ROS 2 感知节点的硬件加速

news.accelerationrobotics.com/hardware-accelerating-ros-2-nodes
机器翻译
6 分钟阅读
移动得更快的机器人需要在边缘进行更快的感知计算。本文讨论了硬件加速如何使机器人速度更快,以及选择正确的加速器有多重要。基准测试结果表明 ROS 节点的加速解决方案之间的加速差异超过 500 倍。
移动得更快(或更灵巧)需要在边缘进行更快的感知计算。下面的 Atlas 使用感知来识别、导航和绕过障碍物。边缘感知是在变化的环境下导航的关键,人类世界中最多的. Atlas 利用飞行时间深度相机以 15 Hz 的频率生成环境点云。点云是一个大而密集的距离测量集合,需要在边缘(直接在机器人中)进行处理以实现平滑的行为,从而减少从传感器到执行器的任何延迟。通过利用硬件加速,Atlas 的感知从该点云中提取表面,然后用于以十分之一毫秒的数量级计划动作。这一切都归功于硬件加速.


波士顿动力公司的地图集展示了机器人的感知
机器人从摄像头和激光雷达等传感器获得的数据通常被输入感知层,转化为对决策和规划物理动作有用的东西。感知有助于感知静态和动态对象,并使用计算机视觉和机器学习技术构建机器人环境的可靠且详细的表示。因此,机器人中的感知层负责对象检测、分割和跟踪。传统上,感知管道从图像预处理开始,然后是感兴趣区域检测器,然后是输出检测到的对象的分类器。ROS 2 提供了各种预构建的节点(Components更具体地说),可用于轻松构建感知管道。
之前的一篇文章介绍了硬件加速如何帮助加速 ROS 2 计算图(包括感知图)。但是退后一步Graphs看看Nodes有助于解决以下问题:
对于我们的每一个 ROS 2 节点,哪个加速器(GPU、FPGA 等)是最好的?
这需要额外的理解和基准测试。
了解机器人的不同加速器
机器人是一个系统系统,包括感知环境的传感器、作用于环境的执行器和处理所有环境的计算,同时连贯地及时响应其应用。大多数机器人在满足时间期限的同时通过其内部网络交换信息。确定性和延迟在机器人技术中都至关重要,因为在某种程度上,机器人是时间敏感网络的网络。
机器人的板载资源有限,而那些仅使用 CPU 设计的机器人由于固定的内存和计算能力而难以扩展。为了满足这些时间期限,机器人可以利用硬件加速并创建自定义计算架构。硬件加速背后的核心思想是将机器人技术中使用的传统控制驱动方法(通过 CPU)与数据驱动的方法相结合,以优化硬件资源的数量,从而提高性能。
机器人中最流行的加速器是 FPGA 和 GPU:
FPGAs:FPGAs 是软件和硬件可编程的,并提供完全的灵活性和能力来构建混合不同硬处理器和软处理器的混合控制和数据驱动的计算模型。ROS 2 节点可以指示 FPGA 为正在执行的特定任务“构建硬件”,利用并行性和构建自定义内存结构来支持数据流。FPGA 的缺点是复杂性。使用 FPGA 创建硬件的架构师需要将不同的任务预先分配到不同的计算单元中,以充分利用性能。简而言之,预先构建的对 FPGA 友好的 ROS 2 节点仍然很少见,而且很难构建。
GPU:与 CPU 一样,GPU 也具有固定的硬件架构(它们不是硬件可重新编程的),但具有许多(许多)更多的内核。一条指令可以处理一千条或更多条数据,但通常必须对同时处理的每个数据点执行相同的操作。原子处理元素对数据向量进行操作(与 CPU 中的数据点相反),但每个 ALU 仍执行一条固定指令。因此,数据还必须通过固定的数据路径从内存中带到这些处理单元。这严重影响了 ROS 节点,并且仍然是一个有待解决的悬而未决的问题。
您可以在[1]中阅读有关机器人技术中使用的不同计算基板的更多信息。
关于感知模块在 ROS 2 节点中对硬件加速进行基准测试
