系统设计之图状数据模型

多对多关系是不同数据模型之间的重要区别特征。若数据大多是一对多(树结构数据)或记录之间无关系,则文档模型最合适。但若多对多关系的数据很常见,关系模型能处理简单的多对多,但随数据之间关联复杂度增加,将数据建模转化为图模型更自然。
图的组成:
- 顶点(也称为结点或实体)
- 边(也称为关系或弧)
很多数据能建模为图。典型案例:
-
社交网络
顶点是人,边指示哪些人彼此认识
-
Web图
顶点是网页,边表示与其他页面的HTML链接
-
公路或铁路网
顶点是交叉路口,边表示他们之间的公路或铁路线
很多著名算法可在这些图上运行。如汽车导航系统搜索道路网中任意两点之间最短路径, PageRank计算Web图上网页的流行度,从而确定搜索排名。
图的顶点表示相同类型的事物(分别是人、网页或交叉路口)。然而,图不局限于这样的同构数据,图更为强大的用途在于提供了单个数据存储区中保存完全不同类型对象的一致性方式。如Facebook维护一个含许多不同类型的顶点与边的大图:
- 顶点包括人、地点、事件、签到和用户的评论
- 边表示哪些人是彼此的朋友,签到发生在哪些位置, 谁评论了哪个帖子, 谁参与了哪个事件
本文下图示例
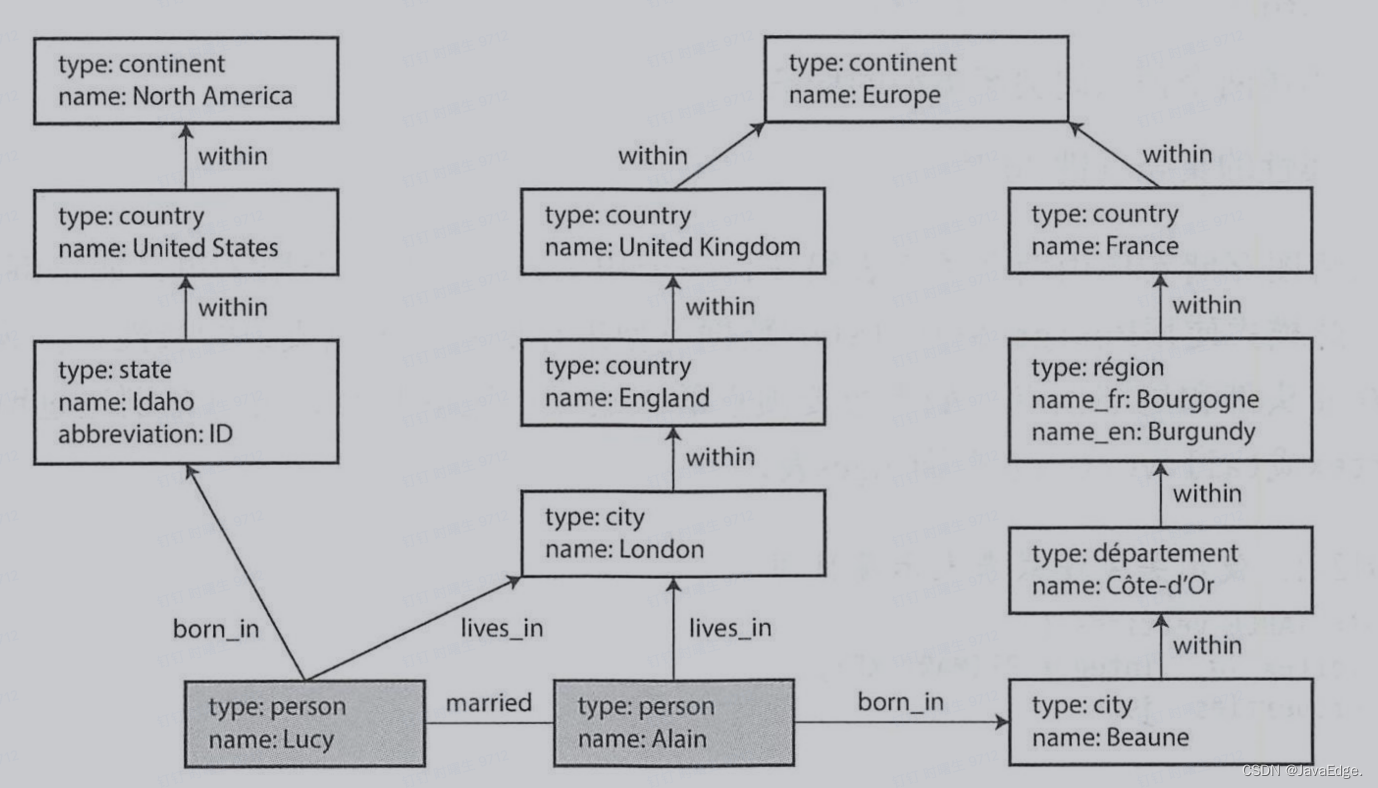
它可能来自社交网络或某族谱数据库。 案例是两个人,分别来自爱达荷州的Lucy和来自法国波恩的Alain,它们结婚了,目前住在伦敦。
有多种不同但相关的方法可构建和查询图中的数据。本节将讨论属性图模型和三元存储模型。
属性图
在属性图模型中,每个顶点包括:
- 唯一标识符
- 出边的集合
- 入边的集合
- 属性的集合(键-值对)
每个边包括:
- 唯一标识符
- 边开始的顶点(尾部顶点)
- 边结束的顶点(头部顶点)
- 描述两个顶点间关系类型的标签
- 属性的集合 (键-值对)
可将图存储作由两个关系表组成,一个用顶点, 另一个用边

