如何快速开发大数据系统

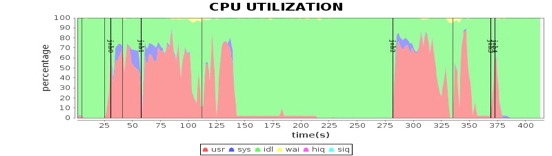
这可视化性能数据从何来?如何在图中将性能指标和任务进度结合起来,可以一目了然看清应用在不同运行阶段的资源使用状况呢?为了Spark性能优化,专门大数据性能测试工具Dew。
Dew也是个分布式大数据系统,部署在整个Hadoop大数据集群的所有服务器上。可实时采集服务器上的性能数据和作业日志,收集起来以后解析这些日志数据,将作业运行时间和采集性能指标的时间在同一个坐标系绘制出来,就得到上面的可视化性能图表。
部署模型
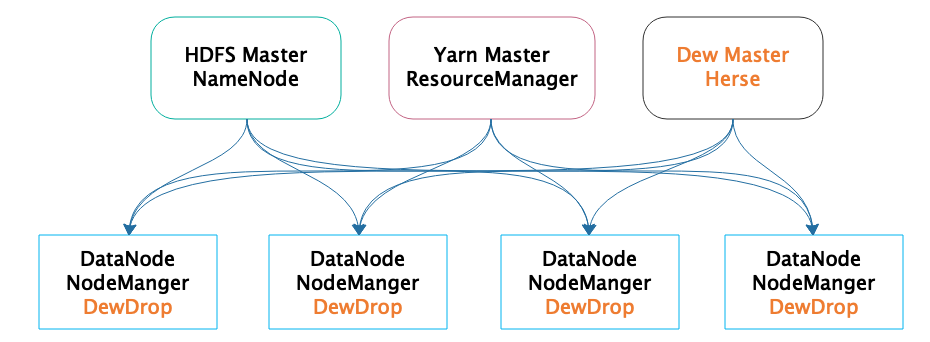
Dew核心进程:
-
Dew Master进程Herse
Herse独立部署一台服务器,而DewDrop则和HDFS的DataNode、Yarn的NodeManager部署在大数据集群的其他所有服务器上,即每台服务器都同时运行DataNode、NodeManager、DewDrop进程
-
管理集群中每台服务器的Dew Agent进程DewDrop
Dew Agent监控整个Hadoop集群的每台服务器
Dew Master服务器上配置好Agent服务器的IP,运行下面的命令就可以启动整个Dew集群。
sbin/start-all.sh
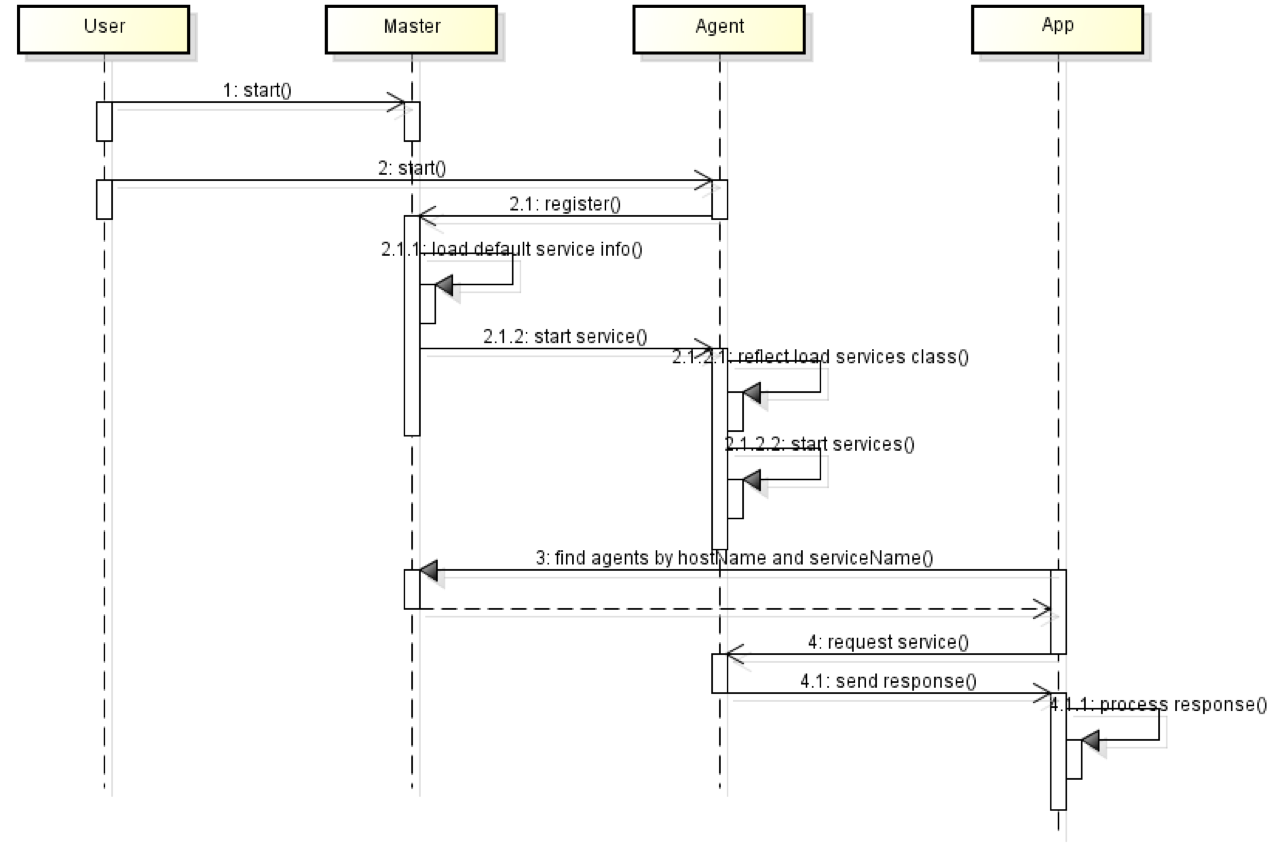
Master进程Herse和每一台服务器上的Agent进程DewDrop都会启动起来,DewDrop进程会向Herse进程注册,获取自身需要执行的任务,根据任务指令,加载任务可执行代码,启动Drop进程内的service,或者独立进程service,即各种App。整个启动和注册时序请看下面这张图。
Dew架构也是主从结构的大数据系统,也有一套底层通信体系和消息传输机制。可以快速开发分布式底层通信体系和消息传输机制的编程框架。很快将目标锁定在Akka,同时支持并发编程、异步编程、分布式编程的编程框架,提供Java和Scala两种编程语言接口,简单易用。
用Akka搭建Dew的底层通信和消息传输机制,核心代码不到100行,半天时间开发完成。一个Master-Slave架构的大数据系统的基本框架就搭建了,后面加入分布式集群性能数据采集、日志收集,很快就输出那些Spark性能图表。
Akka原理与应用
使用Actor编程模型,和OOP平行的一种编程模型。OOP认为一切都是对象,对象之间通过消息传递,也就是方法调用实现复杂的功能。
