神经网络与深度学习笔记(五)偏差与方差

前言
这篇文章的内容主要是偏差与方差的相关解释
什么是高偏差,高方差
在训练神经网络时,我们需要使用偏差与方差评估模型的准确度。
但是,到底什么是高偏差?什么是高方差?
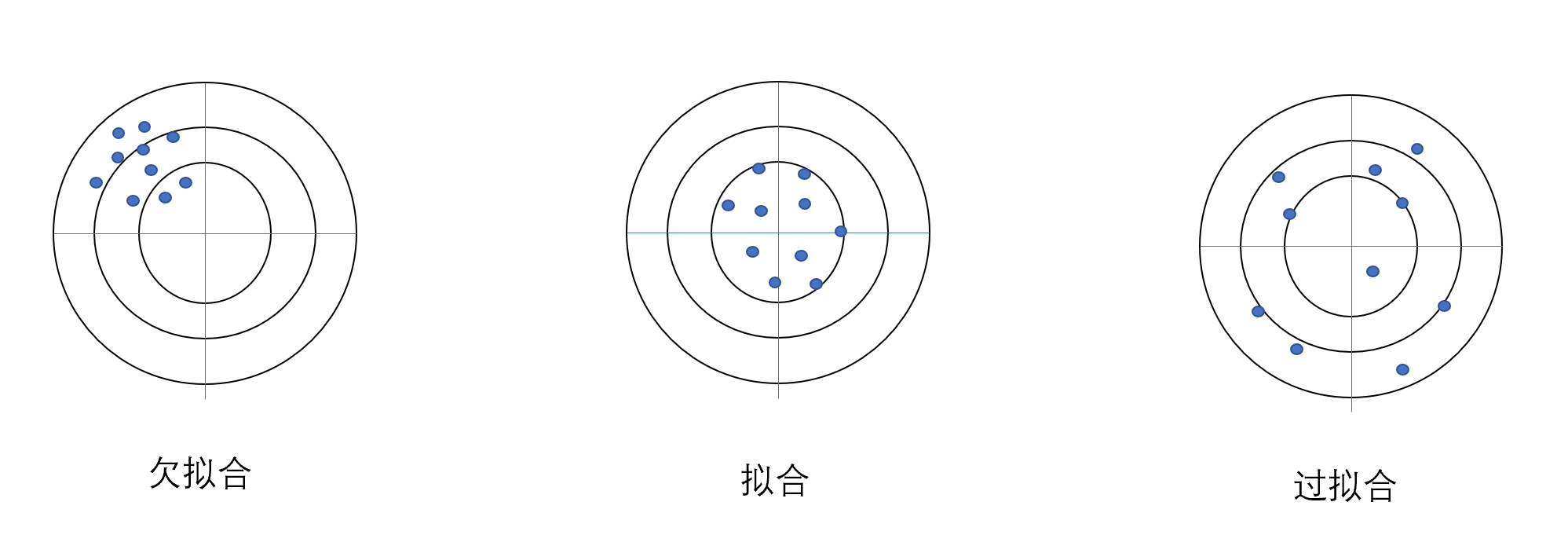
我们举个靶心的例子。
如果数据点集中于非靶心的地方,就是欠拟合。在这种情况下,模型属于高偏差
如果数据点集中于靶心。拟合程度就刚刚好。
如果数据集集中于靶心,但是扩散范围广,零零散散。在这种情况下,模型属于高方差。
下面的例子是在二元分类时,高偏差与高方差的情况:
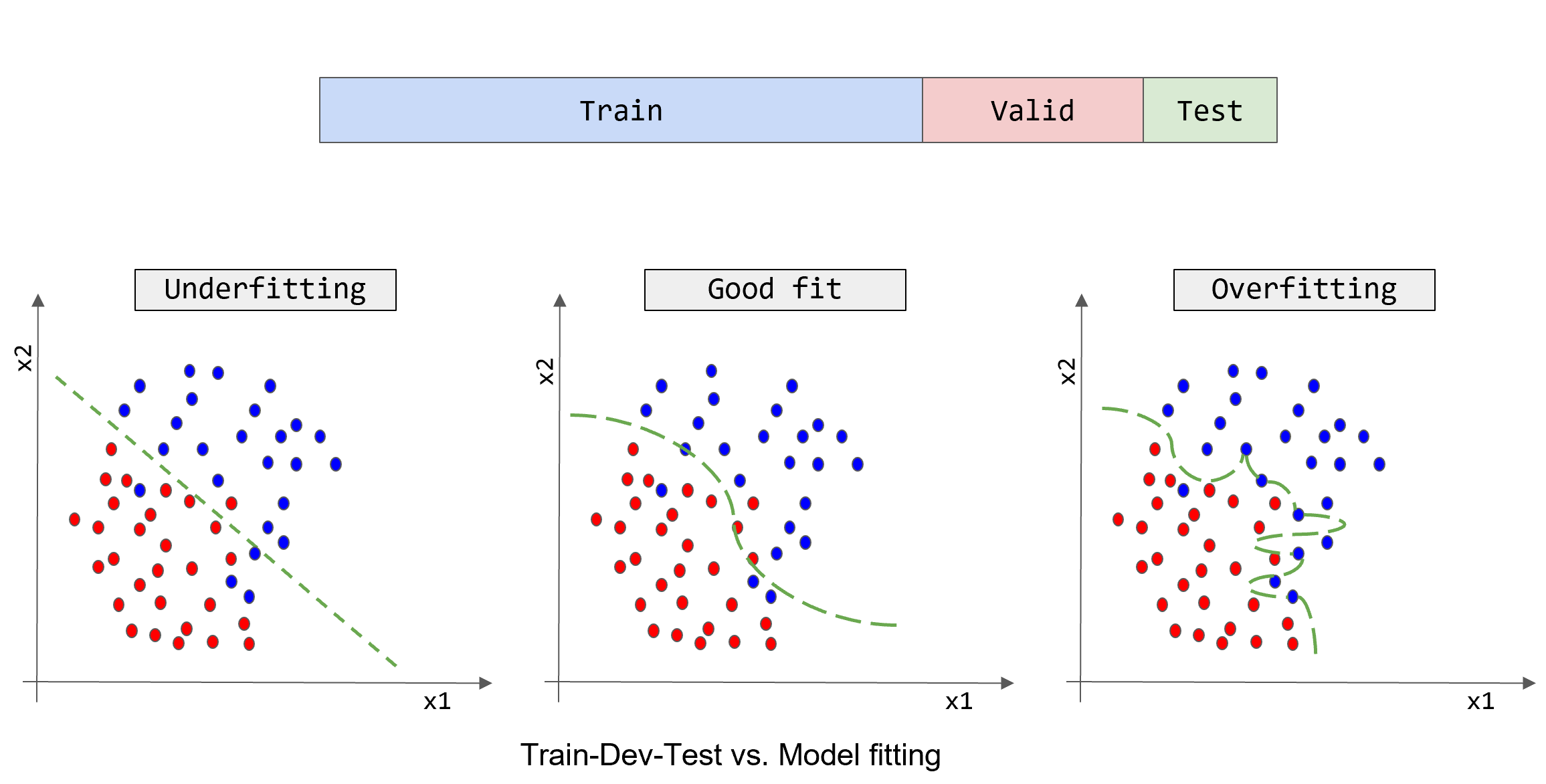
可以看到,上图最左边的图,粗暴将数据划了一条线作为边界。但是仍然有很多数据分类错误,这是欠拟合的情况
中间一幅图,拟合程度刚刚好。
最右的一幅图,拟合程度太高,出现了过拟合。
这种直观的图很容易分辨出拟合好坏的情况。
但是很多情况下,我们并不能可视化数据。在这种情况下我们就要看训练集误差和开发集的误差
利用数据集误差判断拟合情况
在假定人眼分辨猫狗理想误差(贝叶斯误差)为 0% 的情况下:
| train set error训练集误差 | dev set error开发集误差 | 拟合情况 |
|---|---|---|
| 1% | 11% | 过拟合,高方差(训练集效果好,但是在开发集不尽人意) |
| 15% | 16% | 欠拟合,高偏差(训练集效果不尽人意) |
| 15% | 30% | 高偏差,高方差(训练集和开发集都不尽人意) |
| 0.5% | 1% | 拟合程度较好(训练集与开发集的效果较好) |
