虫子 单链表 内核必备,基本算法,linux二次发育,项目远见

【摘要】 顺序表的缺陷 链表 链表的概念及结构 链表的分类 1.单向或者双向 2.带头或者不带头 3.循环或者非循环 链表的实现 无头单向 单链表节点 单链表打印函数SListPrint 单链表尾插函数SListPushBack 获得单链表节点函数BuySListNode 单链表头插函数SListPushFront 单链表尾删函数SListPopBack 单链表头删函数SListPopFront 单...
顺序表的缺陷
1.空间不够了需要扩容,增容是要付出代价
realloc的机制代价,与身具来的代价,1.后面内存足够开辟就原地扩容,2.后面内存不够就会异地扩容
2.避免频繁扩容,我们满了基本都是扩2倍,可能就会导致一定的空间浪费
3.顺序表要求数据从开始位置连续存储那么我们在头部或者中间位置插入删除数据就需要挪动数据,效率不高
==针对顺序表的缺陷,就设计出了链表==
链表是按需申请空间,不用了就释放空间(更合理的使用空间)
头部中间尾部插入删除数据,不需要挪动数据
当然他也是有缺陷的,例如每个数据后面都要存一个指针去链接后面的数据节点
不支持随机访问(也就是没有下标访问了)
链表
链表的概念及结构
**概念:**链表是一种==物理存储结构上非连续==、非顺序的存储结构,数据元素的==逻辑顺序==是通过链表中的==指针链接==次序实现的
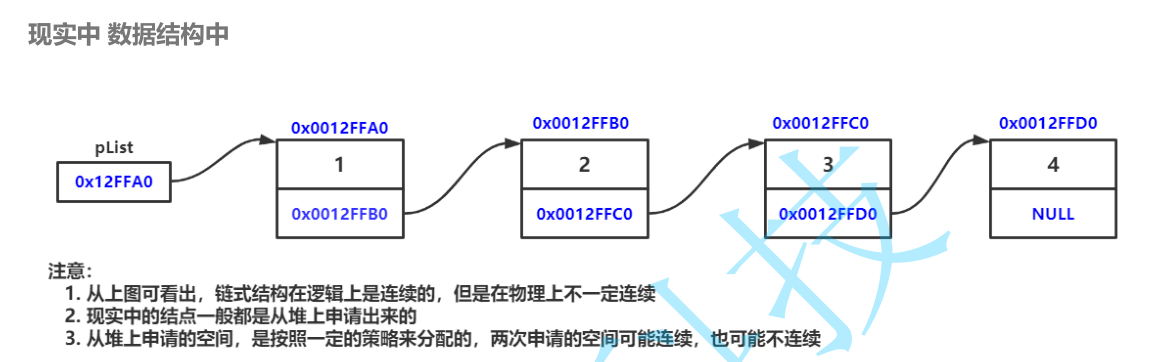
链表的分类
实际中链表的结构非常多样,以下情况组合起来就有8种链表结构
1.单向或者双向
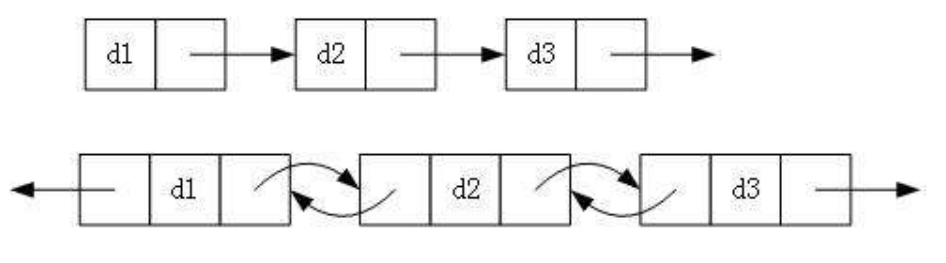
2.带头或者不带头
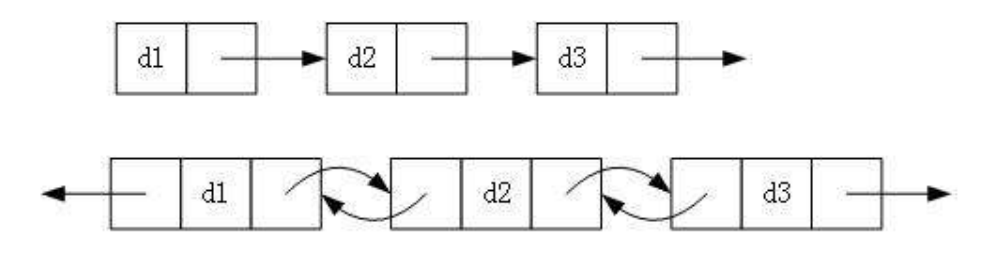
3.循环或者非循环
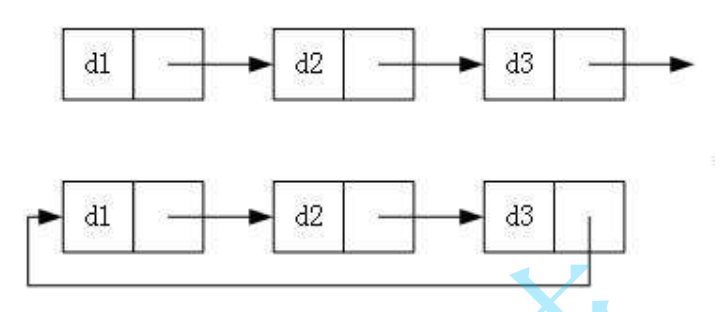
==虽然有那么多的链表的结构,但是我们实际中最常用的还是两种结构==
