CVPR 2022 Oral 大连理工提出SCI:快速、超强的低光照图像增强方法

分三个模型 easy.pt medium.pt difficult.pt,每个模型43k,
Toward Fast, Flexible, and Robust Low-Light Image Enhancement
论文:https://arxiv.org/abs/2204.10137
代码:https://github.com/vis-opt-group/SCI
本文提出了一种全新的低光照图像增强方案:自校准光照学习(SCI)。通过构建引入自校准模块的权重共享光照学习过程,摒弃了网络结构的繁杂设计过程,实现了仅使用简单操作进行增强的目的。大量实验结果表明,SCI在视觉质量、计算效率、下游视觉任务应用方面均取得了突破(见图1)。该研究已被CVPR 2022收录为Oral。

图1 本文提出方法与其他方法的结果对比
研究背景
低光照图像增强作为图像处理中的经典任务,在学术界与工业界均受到了广泛关注。2018-2020年连续举办三届的UG2+Prize Challenge比赛将低光照人脸检测作为主竞赛单元,极大程度推动了学术界对于低光照图像增强技术的研究。某手机厂商于2019年发布会上将暗光拍摄能力作为主打亮点,掀起了工业界利用深度学习技术解决低光照图像增强的又一波浪潮。
现有的低光照图像增强技术聚焦于构建数据驱动的深度网络,通常其网络模型复杂,导致计算效率低、推理速度慢,并且由于对于训练数据分布的依赖性导致其在未知场景下的性能缺乏保障。总的来说,现有技术普遍缺乏实用性。为解决以上问题,本文致力于从学习策略入手,构建一种快速、灵活与稳健的低光照图像增强方案。
本文方法
(1)权重共享的光照学习
根据Retinex理论,低光照观测图像等于清晰图像与光照的点乘,即
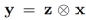
。在基于该模型设计的方法中,光照的估计通常被视为主要的优化目标,得到精确的光照后,清晰图像能够上述关系直接得到。受现有工作的逐阶段光照优化过程启发,本文构建渐进式的光照优化过程,其基本单元如下所示:

其中

与分别表示第t阶段的残差与光照。表示光照估计网络。需要注意的是这里与阶段数无关,即在每一阶段光照估计网络均保持结构与参数共享状态。进一步理解该模块能够发现,在渐进式优化与参数共享机制下,每个阶段均希望得到与目标接近的输出。换句话说,是否存在一种可能,能够令每个阶段的输出尽可能接近且与目标一致,这样一来,多阶段级联测试变为单阶段测试,将大幅减少推理代价。为实现该目标,如下引入了一种自校准模块。
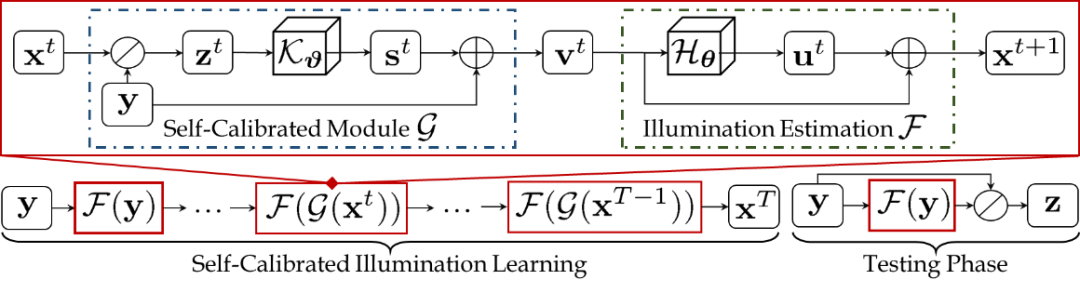
图2 本文算法流程图
(2)自校准模块
该模块的目的在于从分析每个阶段之间的关系入手,确保在训练过程中的不同阶段的输出均能够收敛到相同的状态。自校准模块的公式表达如下所示:
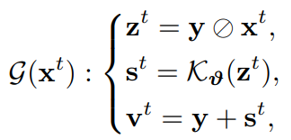
其中

是校准后的用于下一阶段的输入。也就是说,原本的光照学习过程中第二阶段及以后的输入变成了由上述公式得到的结果(总的计算流程如图2所示),即光照优化过程的基本单元被重新公式化为:
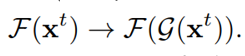
实际上,该自校准模块通过引入物理规律(即Retinex理论),逐步校正了每一阶段的输入来间接地影响了每一阶段的输出,进而实现了阶段间的收敛。图3探究了自校准模块的作用,可以发现,自校准模块的引入使得不同阶段的结果能够很快地收敛到相同状态(即三个阶段的结果重合)。

