系统架构设计(3)-可扩展性

即使系统现在可靠,不代表将来一定可靠。发生退化的最常见原因是负载增加:并发用户从最初的10,000 增长到 100,000或系统目前处理数据量超出之前很多倍。
可扩展性,描述系统应对负载增加的能力。它不是衡量一个系统的一维指标, 谈论“系统X是可扩展 ”或“不扩展”无太大意义。相反,讨论可扩展性通常得考虑:“若系统以某种方式增长,应对措施有啥”, “该如何添加计算资源来处理额外的负载”
3.1 描述负载
先得简洁描述系统当前的负载,才能更好讨论后续的增长问题(例如负载加倍,意味啥?)。负载可以用称为负载参数的若干数字来描述。参数的最佳选择取决于系统的体系结构,它可能是:
- 服务器的请求处理次数/s
- 数据库中写入的比例
- 聊天室的同时活动用户数量
- 缓存命中率
有时平均值很重要,但有时系统瓶颈来自少数峰值(大促时期尤为明显)。比如Twitter两个典型业务操作:
- 发推文:用户可快速推送新消息到所有粉丝,平均大约4.6k request/s, 峰值约12k requests/sec
- 页时间线(Home timeline)浏览:平均300k requests/s 查看关注对象的最新消息
仅处理峰值12k的消息发送看起来不难,但扩展性挑战重点其实不在消息大小,而是巨大的扇出( fanout,电子工程的术语,描述输入的逻辑门连接到另一个输出门的数量。输出需提供足够电流驱动所有连接的输入。事务处理系统中,用来描述为了服务一个输入请求而需要做的请求总数)结构:每个用户会关注很多人,也会被很多人圈粉。
对此有如下的
处理方案
方案一:关系型数据模型
将发送的新推文插入全局的推文集合。当用户查看时间线,首先找所有的关注对象,列出这些人的所有推文,以时间为序来排序合并。若以如下的采用关系型数据模型来支持时间:

可执行SQL:
SELECT tweets.*, users.*
FROM tweets
JOIN users ON tweets.sender_id = users.id
JOIN follows ON follows.followee_id = users.id
WHERE follows.follower_id = current_user
方案二:数据流水线万式推送
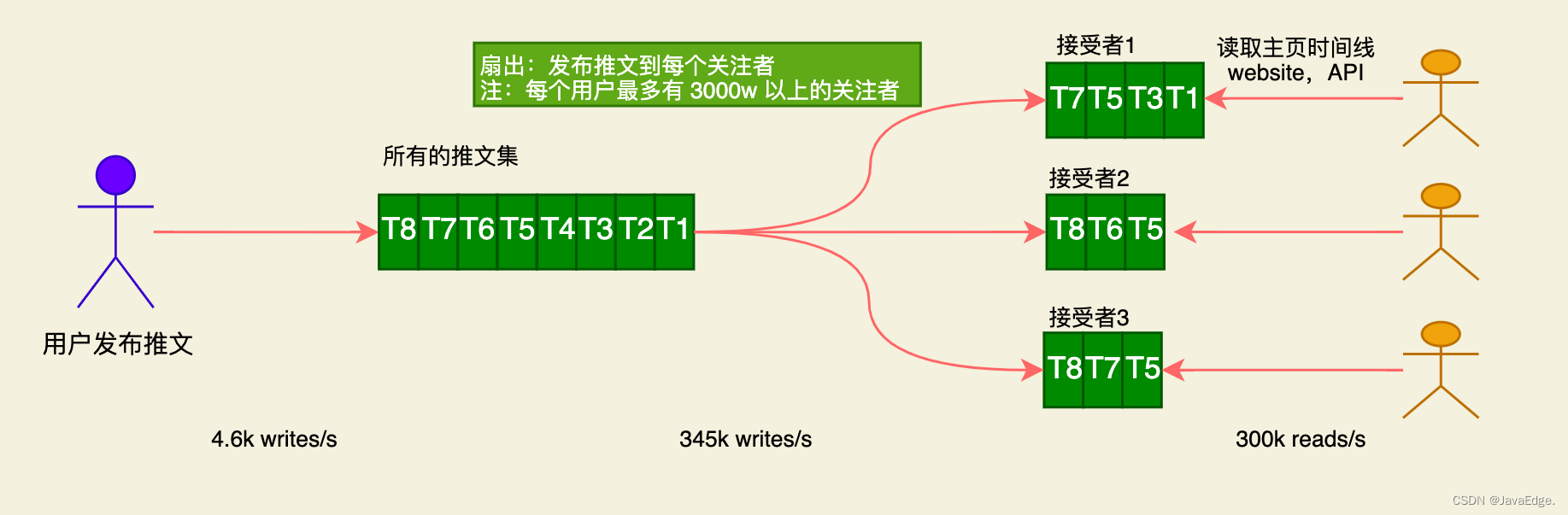
对每个用户的时间线维护一个缓存 ,类似每个用户一个推文邮箱。当用户推送新推文,查询其关注者,将推文插入到每个关注者的时间线缓存中。因为已预先将结果取出,之后访问时间就是线性性能,很快。
Twitter最初使用方案一,但发现主页时间线的读负载压力与日俱增,系统优化之路曲折,于是转向方案二,实践证明更好,因为时间线浏览推文的压力几乎比发布推文要高出两个数量级,基此,在发布时多完成一些事情可加速读性能。其实方案二的缺点也明显,在发布tweet时增加大量额外工作。考虑平均75个关注者和4.6k/s的tweet,则需每秒4.6*75 = 345k的速率写入缓存。但75这个平均关注者背后还隐藏其他事实,即关注者其实偏差巨大,例如某些用户拥有超过3000w的追随者。这就意味着峰值情况下一个tweet会导致3000w次写入!而且要求尽量快, Twitte目标是5s内完成,成为巨大挑战!