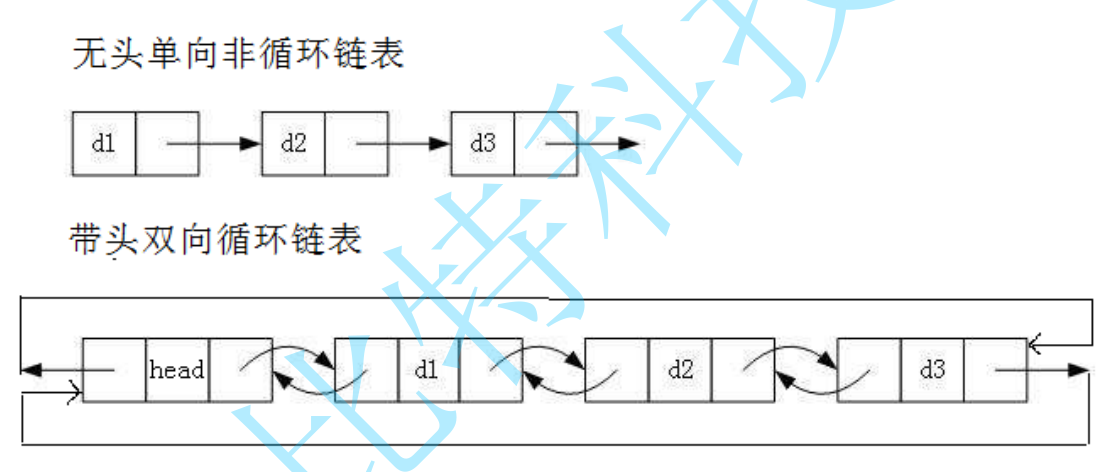
- 无头单向非循环链表:==结构简单,==一般不会单独用来存数据。实际中更多是作为==其他数据结构的子结构==,如哈希桶、图的邻接表等等。另外这种结构在==笔试面试==中出现很多。
- 带头双向循环链表:==结构最复杂,==一般用在单独存储数据。实际中使用的链表数据结构,都是带头双向循环链表。另外这个结构虽然结构复杂,但是使用代码实现以后会发现结构会带来很多优势,实现反而
简单了,后面我们代码实现了就知道了。
链表的实现
无头单向
单链表节点
typedef int SLTDataType;
//单链表节点
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
单链表打印函数SListPrint
有时候一步一步调试会不怎么方便所以我们先把打印函数写出来,然后再写增删改查也不迟
//单链表打印
void SListPrint(SLTNode* phead)
{
SLTNode* cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
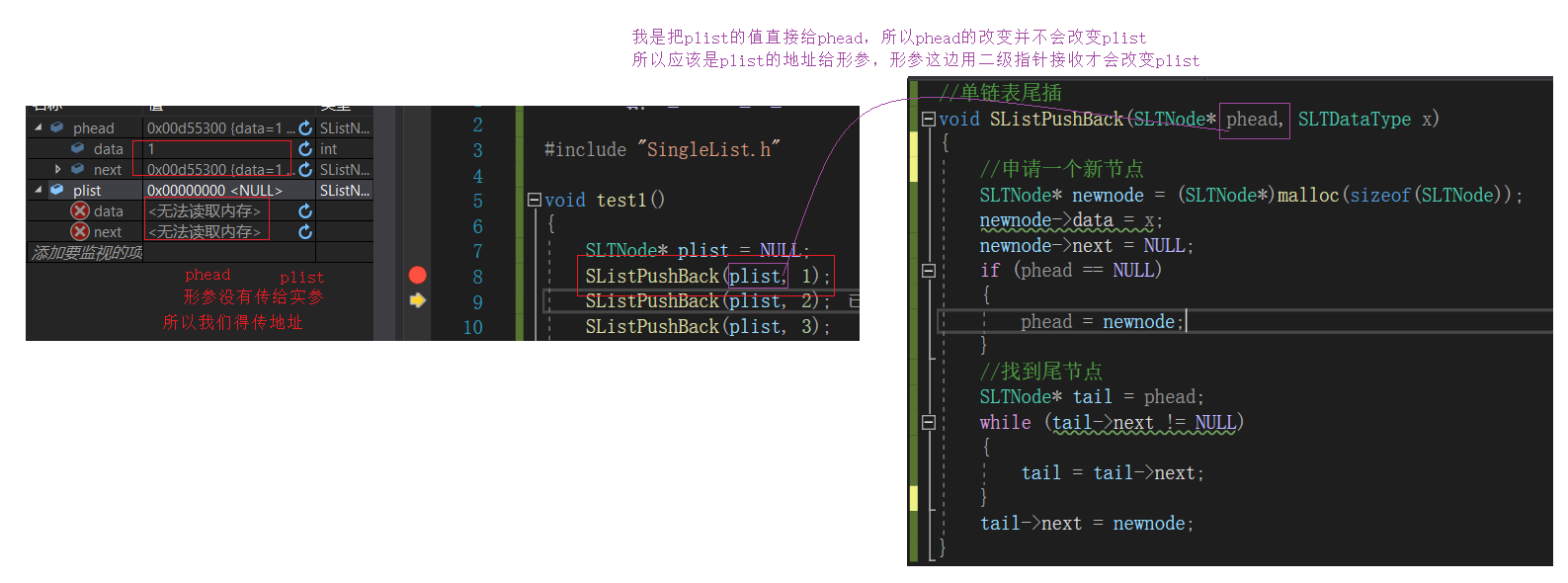
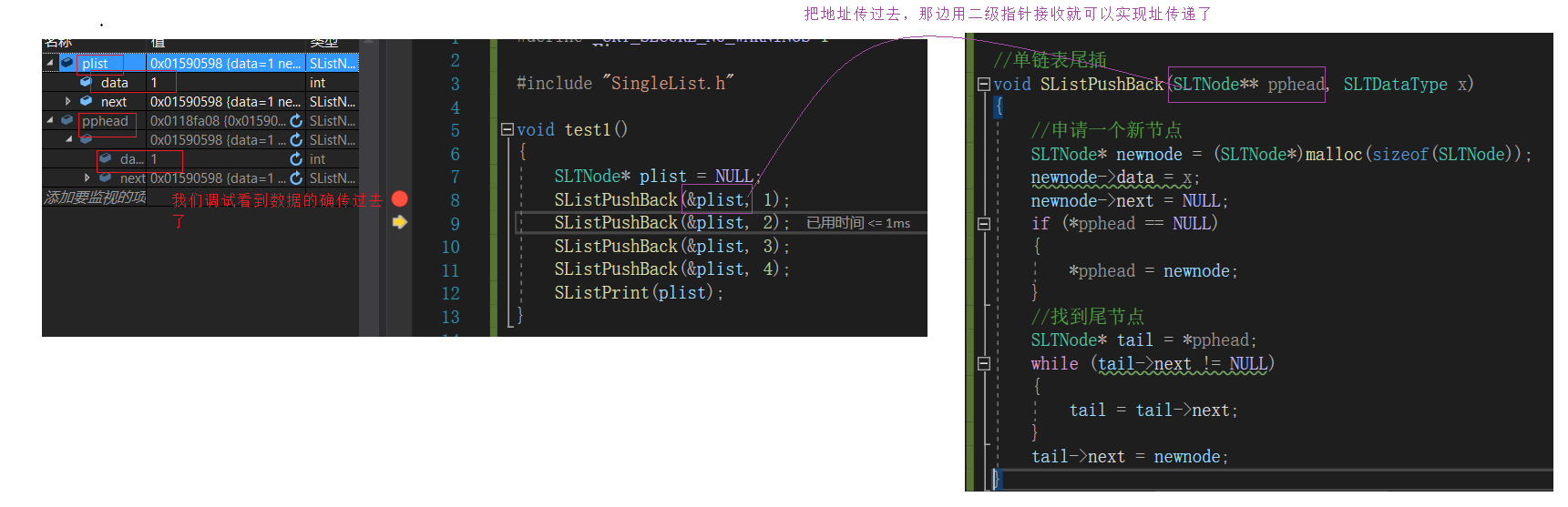
单链表尾插函数SListPushBack
只要是插入不管你如何如何反正是插入你都得扩容,当然单链表扩容的单位是节点
//单链表尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
//申请一个新节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
if (*pphead == NULL)
{
*pphead = newnode;
}
else
{
//找到尾节点
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