为了比较 ROS 2Nodes在 FPGA 和 GPU 加速器上的感知任务,我们选择 AMD 的 Kria KV260 FPGA 板和 NVIDIA 的 Jetson Nano 与板载 GPU。两者都提供了一些相似的 CPU(KV260 具有四核 A53,而 Jetson Nano 具有四核 A57)并且从以 CPU 为中心的角度来看具有相似的 ROS 行为。对于基准测试,我们遵循REP-2008 PR 中描述的基准测试方法。特别是,为了创建加速内核,我们利用了AMD 的 Vitis 视觉库和 NVIDIA 的视觉编程接口。例如,为了Node使用Harris Corner Detector算法比较 ROS 2 感知,我们利用[2]和[3]分别用于FPGA和GPU比较。此外,我们还会在适当的时候分别利用 AMD 的 HLS 和 NVIDIA 的 CUDA。
为了区分 KV260 中的 A53 内核和 Jetson Nano 中的 A57 内核之间的任何可能差异,测量以毫秒 (ms) 为单位捕获加速内核运行时间,并丢弃 ROS 2 消息传递基础设施开销和主机设备(GPU或 FPGA)到 CPU 的数据传输开销。
跨感知 ROS 2 节点获得的结果表明FPGA 在机器人感知方面的性能优于 GPU,速度差异达 500 倍在流行的算法中,例如定向梯度直方图 (HOG):
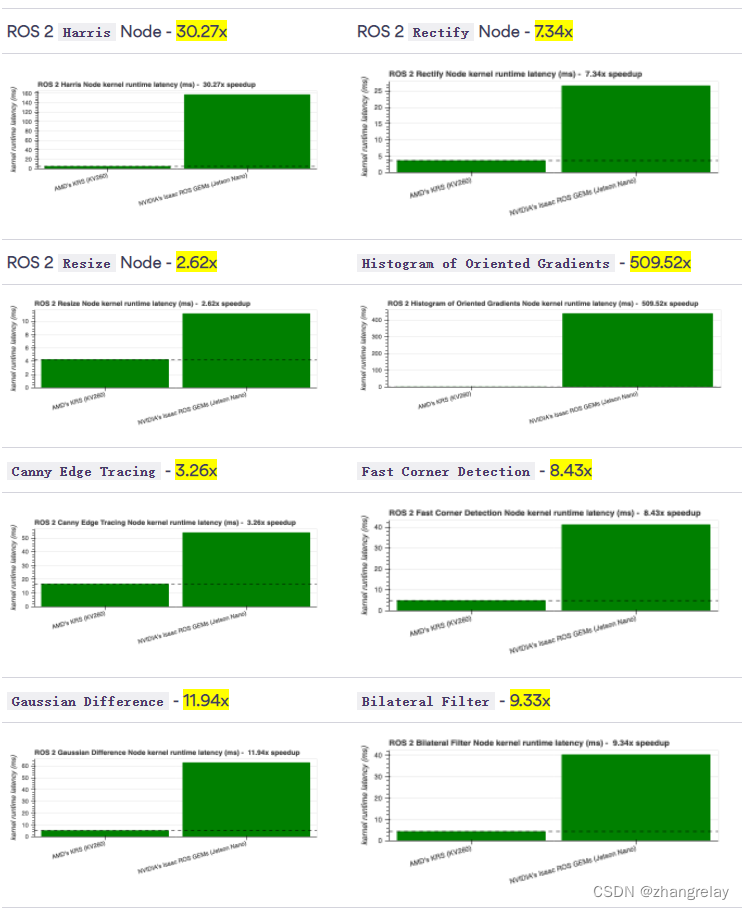
在测量功耗的同时,我们还观察到FPGA 设计更节能,每瓦性能比 GPU 设计平均高 5 倍. 在研究机器人,尤其是移动机器人时,每瓦性能是一个值得考虑的有趣数字。
进一步改进 ROS 2 中的硬件加速
就感知而言,FPGA 的性能似乎明显优于其加速同类产品,但是,与可重新编程的硬件一样,这是以硬件-软件协同设计Nodes的复杂性为代价的。为机器人专家简化开发流程需要创建通用架构和约定,这就是我们为 REP-2008 - ROS 2 硬件加速架构和约定做出贡献的原因。
进一步改进 ROS 2 需要将计算技术以正确的方式组合在一起,并针对每项任务:CPU、GPU 和 FPGA。如果您对找到正确的组合感兴趣,请关注ROS 2 硬件加速工作组。
- Mayoral-Vilches, V., & Corradi, G. (2021). Adaptive computing in robotics, leveraging ros 2 to enable software-defined hardware for fpgas. arXiv preprint arXiv:2109.03276. https://docs.xilinx.com/v/u/en-US/wp537-adaptive-computing-robotics ↩︎
- AMD Vitis Vision Library. Harris Corner Detector. https://xilinx.github.io/Vitis_Libraries/vision/2021.2/api-reference.html?highlightharris-corner-detection#harris-corner-detection ↩︎
- NVIDIA VPI. Harris Corner. https://docs.nvidia.com/vpi/group__VPI__HarrisCorners.html ↩︎
分享这篇文章
文章来源: zhangrelay.blog.csdn.net,作者:zhangrelay,版权归原作者所有,如需转载,请联系作者。
原文链接:zhangrelay.blog.csdn.net/article/details/124461119

- 点赞
- 收藏
- 关注作者
评论(0)