hands-on-data-analysis 第二单元 第四节数据可视化

【摘要】
hands-on-data-analysis 第二单元 第四节数据可视化
文章目录
hands-on-data-analysis 第二单元 第四节数据可视化1.简单绘图1.1.导入库1.2.基本...
hands-on-data-analysis 第二单元 第四节数据可视化
1.简单绘图
1.1.导入库
#inline表示将图表嵌入到Notebook中
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
- 1
- 2
- 3
- 4
- 5
1.2.基本的绘图示例
import numpy as np
data = np.arange(10)
data
plt.plot(data)
- 1
- 2
- 3
- 4
1.3.子图示例
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
ax4 = fig.add_subplot(2,2,4)
- 1
- 2
- 3
- 4
- 5

1.4.子图绘图示例
fig = plt.figure()
ax1 = fig.add_subplot(2,2,1)
ax2 = fig.add_subplot(2,2,2)
ax3 = fig.add_subplot(2,2,3)
#k--是绘制黑色分段线的选项
plt.plot(np.random.randn(50).cumsum(),'k--')
_ = ax1.hist(np.random.randn(100),bins=20,color='k',alpha=0.3)
ax2.scatter(np.arange(30),np.arange(30)+3*np.random.randn(30))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.5. pyplot.subplots选项
| 参数 | 描述 |
|---|---|
| nrows | 子图的行数 |
| ncols | 子图的列数 |
| sharex | 所有子图使用相同的x轴刻度(调整xlim会影响所有子图) |
| sharey | 所有子图使用相同的y轴刻度(调整ylim会影响所有子图) |
| subplot_kw | 传入add_subplot的关键字参数字典,用于生成子图 |
| **fig_kw | 在生成图片时使用的额外关键字参数,例如plt.subplot(2,2,figsize(8,6)) |
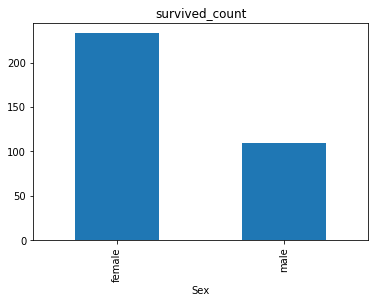
2.可视化展示泰坦尼克号数据集中男女中生存人数分布情况
sex = text.groupby('Sex')['Survived'].sum()
sex.plot.bar()
plt.title('survived_count')
plt.show()
- 1
- 2
- 3
- 4
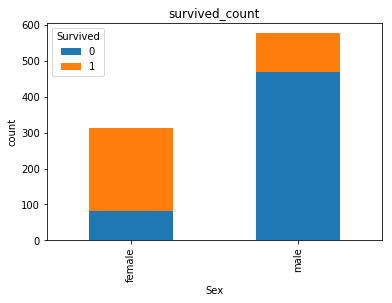
3.可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图
text.groupby(['Sex','Survived'])['Survived'].count().unstack().plot(kind='bar',stacked='True')
plt.title('survived_count')
plt.ylabel('count')
- 1
- 2
- 3
4.可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。
# 计算不同票价中生存与死亡人数 1表示生存,0表示死亡
fare_sur = text.groupby(['Fare'])['Survived'].value_counts().sort_values(ascending=False)
fare_sur
- 1
- 2
- 3
fig = plt.figure(figsize=(20, 18))
fare_sur.plot(grid=True)
plt.legend()
plt.show()
- 1
- 2
- 3
- 4
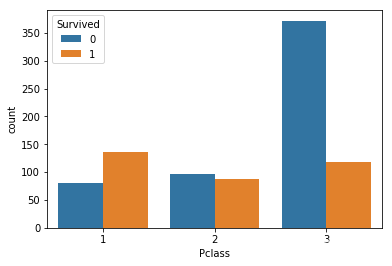
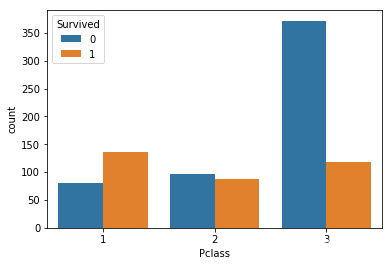
5.可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况
# 1表示生存,0表示死亡
pclass_sur = text.groupby(['Pclass'])['Survived'].value_counts()
pclass_sur
- 1
- 2
- 3
import seaborn as sns
sns.countplot(x="Pclass", hue="Survived", data=text)
- 1
- 2
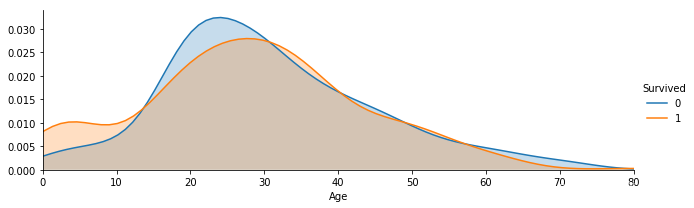
6.可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况
facet = sns.FacetGrid(text, hue="Survived",aspect=3)
facet.map(sns.kdeplot,'Age',shade= True)
facet.set(xlim=(0, text['Age'].max()))
facet.add_legend()
- 1
- 2
- 3
- 4
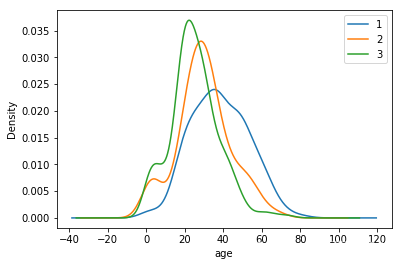
7.可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。
text.Age[text.Pclass == 1].plot(kind='kde')
text.Age[text.Pclass == 2].plot(kind='kde')
text.Age[text.Pclass == 3].plot(kind='kde')
plt.xlabel("age")
plt.legend((1,2,3),loc="best")
- 1
- 2
- 3
- 4
- 5
文章来源: blog.csdn.net,作者:沧夜2021,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/CANGYE0504/article/details/125379119

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)