获得单链表节点函数BuySListNode
这时我是想写头插,但是思考一番发现,创建节点这一步会和尾插里面有些步骤重复,因此我们可以把重复的步骤抽离出来写成一个函数就会方便一些
//获得单链表节点函数
SLTNode* BuySListNode(SLTDataType x)
{
//申请一个新节点
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
if (newnode == NULL)//实际上如果申请失败了,就说明堆没有多少空间了
{
printf("申请失败\n");
exit(-1);
}
newnode->data = x;
newnode->next = NULL;
return newnode;//然后把节点指针返回出去
}
==所以前面那个尾插就可以用这个复写了==
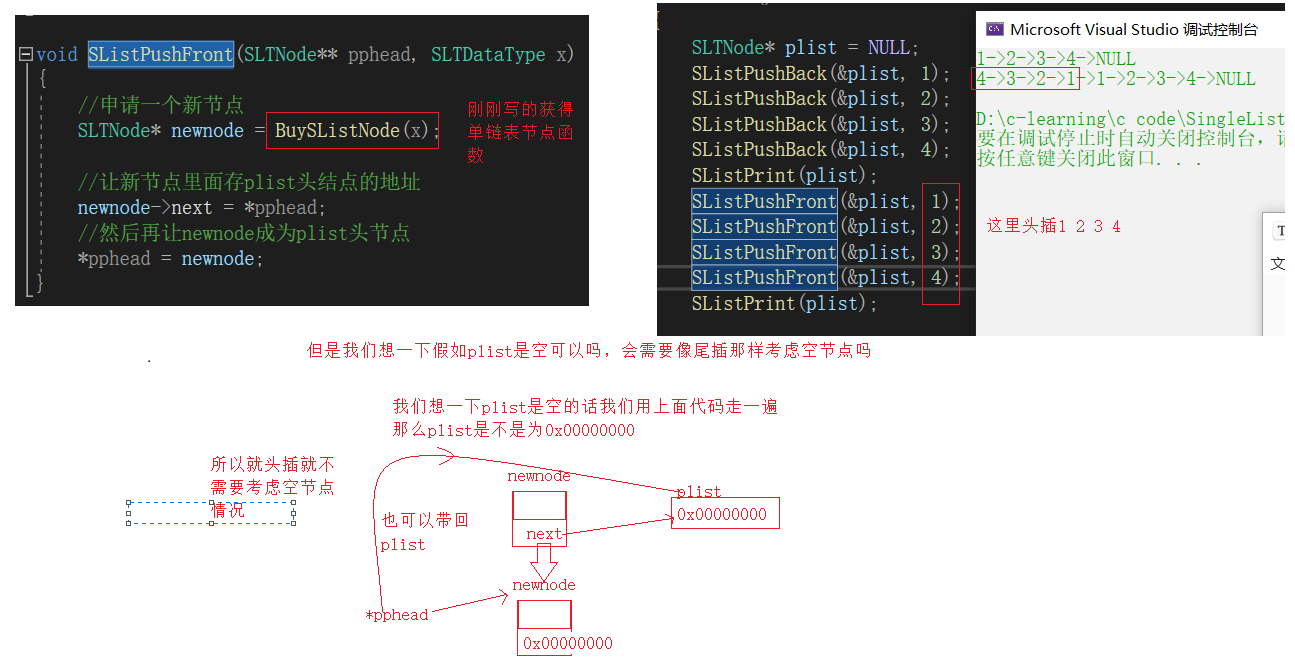
单链表头插函数SListPushFront
//单链表头插函数
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
//申请一个新节点
SLTNode* newnode = BuySListNode(x);
//让新节点里面存plist头结点的地址
newnode->next = *pphead;
//然后再让newnode成为plist头节点
*pphead = newnode;
}
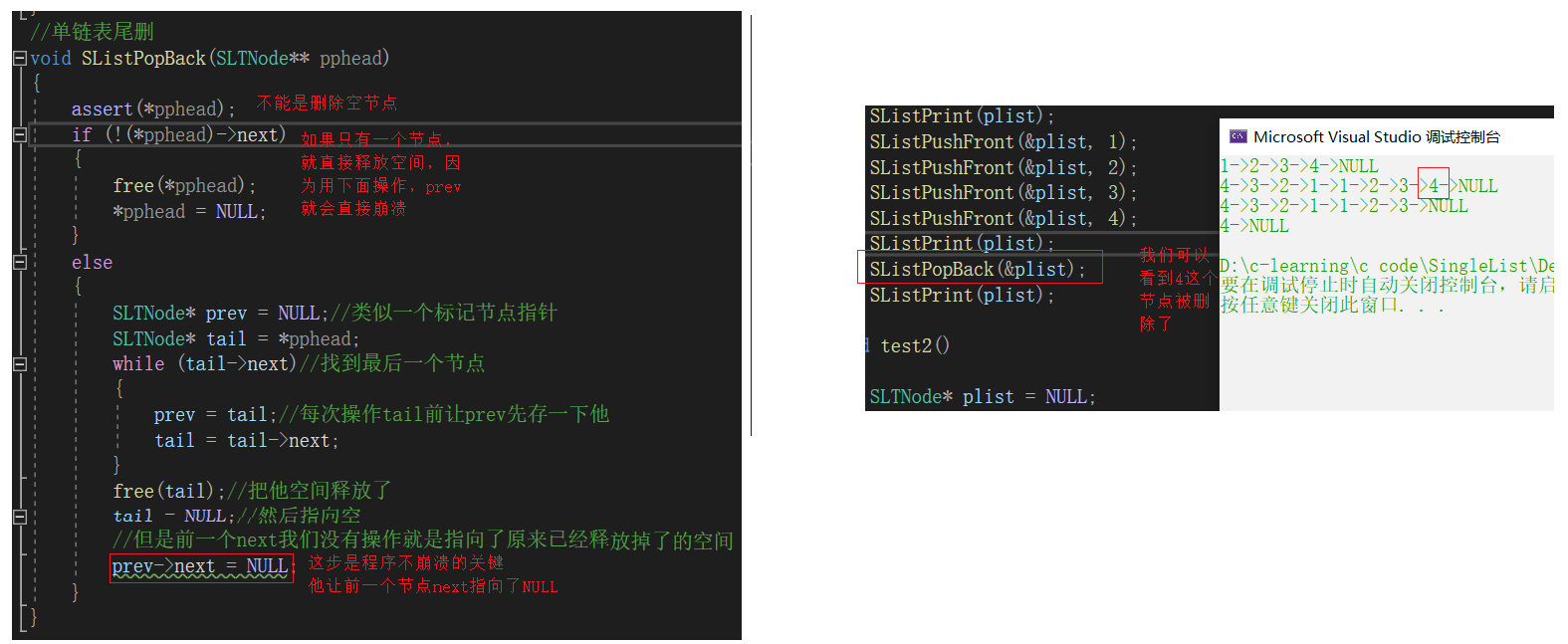
单链表尾删函数SListPopBack
//单链表尾删
void SListPopBack(SLTNode** pphead)
{
assert(*pphead);
if (!(*pphead)->next)
{
free(*pphead);
*pphead = NULL;
}
else
{
SLTNode* prev = NULL;//类似一个标记节点指针
SLTNode* tail = *pphead;
