《机器学习系统》案例:机器学习工作流

机器学习工作流
机器学习系统编程模型的首要设计目标是:对开发者的整个工作流进行完整的编程支持。一个常见的机器学习任务一般包含如图所示的流程。这个工作流完成了训练数据集的读取,模型的训练,测试和调试。通过归纳,我们可以将这一工作流中用户所需要自定义的部分通过定义以下API来支持(我们这里假设用户的高层次API以Python函数的形式提供):
- 数据处理: 首先,用户需要数据处理API来支持将数据集从磁盘读入。进一步,用户需要对读取的数据进行预处理,从而可以将数据输入后续的机器学习模型中。
- 模型结构: 完成数据的读取后,用户需要模型定义API来定义机器学习模型。这些模型带有模型参数,可以对给定的数据进行推理。
- 损失函数和优化算法: 模型的输出需要和用户的标记进行对比,这个对比差异一般通过损失函数(Loss function)来进行评估。因此,优化器定义API允许用户定义自己的损失函数,并且根据损失来引入(Import)和定义各种优化算法(Optimisation algorithms)来计算梯度(Gradient),完成对模型参数的更新。
- 训练过程: 给定一个数据集,模型,损失函数和优化器,用户需要训练API来定义一个循环(Loop)从而将数据集中的数据按照小批量(mini-batch)的方式读取出来,反复计算梯度来更新模型。这个反复的过程称为训练。
- 测试和调试: 训练过程中,用户需要测试API来对当前模型的精度进行评估。当精度达到目标后,训练结束。这一过程中,用户往往需要调试API来完成对模型的性能和正确性进行验证。

图2.2.1 机器学习系统工作流
2.2.1. 环境配置
下面以MindSpore框架实现多层感知机为例,了解完整的机器学习工作流。代码运行环境为MindSpore1.5.2,Ubuntu16.04,CUDA10.1。 在构建机器学习工作流程前,MindSpore需要通过context.set_context来配置运行需要的信息,如运行模式、后端信息、硬件等信息。 以下代码导入context模块,配置运行需要的信息。
import os
import argparse
from mindspore import context
parser = argparse.ArgumentParser(description='MindSpore MLPNet Example')
parser.add_argument('--device_target', type=str, default="CPU", choices=['Ascend', 'GPU', 'CPU'])
args = parser.parse_known_args()[0]
context.set_context(mode=context.GRAPH_MODE, device_target=args.device_target)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-twtEkShh-1653891679614)(https://raw.githubusercontent.com/choldgraf/sphinx-copybutton/master/sphinx_copybutton/_static/copy-button.svg)]
上述配置样例运行使用图模式。根据实际情况配置硬件信息,譬如代码运行在Ascend AI处理器上,则–device_target选择Ascend,代码运行在CPU、GPU同理。
2.2.2. 数据处理
配置好运行信息后,首先讨论数据处理API的设计。这些API提供了大量Python函数支持用户用一行命令即可读入常见的训练数据集(如MNIST,CIFAR,COCO等)。 在加载之前需要将下载的数据集存放在./datasets/MNIST_Data路径中;MindSpore提供了用于数据处理的API模块 mindspore.dataset,用于存储样本和标签。在加载数据集前,通常会对数据集进行一些处理,mindspore.dataset也集成了常见的数据处理方法。 以下代码读取了MNIST的数据是大小为(28 \times 28)的图片,返回DataSet对象。
import mindspore.dataset as ds
DATA_DIR = './datasets/MNIST_Data/train'
mnist_dataset = ds.MnistDataset(DATA_DIR)
- 1
- 2
- 3
有了DataSet对象后,通常需要对数据进行增强,常用的数据增强包括翻转、旋转、剪裁、缩放等;在MindSpore中是使用map将数据增强的操作映射到数据集中的,之后进行打乱(Shuffle)和批处理(Batch)。
# 导入需要用到的模块
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C
import mindspore.dataset.vision.c_transforms as CV
from mindspore.dataset.vision import Inter
from mindspore import dtype as mstype
# 数据处理过程
def create_dataset(data_path, batch_size=32, repeat_size=1,
num_parallel_workers=1):
# 定义数据集
mnist_ds = ds.MnistDataset(data_path)
resize_height, resize_width = 32, 32
rescale = 1.0 / 255.0
rescale_nml = 1 / 0.3081
shift_nml = -1 * 0.1307 / 0.3081
# 定义所需要操作的map映射
resize_op = CV.Resize((resize_height, resize_width), interpolation=Inter.LINEAR)
rescale_nml_op = CV.Rescale(rescale_nml * rescale, shift_nml)
hwc2chw_op = CV.HWC2CHW()
type_cast_op = C.TypeCast(mstype.int32)
# 使用map映射函数,将数据操作应用到数据集
mnist_ds = mnist_ds.map(operations=type_cast_op, input_columns="label", num_parallel_workers=num_parallel_workers)