每个用户关注者的分布情况(还能结合用户使用推特的频率进行加权)是该案例可扩展的关键负载参数,因为它决定了扇出数。你的应用可能具有不同特性,但能采用类似原则研究具体负载。
Twitter案例最后是方案二得到稳定实现, Twitter正在转向结合两种方案。大多数用户的推文在发布时继续以一对多写入时间线,但少数大V用户除外,对这些用户采用类似方案一,其推文被单独提取,在读取时才和用户的时间线主表合井。这种混合方案能提供始终良好表现。
3.2 描述性能
描述系统负载之后,接下来设想如果负载增加将会发生什么。有两种考虑方式:
- 负载增加,但系统资源(如CPU 、内存、网络带宽等)保持不变,系统性能会如何变化?
- 负载增加,要保持性能不变,需增加多少资源?
这些都要关注性能指标。
批处理系统如Hadoop ,通常关心吞吐量(throughput),即每秒可处理的记录数或在某指定数据集上运行作业所需总时间。而在线系统通常更看重服务响应时间( response time),即客户端从发送请求到接收响应之间的间隔。
延迟( latency )与晌应时间( response time)
容易混淆的概念,并不完全一样。:
-
响应时间是客户端看到的 :除了处理请求时间(服务时间, service time )外,还包括来回网络延迟和各种排队延迟
-
延迟,请求花费在处理上的时间
即使反复发送、处理相同的请求,每次可能都会产生略微不同的响应时间。由于系统要处理各种不同请求,响应时间可能变化很大。因此,最好不要将响应时间视一个固定的数字,而是可度量的一种数值分布。
大多数请求的确快,但偶有异常,需要更长时间。这些异常请求有的确实代价高,如数据大很多。但有时,即使所有请求都相同,也会由于其他因素而引入随机的延迟抖动,比如上下文切换和进程调度、网络数据包丢失和TCP重传、垃圾回收暂停、缺页中断和磁盘I/O ,甚至服务器机架的机械振动等。
平均响应时间
服务请求的平均响应时间不是合适指标 ,因为掩盖一些信息,不能说明多少用户实际经历了多少延迟。最好用百分数(percentiles) 。
百分数(percentiles)
若已搜集到响应时间信息,按最快到最慢排序,若中位数响应时间200ms ,那意味着有一半请求响应不到200 ms ,而另一半请求需更长时间。中位数指标适合描述多少用户需等待多长时间: 一半用户请求的服务时间少于中位数响应时间,另一半则多于中位数的时间。因此中位数也称为50百分位数,缩写为p50 。中位数对应单个请求,这也意味着若某用户发了多个请求(例如包含在一个完整会话过程中或因某页面包含了多个资源),那么它们中
至少一个比中位数慢的概率远远大于50%。为弄清楚异常值,需关注更大的百分位数,如常见的第95、99、99.9 (缩写为p95、p99、p999 )值,分别表示有95%、99%、99.9%的请求响应时间快于阈值。 即若95百分位数响应时间为1.5s ,表示100个请求中的95个请求快于1.5s,而5个请求则需要1.5或更长时间。
采用较高的响应时间百分位数( tail latencies,尾部延迟或长尾效应)很重要,因为它们直接影响用户总体服务体验。如亚马逊采用99.9百分位数定义内部服务的响应时间标准,或许它仅影响1000个请求中的1个。但考虑到请求最慢的客户往往是买了更多商品,因此数据量更大。换言之, 他们是最有价值的客户。让这些客户始终保持愉悦的购物体验不是非常重要吗?亚马逊还注意到,响应时间每增加l100ms ,销售额就会下降约1%,其他研究则表明, 1s延迟增加等价于客户满意度下降6%。
有人说,优化这99.99百分位数(10,000个请求中最慢那1个)ROI 太低,进一步提高响应时间技术上代价更大,很容易受到非可控因素,如随机事件的影响,累积优势会减弱。
例如,百分位数通常用于描述、定义服务质量目标( Service Level Objectives, SLO )和服务质量协议( Service Level Agreements, SLA ),这些是规定服务预期质量和可用性的合同。例如一份SLA合约,通常会声明响应时间中位数小于200ms,99%请求的响应时间小于1s,且要求至少99.9%的时间都要达到上述服务指标。这些指标明确了服务质量预期,并允许客户在不符合SLA的情况下进行赔偿。