while (tail->next)//找到最后一个节点
{
prev = tail;//每次操作tail前让prev先存一下他
tail = tail->next;
}
free(tail);//把他空间释放了
tail = NULL;//然后指向空
//但是前一个next我们没有操作就是指向了原来已经释放掉了的空间
prev->next = NULL;
}
}
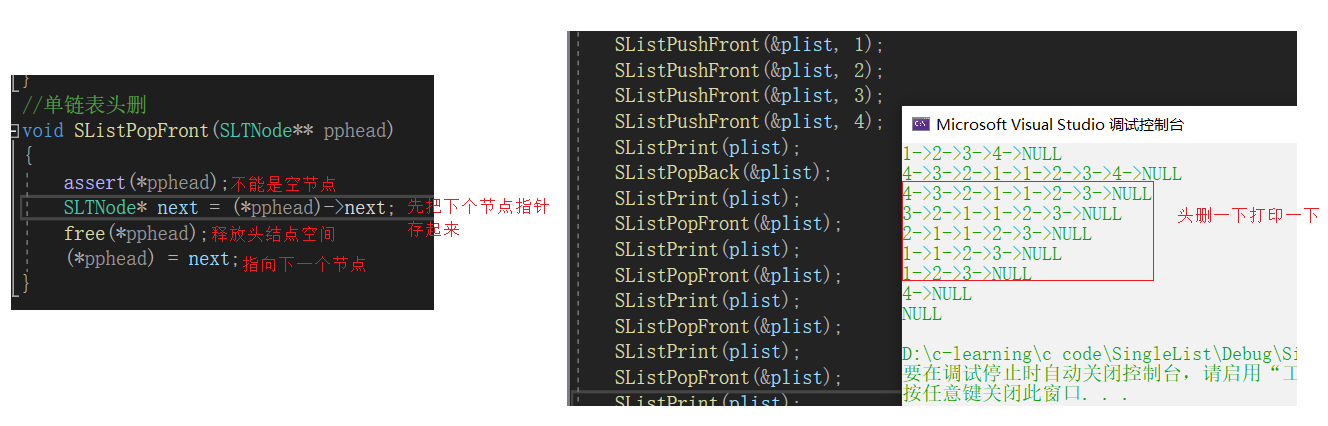
单链表头删函数SListPopFront
//单链表头删
void SListPopFront(SLTNode** pphead)
{
assert(*pphead);
SLTNode* next = (*pphead)->next;
free(*pphead);
(*pphead) = next;
}
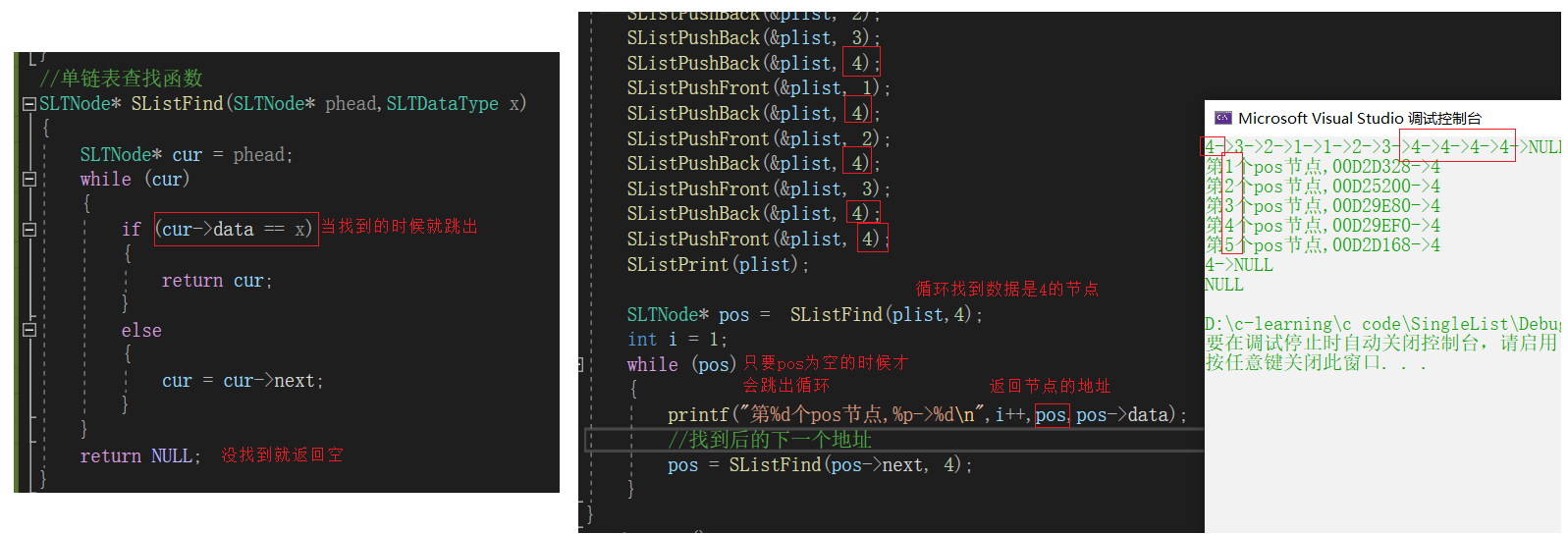
单链表查找函数
//单链表查找函数
SLTNode* SListFind(SLTNode* phead,SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
else
{
cur = cur->next;
}
}
return NULL;
}
主文件的写法
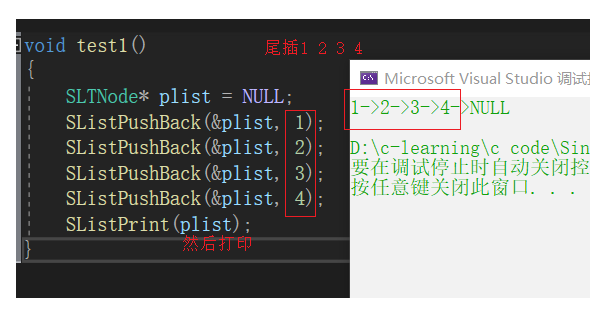
void test1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPushFront(&plist, 1);
SListPushBack(&plist, 4);
SListPushFront(&plist, 2);
SListPushBack(&plist, 4);
SListPushFront(&plist, 3);
SListPushBack(&plist, 4);
SListPushFront(&plist, 4);
SListPrint(plist);