mnist_ds = mnist_ds.map(operations=[resize_op, rescale_nml_op,hwc2chw_op], input_columns="image",num_parallel_workers=num_parallel_workers)
# 进行shuffle、batch操作
buffer_size = 10000
mnist_ds = mnist_ds.shuffle(buffer_size=buffer_size)
mnist_ds = mnist_ds.batch(batch_size, drop_remainder=True)
return mnist_ds
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
2.2.3. 模型定义
使用MindSpore定义神经网络需要继承mindspore.nn.Cell,神经网络的各层需要预先在__init__方法中定义,然后重载__construct__方法实现神经网络的前向传播过程。 因为输入大小被处理成(32 \times 32)的图片,所以需要用Flatten将数据压平为一维向量后给全连接层。 全连接层的输入大小为(32 \times 32),输出是预测属于(0 \sim 9)中的哪个数字,因此输出大小为10,下面定义了一个三层的全连接层。
# 导入需要用到的模块
import mindspore.nn as nn
# 定义线性模型
class MLPNet(nn.Cell):
def __init__(self):
super(MLPNet, self).__init__()
self.flatten = nn.Flatten()
self.dense1 = nn.Dense(32*32, 128)
self.dense2 = nn.Dense(128, 64)
self.dense3 = nn.Dense(64, 10)
def construct(self, inputs):
x = self.flatten(inputs)
x = self.dense1(x)
x = self.dense2(x)
logits = self.dense3(x)
return logits
# 实例化网络
net = MLPNet()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
2.2.4. 损失函数和优化器
有了神经网络组件构建的模型我们还需要定义损失函数来计算训练过程中输出和真实值的误差。均方误差(Mean Squared Error,MSE)是线性回归中常用的,是计算估算值与真实值差值的平方和的平均数。 平均绝对误差(Mean Absolute Error,MAE)是计算估算值与真实值差值的绝对值求和再求平均。 交叉熵(Cross Entropy,CE)是分类问题中常用的,衡量已知数据分布情况下,计算输出分布和已知分布的差值。
有了损失函数,我们就可以通过损失值利用优化器对参数进行训练更新。对于优化的目标函数(f(x));先求解其梯度(\nabla)(f(x)),然后将训练参数(W)沿着梯度的负方向更新,更新公式为:(W_t = W_{t-1} - \alpha\nabla(W_{t-1})),其中(\alpha)是学习率,(W)是训练参数,(\alpha\nabla(W_{t-1}))是方向。 神经网络的优化器种类很多,一类是学习率不受梯度影响的随机梯度下降(Stochastic Gradient Descent)及SGD的一些改进方法,如带有Momentum的SGD;另一类是自适应学习率如AdaGrad、RMSProp、Adam等。
SGD的更新是对每个样本进行梯度下降,因此计算速度很快,但是单样本更新频繁,会造成震荡;为了解决震荡问题,提出了带有Momentum的SGD,该方法的参数更新不仅仅由梯度决定,也和累计的梯度下降方向有关,使得增加更新梯度下降方向不变的维度,减少更新梯度下降方向改变的维度,从而速度更快也减少震荡。
自适应学习率AdaGrad是通过以往的梯度自适应更新学习率,不同的参数(W_i)具有不同的学习率。AdaGrad对频繁变化的参数以更小的步长更新,而稀疏的参数以更大的步长更新。因此对稀疏的数据表现比较好。Adadelta是对AdaGrad的改进,解决了AdaGrad优化过程中学习率(\alpha)单调减少问题;Adadelta不对过去的梯度平方进行累加,用指数平均的方法计算二阶动量,避免了二阶动量持续累积,导致训练提前结束。Adam可以理解为Adadelta和Momentum的结合,对一阶二阶动量均采用指数平均的方法计算。
MindSpore提供了丰富的API来让用户导入损失函数和优化器。在下面的例子中,计算了输入和真实值之间的softmax交叉熵损失,导入Momentum优化器。
# 定义损失函数
net_loss = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
# 定义优化器
net_opt = nn.Momentum(net.trainable_params(), learning_rate=0.01, momentum=0.9)
- 1
- 2
- 3
- 4
2.2.5. 训练及保存模型
MindSpore提供了回调Callback机制,可以在训练过程中执行自定义逻辑,使用框架提供的ModelCheckpoint为例。ModelCheckpoint可以保存网络模型和参数,以便进行后续的Fine-tuning(微调)操作。
# 导入模型保存模块
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig
# 设置模型保存参数
config_ck = CheckpointConfig(save_checkpoint_steps=1875, keep_checkpoint_max=10)
# 应用模型保存参数
ckpoint = ModelCheckpoint(prefix="checkpoint_lenet", config=config_ck)
- 1
- 2
- 3
- 4
- 5
- 6
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gonuipEa-1653891679616)(https://raw.githubusercontent.com/choldgraf/sphinx-copybutton/master/sphinx_copybutton/_static/copy-button.svg)]