而Actor编程模型认为一切都是Actor,Actor之间也是通过消息传递实现复杂的功能,但这里的消息是真正意义上的消息。
- 不同于OOP时,方法调用是同步阻塞,即被调用者在处理完成之前,调用者必须阻塞等待
- 给Actor发送消息不需要等待Actor处理,消息发送完就不用管了,即消息异步
OOP能很好对问题领域进行建模,但随摩尔定律失效,计算机发展朝着多核CPU与分布式,而面向对象的同步阻塞调用及由此带来的并发与线程安全问题,使得其在新的编程时代相形见绌。而Actor编程模型很好地利用了多核CPU与分布式的特性,可以轻松实现并发、异步、分布式编程,受到人们越来越多的青睐。
Actor例子
class MyActor extends Actor {
val log = Logging(context.system, this)
def receive = {
case "test" ⇒ log.info("received test")
case _ ⇒ log.info("received unknown message")
}
}
一个Actor类最重要的就是实现receive方法,在receive里面根据Actor收到的消息类型进行对应的处理。而Actor之间互相发送消息,就可以协作完成复杂的计算操作。
Actor之间互相发送消息全部都是异步的,也就是说,一个Actor给另一个Actor发送消息,并不需要等待另一个Actor返回结果,发送完了就结束了,自己继续处理别的事情。另一个Actor收到发送者的消息后进行计算,如果想把计算结果返回给发送者,只需要给发送者再发送一个消息就可以了,而这个消息依然是异步的。
这种全部消息都是异步,通过异步消息完成业务处理的编程方式也叫响应式编程,Akka的Actor编程就是响应式编程的一种。目前已经有公司在尝试用响应式编程代替传统的面向对象编程,去开发企业应用和网站系统,如果这种尝试成功了,可能会对整个编程行业产生巨大的影响。
Akka异步消息原理
Actor之间消息传输通过一个收件箱Mailbox完成,发送者Actor的消息发到接收者Actor的收件箱,接收者Actor一个接一个地串行从收件箱取消息调用自己的receive方法进行处理:
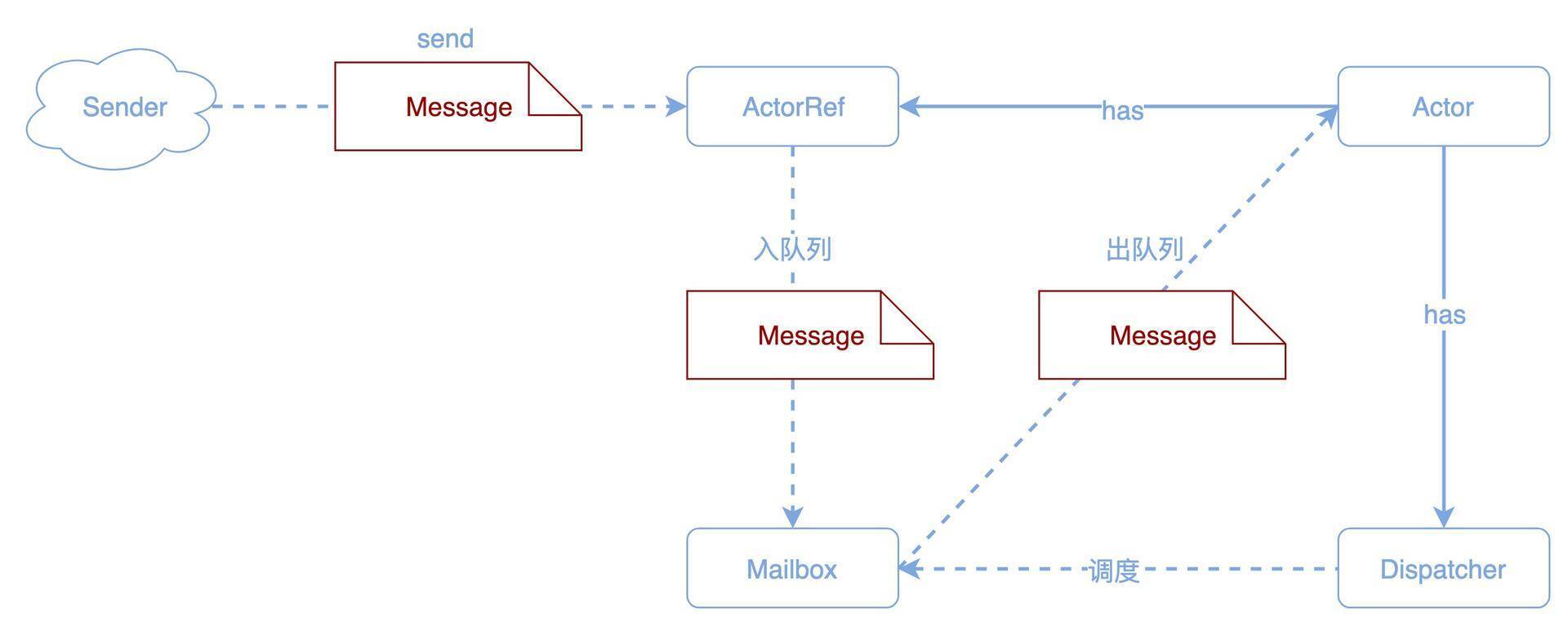