SLTNode* pos = SListFind(plist,4);
int i = 1;
while (pos)
{
printf("第%d个pos节点,%p->%d\n",i++,pos,pos->data);
//找到后的下一个地址
pos = SListFind(pos->next, 4);
}
}
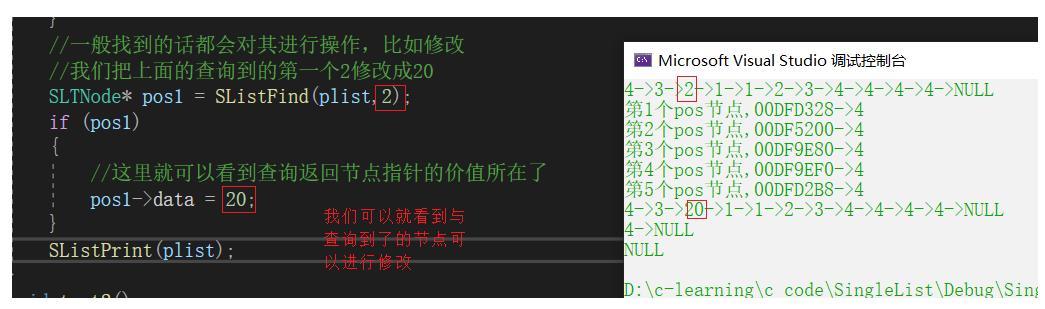
查询后修改
SLTNode* pos1 = SListFind(plist,2);
if (pos1)
{
//这里就可以看到查询返回节点指针的价值所在了
pos1->data = 20;
}
SListPrint(plist);
单链表插入函数
==可以通过和查询函数配合来进行插入==
//单链表插入函数
//在pos前面插入,这个pos在哪里来呢,就是从前面查找函数来
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
//首先创建节点
SLTNode* newnode = BuySListNode(x);
if (pos == *pphead)
{
newnode->next = *pphead;
*pphead = newnode;
}
else
{
//找到pos的前一个位置
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}

==看到上面就是知道单链表不太适合在前面插入,而是适合在后面插入,因为前插你要知道当前位置前面的那一个节点位置就会有点复杂,而后插就没有这个prev的节点指针了==
单链表后插函数
//单链表后插函数
void SListInsertAfter(SLTNode* pos, SLTDataType x)
{
//创建一个新的节点
SLTNode* newnode = BuySListNode(x);
newnode->next = pos->next;
pos->next = newnode;
}

