BEV下做视觉3D目标检测的工作,看来我们的工作启发了很多领域内的同行,大家都在这个方向上面努力探索。

我们接下来对比一下DETR3D和最近的几篇工作并思考以下几个问题,希望能给大家带来一些启发。
- 如何将环视图像转化为BEV?
在DETR3D、BEVFormer[2]中,是通过reference points和相机参数的物理意义进行投影来获取图像features,这样的优点在于计算量较小,通过FPN的mutli-scale结构和deformable detr的learned offset,即使只有一个或几个reference points也可以得到足够的感受野信息。缺点在于BEV的同个polar ray上的reference point通过投影采样到的图像特征都是一样的,图像缺少了深度信息,网络需要在后续特征聚合的时候去判别采样到的信息和当前位置的reference points是否match。
在BEVDet[3]里,转化过程follow了lift-splat-shoot[4]的方法,也就是对image feature map的每个位置预测一个depth distribution,再将feature的值乘以深度概率lift到BEV下。这么做需要很大的计算量和显存,由于没有真实的深度标签,所以实际预测的是一个没有确切物理意义的概率。而且图片中相当一部分内容是不含有物体的,将全部feature参与计算可能略显冗余。
- 如何选择BEV的表现形式?
在DETR3D里,我们并没有完整显式地表示出了整个BEV,而且由sparse的object query来进行表示。最显著的好处就是节省了内存和计算量。而在BEVDet和BEVFormer里,他们生成了一个dense的BEV feature,虽然增加了显存,不过一来更容易去做BEV space下的data augmentation,二来像BEVDet一样可以另外增加对BEV features 的encoding,三来可以适应于各种3D detection head(BEVDet用了centerpoint,BEVFormer用了deformable detr)。
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/125466191

- 点赞
- 收藏
- 关注作者
评论(0)