此模式使用PostgreSQL JSON存储每个顶点或边的属性)。为每个边存储头部和尾部顶点,若想要顶点的入边或出边集合 ,可分别通过head_vertex 或tail_vertex来查edges表。

图模型重点:
- 任何顶点都能连接到其他任一顶点。没有模式限制哪种事物可或不可关联
- 给定某顶点,可高效得到它的所有入、出边,从而遍历图,即沿着这些顶点链条一直向前或向后(这就是为何图2-2中在tail_vertex和 head_vertex列上都建立索引的原因)
- 通过对不同类型的关系使用不同标签,可在单个图中存储多种不同类型的信息,同时仍保持整洁的数据模型
这些特性为数据建模提供灵活性,如图1,显示了一些传统关系模式很难表达的东西,如不同国家的不同类型的地区结构(中国有省和区,而美国有县和州),特殊历史原因及不同粒度的数据( Lucy当前住所被指定为一个城市,而她的出生地则是州一级)。
可将这个图扩展到包括许多关于Lucy 和 Alian的其他信息或其他人。例如,可用来表示他们的任何食物过敏(通过为每个过敏源引人顶点及人与过敏原之间的边来表示过敏),并将过敏掘与顶点的集合联结,这些顶点显示哪些食物含有哪些物质。然后,可以编写一个查询找出每个人吃啥安全。图有利于演化:向应用添加功能时,图很容易扩展以适应数据结构的不断变化。
-- 采用 Cypher 查询从美国移民到欧洲的人员名单
MATCH
(person) -[:BORN_IN]-> ()-[:WITHIN*O..]->(us:Location{name:'United States'}),
(person) -[:LIVE S_IN ]->()-[: WITHIN*O..]- > (eu:Location{name:'Eu rope'})
RETURN person.name
SQL 中的图查询
示例2说名能使用关系数据库表示图数据,这是否意味着也支持SQL查询?
答案是肯定的,但存在一些困难。在关系数据库中,通常会预知查询需要哪些join操作。而对于图查询, 找到要找的顶点前,可能需遍历数量未知的边,即join操作数量无法预知。
SQL1999标准后, 查询过程中这种可变的遍历路径可使用“递归公用表表达
式”(即WITH RECURSIVE语法)来表示。示 2-5 采用该技术的SQL表达来执行相同的
查询(查找从美国移民到欧洲的人员名单 ),目前PostgreSQL IBM DB2, Oracle
SQL Server 支持该技术 ,但与Cypher丰目比,语法仍显得非常笨拙。
in usa(vertex_id) AS (
-- 首先找到name属性值为United States的顶点,并将其作为顶点集in_usa中的第一个元素
SELECT vertex_id FROM vertces WHERE properties->>'name'='United States'
UNION
-- 沿集合in_usa中顶点的所有入边within,并将它们添加到同一集合,直到遍历所有入边
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id WHERE edges.label='within'
);
-- in_europe is the set of vertex IDs of all locations within Europe
in europe(vertex_id) AS (
-- 从name属性值为Europe的顶点开始执行同样操作,并建立顶点集in_europe
SELECT vertex_id FROM vertices WHERE properties->>'name'='Europe'
UNION
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'within'
);
-- born_in_usa is the set of vertex IDs of all people born in the US
born_in_usa(vertex_id) AS (
-- 对in_usa集合中的每个顶点,按入边born_in来查找出生在美国境内某地的人
SELECT edges.tail_vertex FROM edges
JOIN in_usa ON edges.head_vertex = in_usa.vertex_id
WHERE edges.label = 'born_in'
);
-- lives_in_europe is the set vertex IDs of all people living in Europe
lives_in_europe(vertex_id) AS (
-- 类似地,对in_europe集合中的每个顶点,按入边lives_in来查找居住在欧洲的人
SELECT edges.tail_vertex FROM edges
JOIN in_europe ON edges.head_vertex = in_europe.vertex_id
WHERE edges.label = 'lives_in'
);
SELECT vertices . properties->>'name'
FROM vertices
-- join to find t ho se peo ple who were both born in the US *a nd * live i n Europe
-- 最后,通 join 把在美国出生的人的集合与在欧洲居住的人的集合相交
JOIN born_in_usa ON vertices.vertex_id = born_in_usa.vertex_id
JOIN lives_in_europe ON vertices.vertex_id = lives_in_europe.vertex_id;
若相同查询可以用一种查询语言写4行代码完成,而另一种查询语需29行,足以说明不同数据模型适用不同场景。因此,选择适合应用程序的数据模型很重要!
三元存储与SPARQL
三元存储模式几乎等同属性图模型,不同名词描述相同思想而已。尽管如此,考虑到有多种针对三元存储的工具 ,它们可能是构建应用程序宝贵补充,因此还是值得讨论。
三元存储中,所有信息都以简单的三部分形式存储(主体,谓语,客体) 。如在三元组 (吉姆,喜欢,香蕉 )中:
-
吉姆是主体
相当于图中的顶点
-
喜欢是谓语 (动词)
-
香蕉是客体
客体是以下两种之一:
- 原始数据类型中的值 ,如字符串或数字。这时,三元组的谓语和客体分别相当于主体(顶点)属性中的键和值。如(lucy,age,33)就好比是顶点lucy,具有属性{“age”: 33}
- 图中的另一个顶点。此时,谓语是图中的边,主体是尾部顶点,而客体是头部顶
点。如(lucy,marriedTo,alain)中,主体lucy和客体alain都是顶点,谓语marriedTo是连接二者的边的标签
示例3:以 Turtle 三元组表示图1中的一部分数据