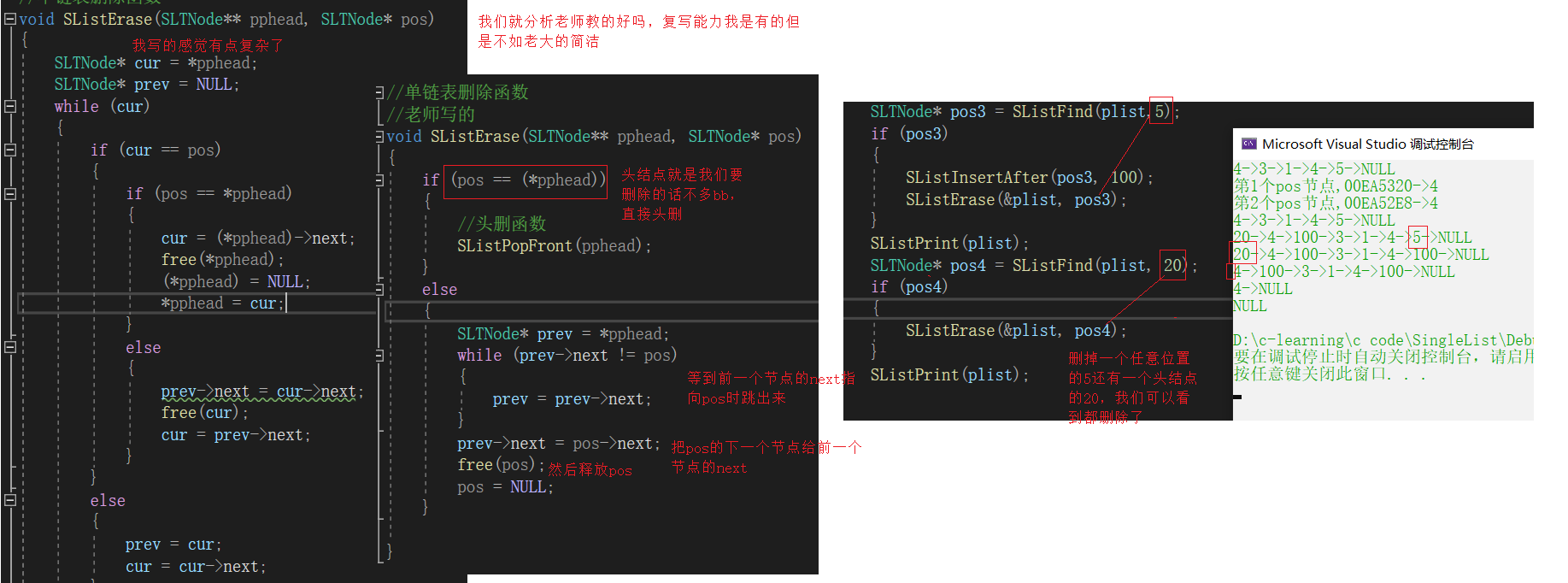
单链表删除函数SListErase
////单链表删除函数
////这是我自己写的,我们看下面老师写的
//void SListErase(SLTNode** pphead, SLTNode* pos)
//{
// SLTNode* cur = *pphead;
// SLTNode* prev = NULL;
// while (cur)
// {
// if (cur == pos)
// {
// if (pos == *pphead)
// {
// cur = (*pphead)->next;
// free(*pphead);
// (*pphead) = NULL;
// *pphead = cur;
// }
// else
// {
// prev->next = cur->next;
// free(cur);
// cur = prev->next;
// }
// }
// else
// {
// prev = cur;
// cur = cur->next;
// }
// }
//}
//单链表删除函数
//老师写的
void SListErase(SLTNode** pphead, SLTNode* pos)
{
if (pos == (*pphead))
{
//头删函数
SListPopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
pos = NULL;
}
}
==当然还有简洁的后删函数==
单链表后删函数
//单链表后删函数
void SListEraseAfter(SLTNode* pos)
{
assert(pos->next);
SLTNode* nextnode = pos->next;
pos->next = nextnode->next;
free(nextnode);
}

单链表销毁函数
//单链表销毁函数
void SListDestory(SLTNode** pphead)