图3 关于测试阶段是否采用自校准模块的增强结果t-SNE分布对比(阶段数为3)
(3)无监督损失函数
为了更好地训练提出的学习框架,该部分设计了一种无监督损失函数,以约束每一阶段的光照估计,公式表示如下:

其中前一项与后一项分别代表数据保真项及平滑正则项(关于各个变量的详细说明请参见论文)。
实验结果
(1)定量分析
表1展示了在著名的MIT-Adobe FiveK数据集上的定量结果对比,可以看出,提出方法取得了最优性能。值得注意的是,尽管提出方法为无监督方法,但其在PSNR与SSIM这类有参考指标上的结果均实现了最优,究其原因在于该数据集的Ground Truth是由专家修饰得到的,也说明了提出方法生成的结果更符合人类视觉习惯。
表1 在MIT-Adobe FiveK数据集上的定量结果对比

(2)真实场景下的视觉对比
图4展示了两组在有难度的真实场景下的增强结果对比。可以看出,相比于其他的方法,提出方法的增强结果亮度适中、细节丰富、色调自然、具有更高的视觉质量。

图4 真实场景下的增强结果对比
(3)下游任务性能分析
为了进一步探究SCI的优势,本文比较了在低光照人脸检测与夜间语义分割两个下游任务的性能。在低光照人脸检测任务中,定义了两种与SCI相关的版本,一种是将SCI作为预处理来实现数据的亮度增强(其他对比方法采用相同方式)并在该数据基础上微调检测网络,另一种是SCI与检测网络联合微调(记为SCI+)。图5中展示了检测结果,可以看出,本文提出的方法具有明显优势,能够检测出更多的小目标。
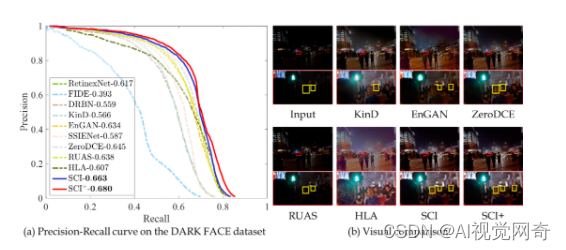
图5 低光照人脸检测结果对比
图6展示了夜间语义分割性能,可以看出,SCI获得了有竞争的数值结果,同时在类别划分上更准确,边缘刻画更清晰。
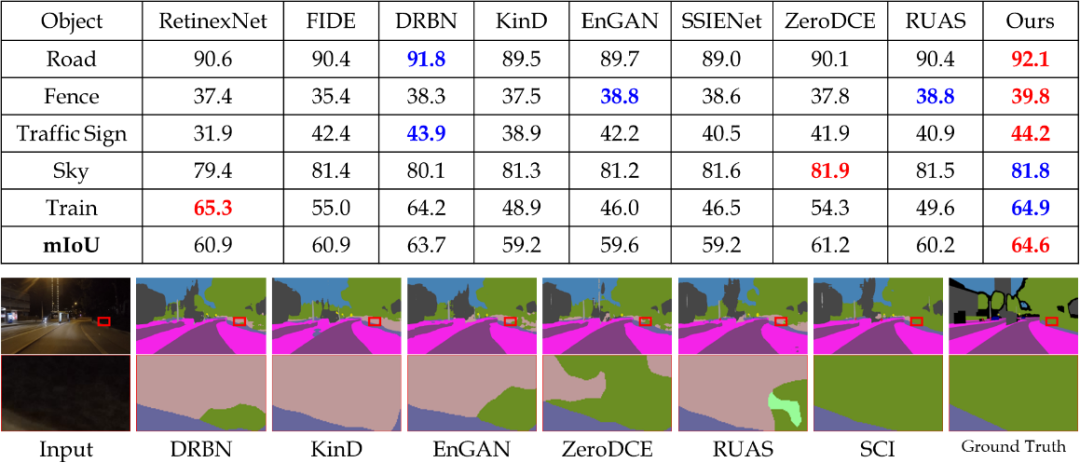
图6 夜间语义分割结果对比
总结与展望
本文提出的SCI在图像质量和推理速度方面均取得了突破,为低光照图像增强任务的解决提供了一种新的视角,即如何在有限资源下赋予网络模型更强的刻画能力,该种视角相信也能够为其他相关视觉增强领域带来启发。未来,作者将继续探究如何设计更有效的学习手段来建立轻量、鲁棒、面向更具有挑战真实场景的低光照图像增强方案。
文章来源: blog.csdn.net,作者:AI视觉网奇,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jacke121/article/details/125242059

- 点赞
- 收藏
- 关注作者
评论(0)