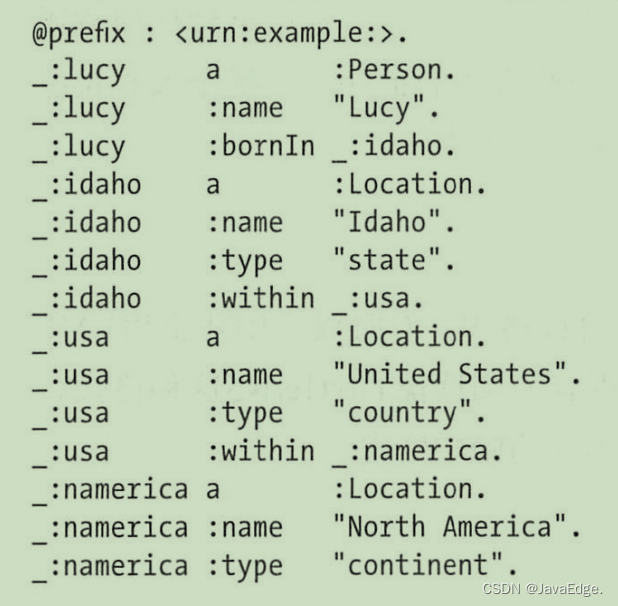
图的顶点被写为_:someName。顶点的名字在定义文件以外没有任何意义,只是为区分三元组的不同顶点。谓语表示边时,客体是另一个顶点,如 _:idaho :within _:usa 。当谓语表示一个属性时,该客体则是一个字符串,如 _:usa :name “United States”
若定义相同主体的多个三元组,反复输入相同单词就略显枯燥。可使用分号说明同一主体的 多个对象信息。这样 Turtle 格式就更简洁、可读性强。以更简洁语法重写示例3:

语义网
若阅读更多关于三元存储的信息,很可能会被卷入关于语义网大量文章漩涡之中。
三元存储数据模型其实完全独立于语义网,例如,Datomic是个三元存储,它和语义网并无任何关系年。但考虑到很多人觉得二两者紧密相连,有必要澄清。
语义网,本质上源于一个简单合理的想法:网站通常将信息以文字和图片方式发布给人类阅读,为何不把信息发布为机器可读的格式给计算机阅读呢?资源描述框架(Resource Description Framework, RDF)就是这样一种机制, 它让不同网站以一致格式发布数据,这样不同网站的数据自动合并成一个数据网络,一种互联网级别包含所有数据的数据库。
但语义网在21世纪初被严重夸大,时至今日也未在实践中见到任何靠谱实现,由此许多人开始怀疑。另外,还有其他一些方面批评,包括令人眼花缭乱的各种缩略词、极其复杂的标准提议,以及过于自大的标榜。

- 点赞
- 收藏
- 关注作者
评论(0)