{
SLTNode* cur = *pphead;
while (cur)
{
SLTNode* nextnode = cur->next;
free(cur);
cur = nextnode;
}
*pphead = NULL;
}
练习题(==从小到大老师一直教我们数形结合这东西是逻辑的根本,往往简单的东西有人掌握了就变成了厉害人物,反而那些不在意图的,死在途中无人问津,曾经我也是喜欢走的快,但是现在我放慢了脚步,为了走得远==)
1.移除链表元素
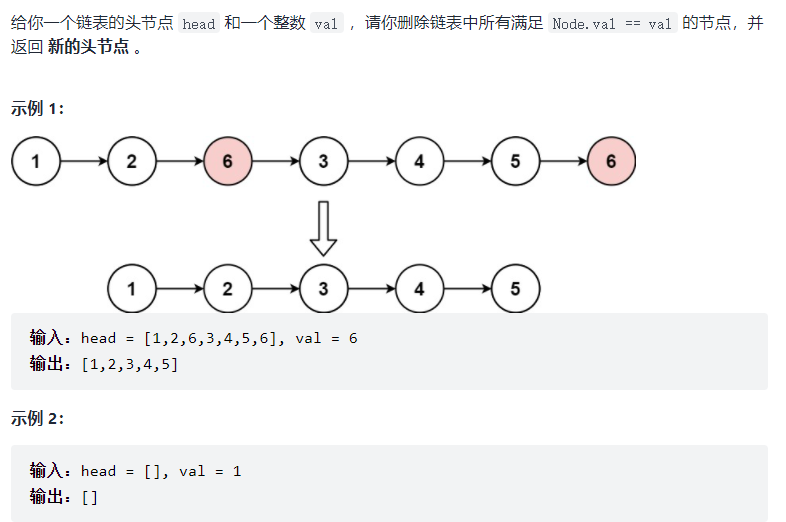
图解
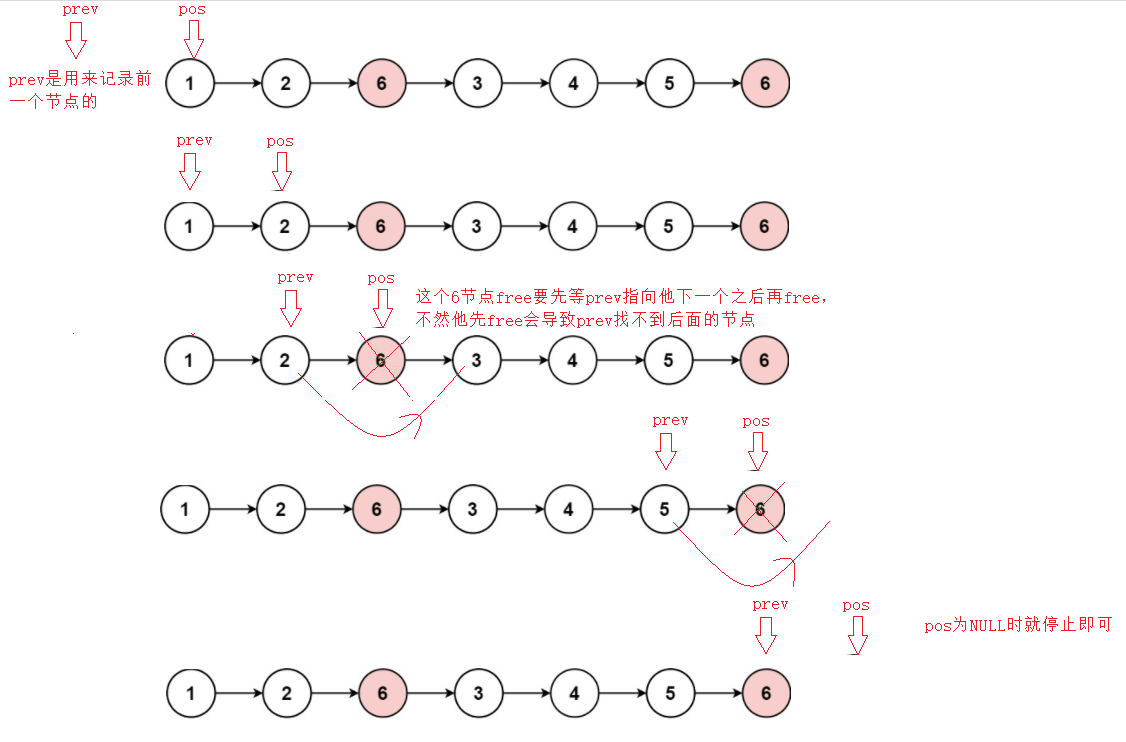
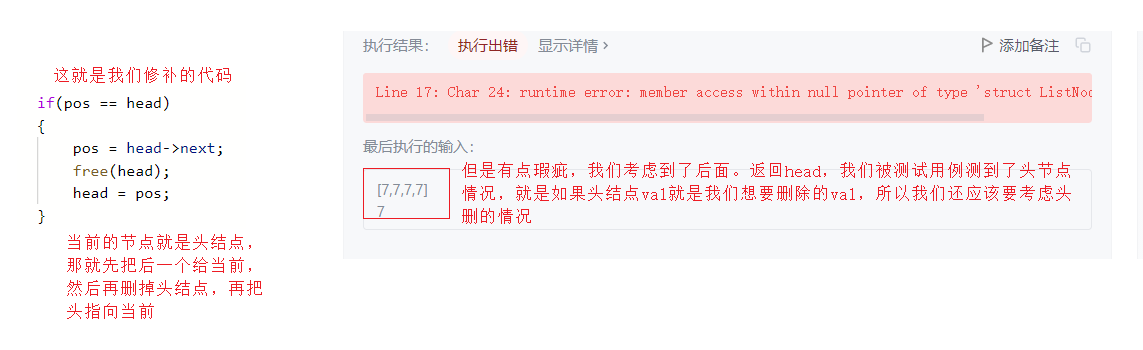
struct ListNode* removeElements(struct ListNode* head, int val){
struct ListNode* pos = head;
struct ListNode* prev = NULL;
while(pos)
{
if(pos->val == val)
{
if(pos == head)
{
pos = head->next;
free(head);
head = pos;
}
else
{
prev->next = pos->next;
free(pos);
pos = prev->next;
}
}
else
{
prev = pos;
pos = pos->next;
}
}
return head;
}
2.反转链表
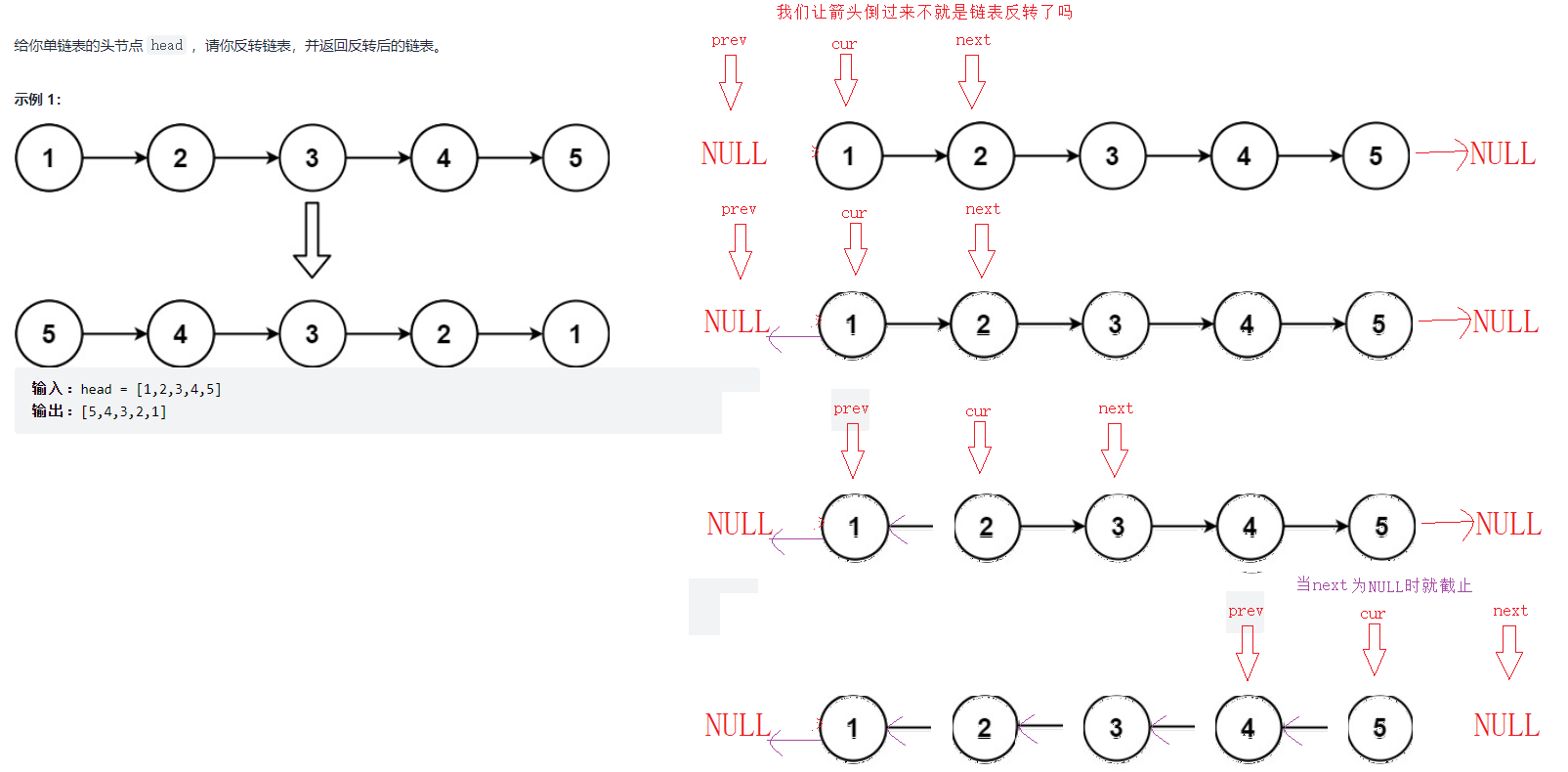
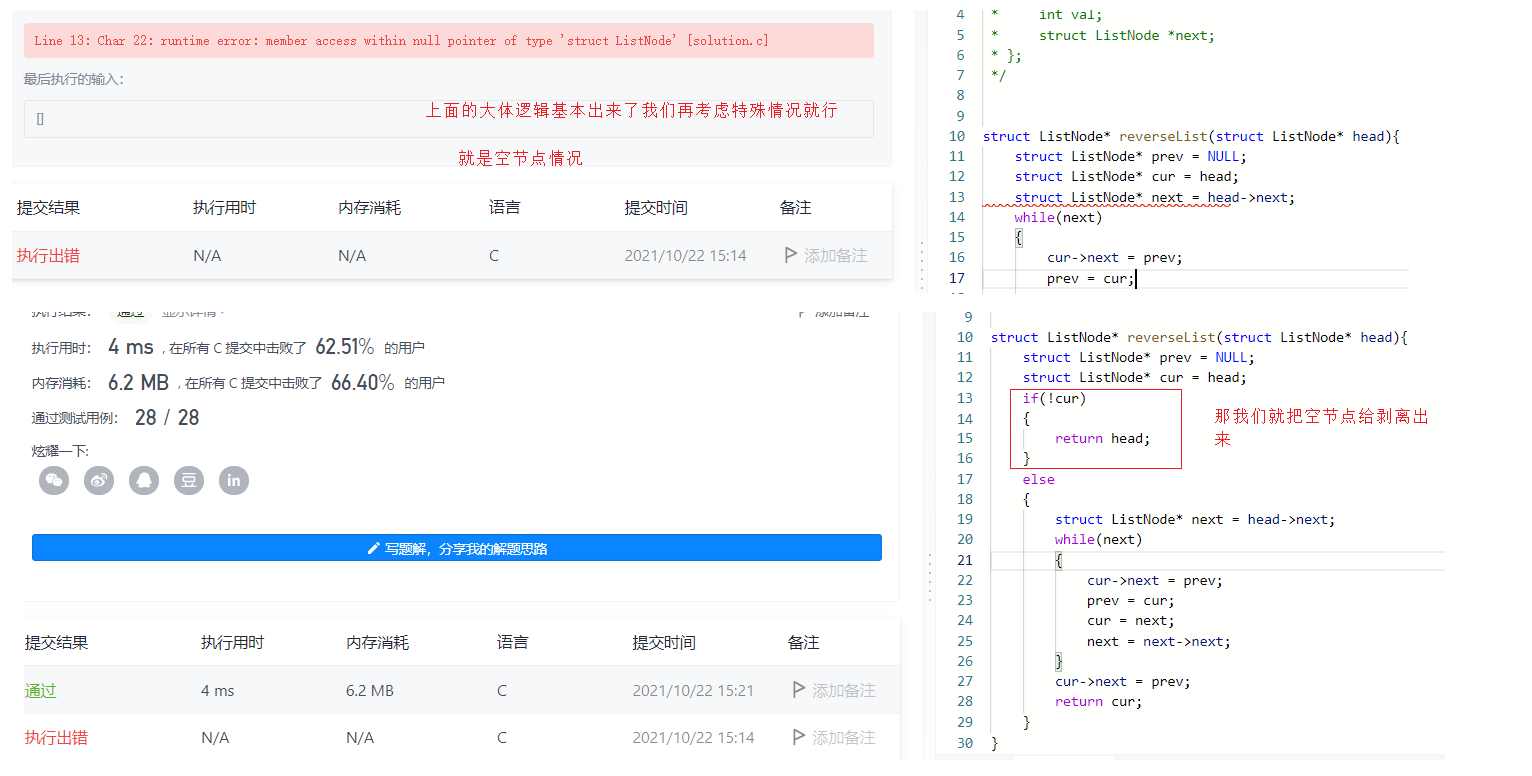
struct ListNode* reverseList(struct ListNode* head){
struct ListNode* prev = NULL;
