C++中的深拷贝和浅拷贝的案例对比理解

【摘要】
用两个案例对比来理解为什么要深拷贝和浅拷贝
案例一
#include<iostream>
using namespace std;
/*
简单说浅拷贝就是赋值操作:
深拷贝就是在堆区间...
用两个案例对比来理解为什么要深拷贝和浅拷贝
案例一
#include<iostream>
using namespace std;
/*
简单说浅拷贝就是赋值操作:
深拷贝就是在堆区间又申请了一个空间,进行拷贝操作
*/
class Per {
public:
int* name;
public:
Per(int n) {
name = new int(n);//这里必须建立堆区数据原因可以看我的上一篇文章
}
~Per(){};
};
void test() {
Per p1 =Per (3);
cout << "name:" << *p1.name << endl;
Per p2 = (p1);//编译器调用自己创建的拷贝函数此时对堆区的数据为浅拷贝
cout << "name:" << *p2.name << endl;
}
int main() {
test();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
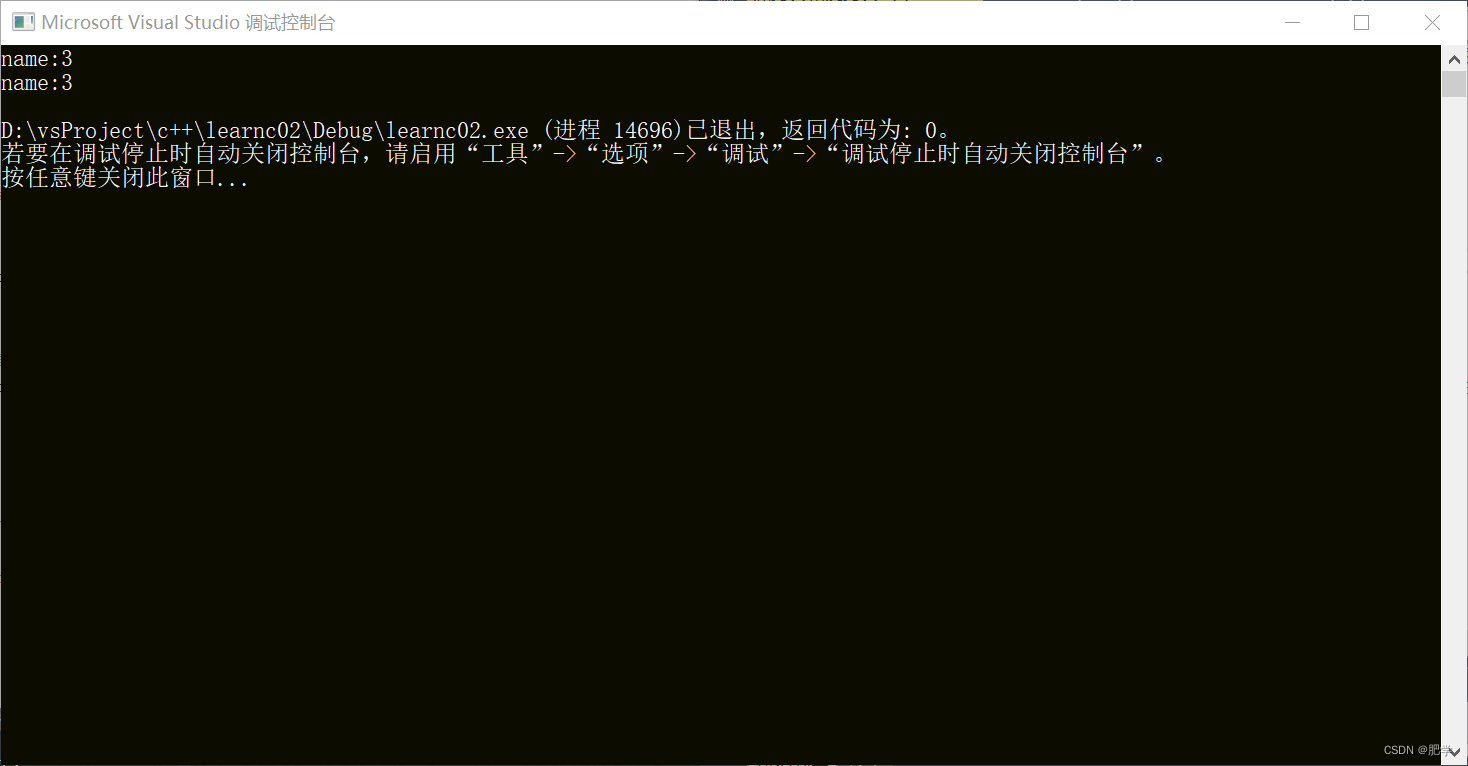
此时可以正常打印。
案例二
对案例一的析构函数修改
#include<iostream>
using namespace std;
/*
简单说浅拷贝就是赋值操作:
深拷贝就是在堆区间又申请了一个空间,进行拷贝操作
*/
class Per {
public:
int* name;
public:
Per(int n) {
name = new int(n);//这里必须建立堆区数据原因可以看我的上一篇文章
}
~Per(){
if (name != NULL) {
delete name;
name = NULL;
}
};
};
void test() {
Per p1 =Per (3);
cout << "name:" << *p1.name << endl;
Per p2 = (p1);//编译器调用自己创建的拷贝函数此时对堆区的数据为浅拷贝
cout << "name:" << *p2.name << endl;
}
int main() {
test();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
此时引发异常
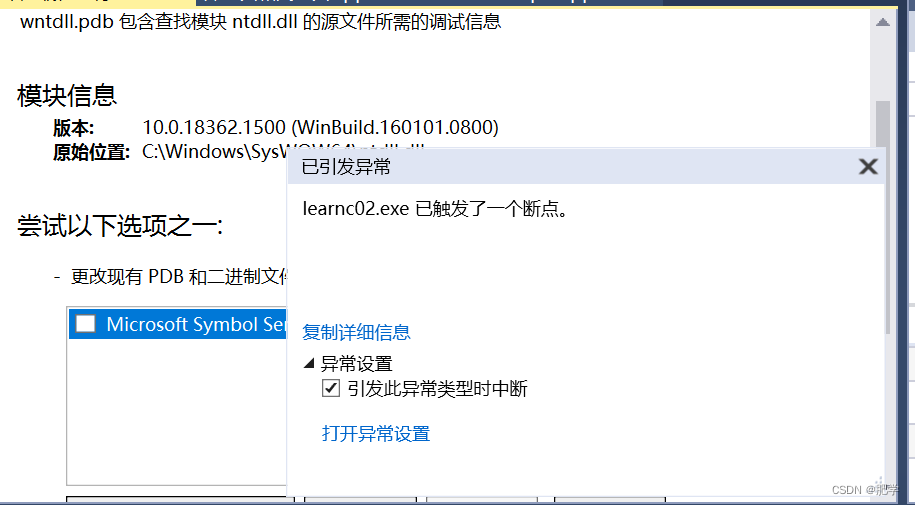
原因:当test()函数结束时,p1会自动调用析构函数此时以经释放掉name内存了。因为是浅拷贝p2的name也指向和p1相同的内存地址,所以当p2调用析构函数的时候再去释放name就会出现错误。
解决方法:可以重写拷贝构造函数,将浅拷贝name2=name1改写成带关键字new的堆区数据。
文章来源: blog.csdn.net,作者:肥学,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/jiahuiandxuehui/article/details/124488117

【版权声明】本文为华为云社区用户转载文章,如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)