由上可以看出,我们首先判断是否是高偏差,高偏差主要看训练集误差的大小,如果训练集误差较大,那么这个模型的偏差较高,在这种情况下,训练数据得出的结果与实际值偏差较大,就不用再考虑方差情况。
在确定偏差不高的情况下,我们再判断是否是高方差。当训练集的数据较好,但是开发集误差与训练集误差相距离谱时,这种现象就是高方差。也就是过拟合。
当训练集误差和开发集误差均较小且相近时,模型的拟合程度就达到了较好。
处理方式
训练好最初的神经网络后,我们可以参照以下的流程去关注模型的性能
看模型在训练集上的表现
即看模型是否会出现高偏差
如果有高偏差,则:
- 挑选更优的算法
- 使用更大的神经网络,设计带有更多隐藏层或者更多隐藏单元的神经网络
- 训练更长的时间,让梯度下降运行更长的时间
- 换用一些更高级的优化算法
- 选择更合适的神经网络
看模型在开发集上的表现
解决上面模型在训练集上的表现情况后,我们再看模型在开发及上的表现
在训练集上表现好,是否在开发集上是一样好呢?
如果有高方差,则:
- 增加更多训练数据去训练模型
- 使用正则化
- 选用更合适的神经网络
后记
在过去的机器学习阶段,偏差和方差是需要权衡的。因为当你减小偏差时候,方差可能会增大;而减小方差时候,偏差可能会增大。很难找到既能减小偏差又能减小方差的方法。
然而在如今的深度学习时代,使用更多的数据集,更好更大的神经网络,适当的正则化可以在减小方差时候不增加偏差,或者在减少偏差的时候不增加方差。
后面即将更新正则化。
文章来源: blog.csdn.net,作者:沧夜2021,版权归原作者所有,如需转载,请联系作者。
原文链接:blog.csdn.net/CANGYE0504/article/details/118446003

- 点赞
- 收藏
- 关注作者
评论(0)