排队延迟往往在高百分数响应时间中影响大。由于服务器并行处理的请求有限(CPU核心数限制),正在处理的少数请求可能会阻塞后续请求,这种情况有时称为队头阻塞。即使后续请求可能处理简单,但它阻塞在等待先前请求的完成,客户端将会观察到极慢响应时间。因此,很重要的一点是要在客户端来测量响应时间。
所以,为了测试系统的可扩展性而人为地产生负载时,负载生成端要独立于响应时间来持续
发送请求。若客户端在发送请求之前总是等待先前请求的完成,就会在测试中人为缩短服务器端的累计队列深度,带来测试偏差。
3.3 应对负载增加的方案
现在真正讨论可扩展性了,当负载参数增加时, 如何继续保持良好性能呢。
实践中的百分位数
后台服务,若一次完整的服务包含多次请求调用,此时高百分位数指标尤为重要。 即使这些子请求是并行发送、处理,但最终用户仍然需等待最慢的那个调用完成。如下图 ,哪怕1个缓慢的请求处理,即可拖累整个服务。

即使只有很小百分比的请求缓慢,若某用户总是频 产生这种调用 ,最终总休变慢的概率就会增加(即长尾效应)。
最好将响应时间百分位数添加到服务系统监控 ,持续跟踪该指标。如设一个20min滑动窗口,监控其中的响应时间,滚动计算窗口中的中位数和各种百分位数,然后绘制性能图。一种简单的实现方案:在时间窗口内保留所有请求的响应时间列表,每分钟做1次排序。若这种方式效率太低,可采用一些近似法(如正向表减、t-digest或HdrHistogram)来计算百分位数,其CPU和内存开销很低。同时注意,降低采样时间精度或直接组合来自多台机器的数据,在数学上没有太大意义,聚合响应时间的正确方法是采用直方图。
针对特定级别负载而设计的架构不大可能应付超出预设目标10倍的实际负载。若目标服务处于快速增长阶段,则需要认真考虑每增一个数量级的负载,架构应如如何设计。
现在谈论更多的是如何在垂直扩展(升级更强大机器)和水平扩展(将负载分布到多个更小机器)之间取舍。在多台机器上分配负载也被称为无共享体系结构。在单台机器上运行的系统通常更简单,而高端机器昂贵,且扩展水平有限,所以无法避免需要水平扩展。好架构通常要做取舍,例如,使用几个强悍服务器仍可以比大量小型虚拟机来得更简单、便宜。
某些系统具有弹性特征,自动检测负载增加,然后自动添加更多计算资惊,而其他系统则得手动扩展(人工分析性能表现,之后再决定是否添加)。若负载高度不可预测,则自动弹性系统会更高效 ,但或许手动能减少执行期间的意外情况。
-
无状态服务分布然后扩展至多台机器相对比较容易
-
有状态服务从单节点扩展到分布式多机环境的复杂性会大大增加
因此,直到最近通常的做法一直是,将数据库运行在一个节点(采用垂直扩展策略),直到高扩展性或高可用性的要求迫使不得不做水平扩展。
而随分布式系统发展,至少对某些应用,上述通常做法或许会改变。乐观地说 ,即使应用可能并不会处理大量数据或流量,但未来分布式数据系统将成为标配。
超大规模系统往往针对特定应用而高度定制,很难有通用架构。背后取舍因素包括数据读取量、写入量、待存储的数据量、数据复杂度、 响应时间要求、访问模式等或更多的是上述所有因素叠加,再加上其他更复杂问题。
例如,即使两系统数据吞吐量折算后一样,但为每秒处理100,000 次请求(每个大小为1KB )而设计的系统,和为3个请求/min(每个大小2GB )设计的系统大不相同。
对特定应用来说,扩展能力好的架构通常会做出某些假设,然后有针对性地优化设计,如哪些操作最频繁,哪些负载是少数情况。若这些假设最终发现是错误的,则可扩展性的努力就白费了,甚至会出现与设计预期完全相反情况。对初创公司或尚未定型产品,快速迭代推出产品功能往往比技入精力来应对不可知的扩展性更重要。
可扩展架构一般从通用模块逐步构建而来,背后往往有规律可循,所以我们会多讨论这些通用模块和常见模式。

- 点赞
- 收藏
- 关注作者
评论(0)