大数据笔记(一):大数据启蒙与入门知识

【摘要】 大数据启蒙与入门知识一、前言博主语录:一文精讲一个知识点,多了你记不住,一句废话都没有经典语录:那日看雪,你从未看我,我从未看雪二、千里之行,始于足下启蒙很重要分治思想 单机处理大数据问题 集群分布式处理大数据的辩证三、分治思想需求: 我有一万个元素(比如数字或单词)需要存储?如果查找某一个元素,最简单的遍历方式复杂的是多少?如果我期望复杂度是O(4)呢?学习知识的时候要去搞明白它存在...

大数据启蒙与入门知识
一、前言
博主语录:一文精讲一个知识点,多了你记不住,一句废话都没有
经典语录:那日看雪,你从未看我,我从未看雪
二、千里之行,始于足下
- 启蒙很重要
- 分治思想
- 单机处理大数据问题
- 集群分布式处理大数据的辩证
三、分治思想
需求:
- 我有一万个元素(比如数字或单词)需要存储?
- 如果查找某一个元素,最简单的遍历方式复杂的是多少?
- 如果我期望复杂度是O(4)呢?

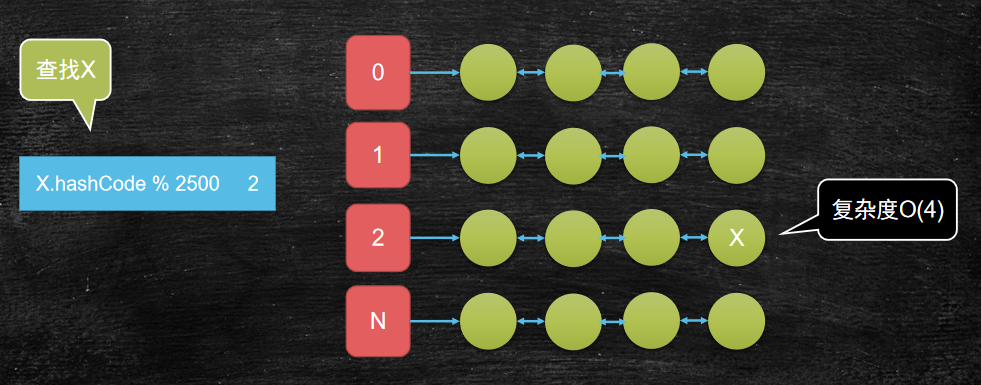
学习知识的时候要去搞明白它存在的意义,这样学习成本才会低
分而治之的思想很重要,出现在了很多地方:
- Redis集群
- ElasticSearch
- Hbase
- HADOOP生态无处不在!
四、单机处理大数据问题
需求:
- 有一个非常大的文本文件,里面有很多很多的行,只有两行一样,它们出现在未知的位置,需要查找到它们
- 单机,而且可用的内存很少,也就几十兆
解决思路:
- 假设Io速度是500MB每秒
- 1T文件读取一遍需要约30分钟
- 循环遍历需要N次Io时间
- 分治思想可以使时间为2次io
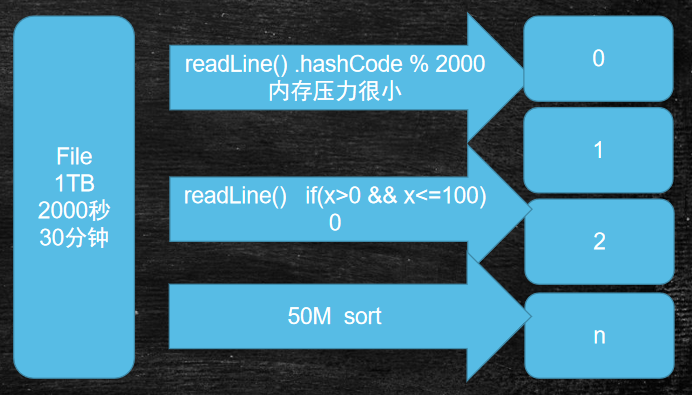
小贴士:内存寻址比Io寻址快10万倍
思考: 如果让时间变为分钟、秒级别
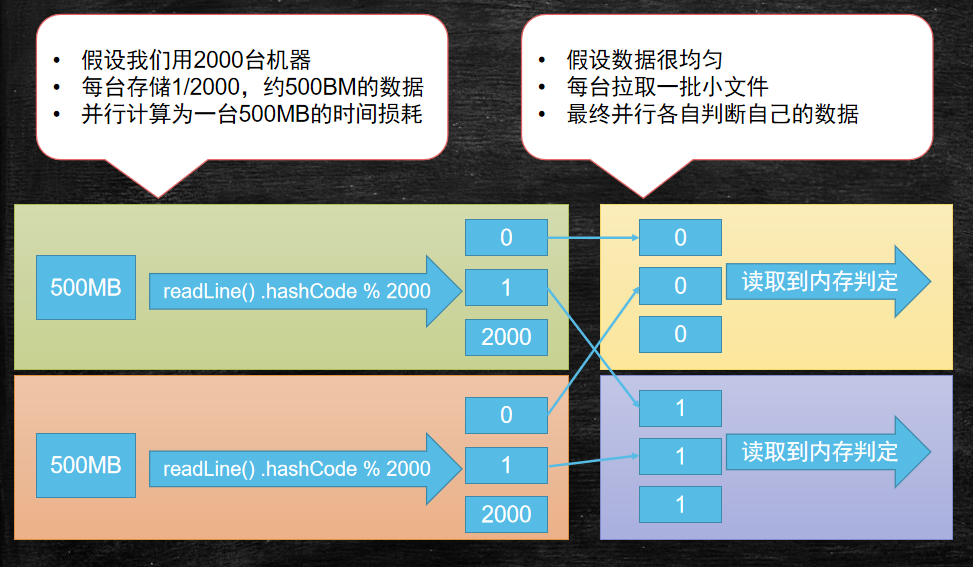
五、集群分布式处理大数据的辩证
- 2000台真的比一台速度快吗?
- 如果考虑分发上传文件的时间呢?
- 如果考虑每天都有1T数据的产生呢?
- 如果增量了一年,最后一天计算数据呢?
结论
- 分而治之 并行计算
- 计算向数据移动
- 数据本地化读取
- 以上这些点是学习大数据技术时需要关心的重点
六、Hadoop之父Doug Cutting
- Hadoop的发音是 [hædu:p]
- Cutting儿子对玩具小象的昵称
- Nutch Lucene
- Avro
- Hadoop