通过MindSpore提供的model.train接口可以方便地进行网络的训练,LossMonitor可以监控训练过程中loss值的变化。
# 导入模型训练需要的库
from mindspore.nn import Accuracy
from mindspore.train.callback import LossMonitor
from mindspore import Model
def train_net(args, model, epoch_size, data_path, repeat_size, ckpoint_cb, sink_mode):
"""定义训练的方法"""
# 加载训练数据集
ds_train = create_dataset(os.path.join(data_path, "train"), 32, repeat_size)
model.train(epoch_size, ds_train, callbacks=[ckpoint_cb, LossMonitor(125)], dataset_sink_mode=sink_mode)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ECzaT179-1653891679616)(https://raw.githubusercontent.com/choldgraf/sphinx-copybutton/master/sphinx_copybutton/_static/copy-button.svg)]
其中,dataset_sink_mode用于控制数据是否下沉,数据下沉是指数据通过通道直接传送到Device上,可以加快训练速度,dataset_sink_mode为True表示数据下沉,否则为非下沉。
有了数据集、模型、损失函数、优化器后就可以进行训练了,这里把train_epoch设置为1,对数据集进行1个迭代的训练。在train_net和 test_net方法中,我们加载了之前下载的训练数据集,mnist_path是MNIST数据集路径。
train_epoch = 1
mnist_path = "./datasets/MNIST_Data"
dataset_size = 1
model = Model(net, net_loss, net_opt, metrics={"Accuracy": Accuracy()})
train_net(args, model, train_epoch, mnist_path, dataset_size, ckpoint, False)
- 1
- 2
- 3
- 4
- 5
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SwJ77Jog-1653891679617)(https://raw.githubusercontent.com/choldgraf/sphinx-copybutton/master/sphinx_copybutton/_static/copy-button.svg)]
2.2.6. 测试和验证
测试是模型运行测试数据集得到的结果,通常在训练过程中,每训练一定的数据量后就会测试一次,以验证模型的泛化能力。MindSpore使用model.eval接口读入测试数据集。
def test_net(model, data_path):
"""定义验证的方法"""
ds_eval = create_dataset(os.path.join(data_path, "test"))
acc = model.eval(ds_eval, dataset_sink_mode=False)
print("{}".format(acc))
# 验证模型精度
test_net(model, mnist_path)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在训练完毕后,参数保存在checkpoint中,可以将训练好的参数加载到模型中进行验证。
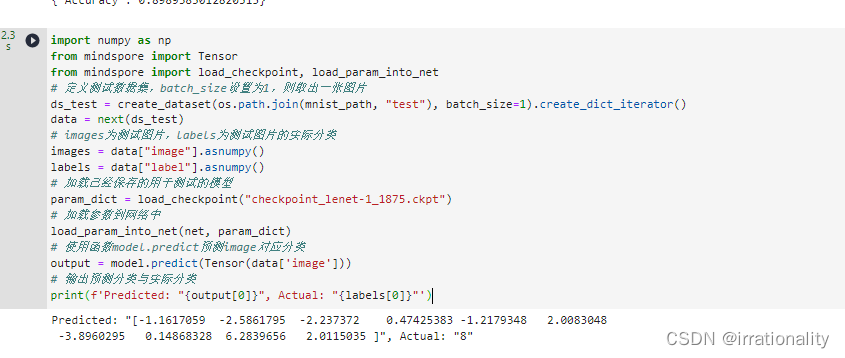
import numpy as np
from mindspore import Tensor
from mindspore import load_checkpoint, load_param_into_net
# 定义测试数据集,batch_size设置为1,则取出一张图片
ds_test = create_dataset(os.path.join(mnist_path, "test"), batch_size=1).create_dict_iterator()
data = next(ds_test)
# images为测试图片,labels为测试图片的实际分类
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
# 加载已经保存的用于测试的模型
param_dict = load_checkpoint("checkpoint_lenet-1_1875.ckpt")
# 加载参数到网络中
load_param_into_net(net, param_dict)
# 使用函数model.predict预测image对应分类
output = model.predict(Tensor(data['image']))
# 输出预测分类与实际分类
print(f'Predicted: "{predicted[0]}", Actual: "{labels[0]}"')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
但是这个时候predicted这个似乎已经在mindspore不这样使用了,因此我们看
print(f'Predicted: "{output[0]}", Actual: "{labels[0]}"')
- 1
output中值最大的那一个就是推理出的结果
文章来源: blog.csdn.net,作者:irrationality,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/weixin_54227557/article/details/125045819

- 点赞
- 收藏
- 关注作者
评论(0)