发送者通过调用一个Actor的引用ActorRef来发送消息,ActorRef将消息放到Actor的Mailbox里就返回了,发送者不需要阻塞等待消息被处理,这是和传统的面向对象编程最大的不同,对象一定要等到被调用者返回结果才继续向下执行。
通过这种异步消息方式,Akka也顺便实现了并发编程:消息同时异步发送给多个Actor,这些Actor看起来就是在同时执行,即并发执行。
Dew使用Akka,主要用其分布式特性。Akka创建Actor需要用ActorSystem创建。
val system = ActorSystem("pingpong")
val pinger = system.actorOf(Props[Pinger], "pinger")
当Actor的Props配置为远程的方式,就可以监听网络端口,从而进行远程消息传输。比如下面的Props配置sampleActor监听2553端口。
akka {
actor {
deployment {
/sampleActor {
remote = "akka.tcp://sampleActorSystem@127.0.0.1:2553"
}
}
}
}
所以使用Akka编程,写简单Actor,实现receive方法,配置个远程Props,然后用main函数调用ActorSystem启动,就得到可远程通信的JVM进程。使用Akka,Dew只用100多行代码,就实现Master-Slave架构分布式集群。
小结
如用Akka Actor编程模型,无需考虑微服务架构的各种通信、序列化、封装,只需要将想要分布式部署的Actor配置为远程模,不需改动一行代码。
Actor的交互方式看起来是不是更像人类的交互方式?拜托对方一件事情,说完需求就结束了,不需要傻傻的等在那里,该干嘛干嘛。等对方把事情做完了,再过来跟你说事情的结果,你可以根据结果决定下一步再做什么。
理想的Actor程序也是同样,采用金字塔的结构,顶层Actor负责总体任务,将任务分阶段、分类以后交给下一级多个Actor,下一级Actor拆分成具体的任务交给再下一级更多的Actor,众多的底层Actor完成具体的细节任务。
这种处理方式非常符合大数据计算,大数据计算通常都分成多个阶段,每个阶段又处理一个数据集的多个分片,这样用Actor模型正好可以对应上。所以我们看到有的大数据处理系统直接用Akka实现,它们程序简单,运行也很良好,比如大数据流处理系统Gearpump。

- 点赞
- 收藏
- 关注作者
评论(0)