![]()
七、Hadoop的时间简史
- 《The Google File System 》 2003年
- 《MapReduce: Simplified Data Processing on Large Clusters》 2004年
- 《Bigtable: A Distributed Storage System for Structured Data》 2006年
- Hadoop由 Apache Software Foundation 于 2005 年秋天作为Lucene的子项目Nutch的一部分正式引入。
- 2006 年 3 月份,Map/Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
- Cloudera公司在2008年开始提供基于Hadoop的软件和服务。
- 2016年10月hadoop-2.6.5
- 2017年12月hadoop-3.0.0
- hadoop.apache.org
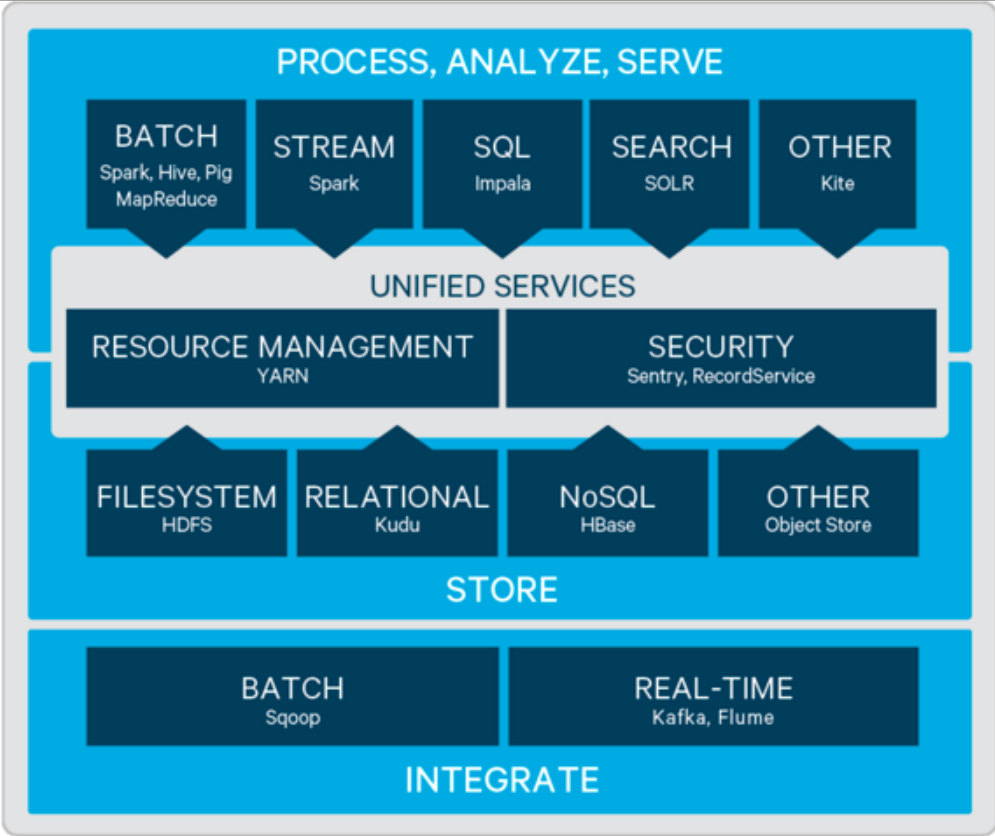
八、Hadoop项目/生态
The project includes these modules:
- Hadoop Common
- Hadoop Distributed File System (HDFS™)
- Hadoop YARN
- Hadoop MapReduce
Other Hadoop-related projects at Apache include:
- Ambari™
- Avro™
- Cassandra™
- Chukwa™
- HBase™
- Hive™
- Mahout™
- Pig™
- Spark™
- Tez™
- ZooKeeper™
九、大数据生态
www.cloudera.com![]() https://www.cloudera.com/Cloudera’s Distribution Including Apache Hadoop CDH is the most complete,tested, and popular distribution of Apache Hadoop and related projects.
https://www.cloudera.com/Cloudera’s Distribution Including Apache Hadoop CDH is the most complete,tested, and popular distribution of Apache Hadoop and related projects.

【声明】本内容来自华为云开发者社区博主,不代表华为云及华为云开发者社区的观点和立场。转载时必须标注文章的来源(华为云社区)、文章链接、文章作者等基本信息,否则作者和本社区有权追究责任。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)