struct ListNode* cur = head;
if(!cur)
{
return head;
}
else
{
struct ListNode* next = head->next;
while(next)
{
cur->next = prev;
prev = cur;
cur = next;
next = next->next;
}
cur->next = prev;
return cur;
}
}
3.链表的中间结点


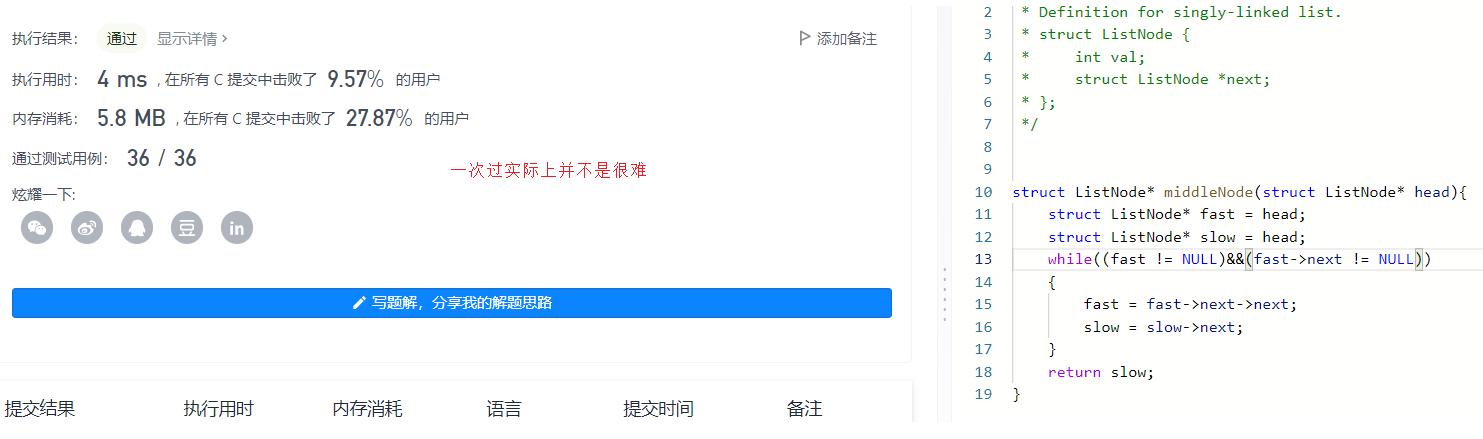
struct ListNode* middleNode(struct ListNode* head){
struct ListNode* fast = head;
struct ListNode* slow = head;
while((fast != NULL)&&(fast->next != NULL))
{
fast = fast->next->next;
slow = slow->next;
}
return slow;
}
4.链表中倒数第k个结点

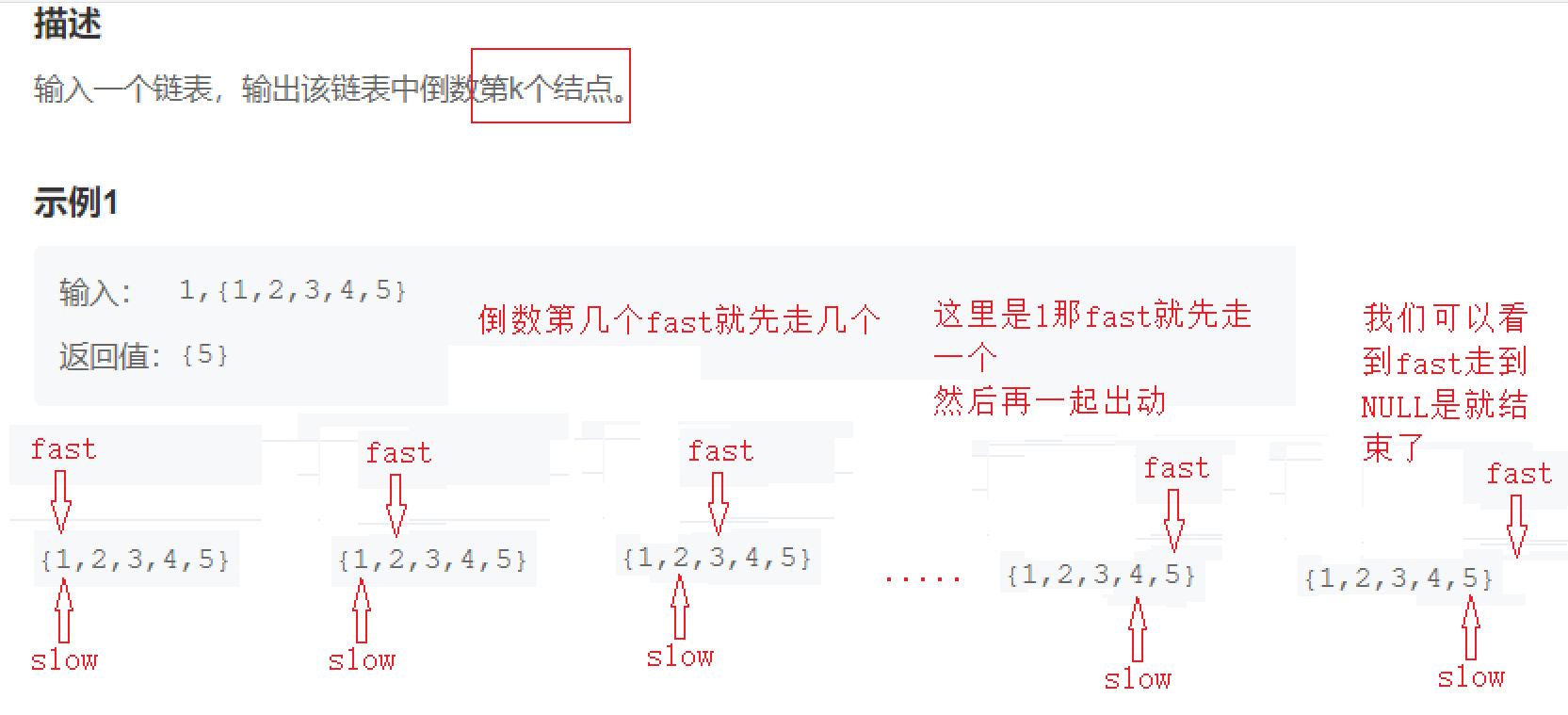
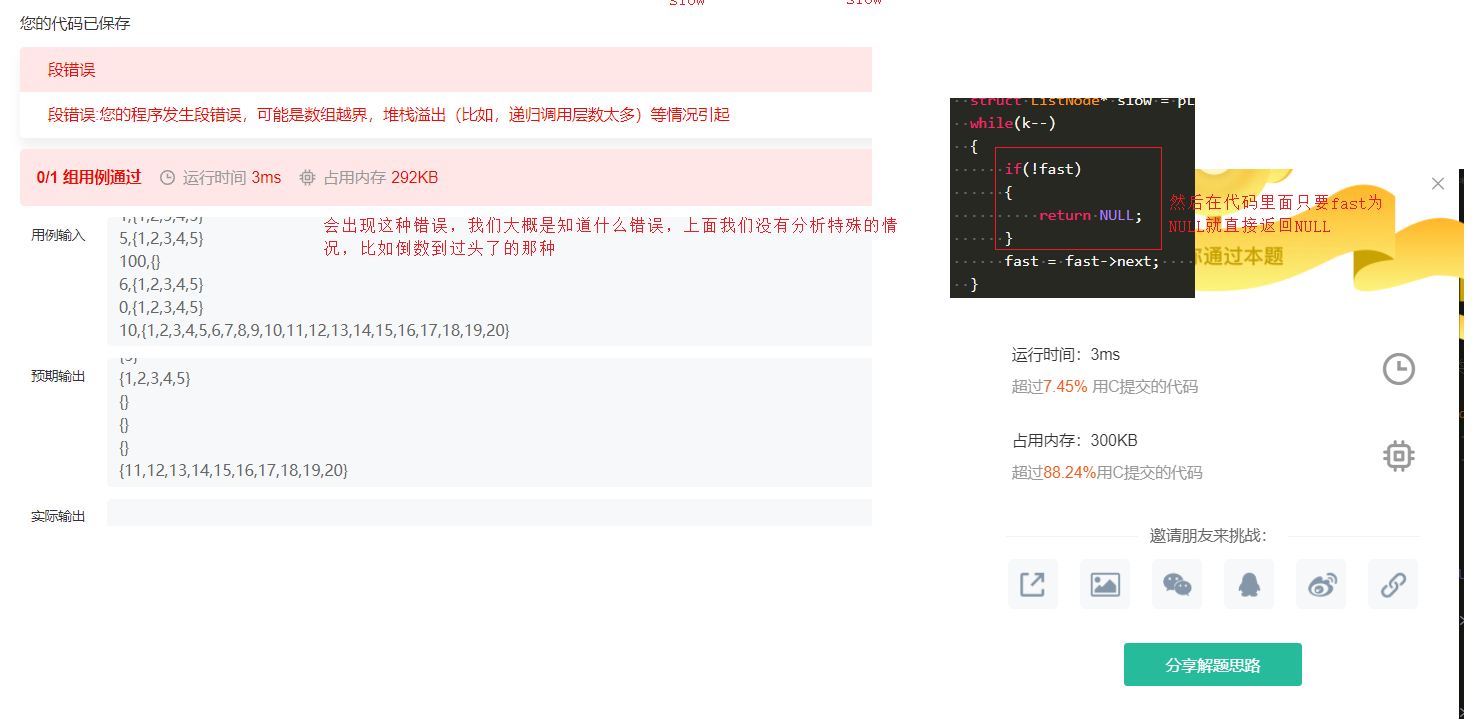
struct ListNode* FindKthToTail(struct ListNode* pListHead, int k ) {
struct ListNode* fast = pListHead;
struct ListNode* slow = pListHead;
while(k--)
{
if(!fast)
{
return NULL;
}
fast = fast->next;
}
while(fast)
{
fast = fast->next;
slow = slow->next;
}
return slow;
}
5.合并两个有序链表
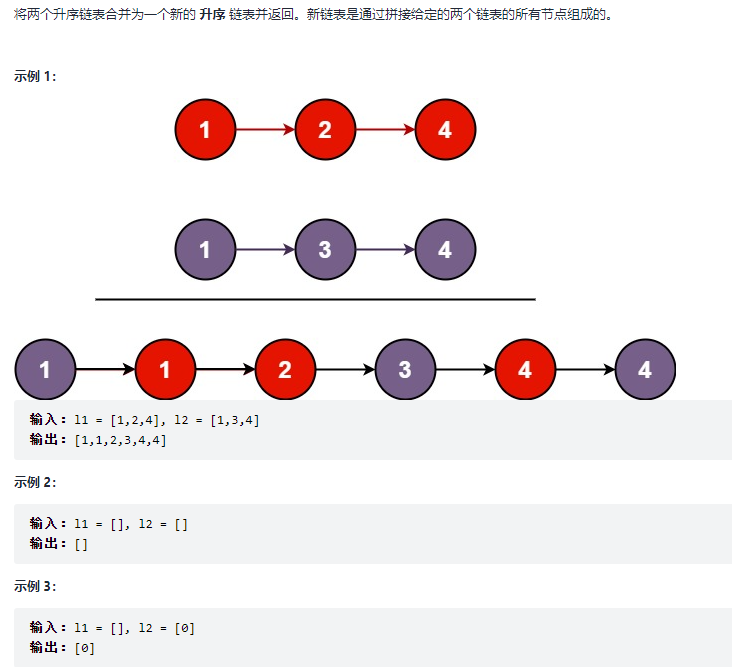
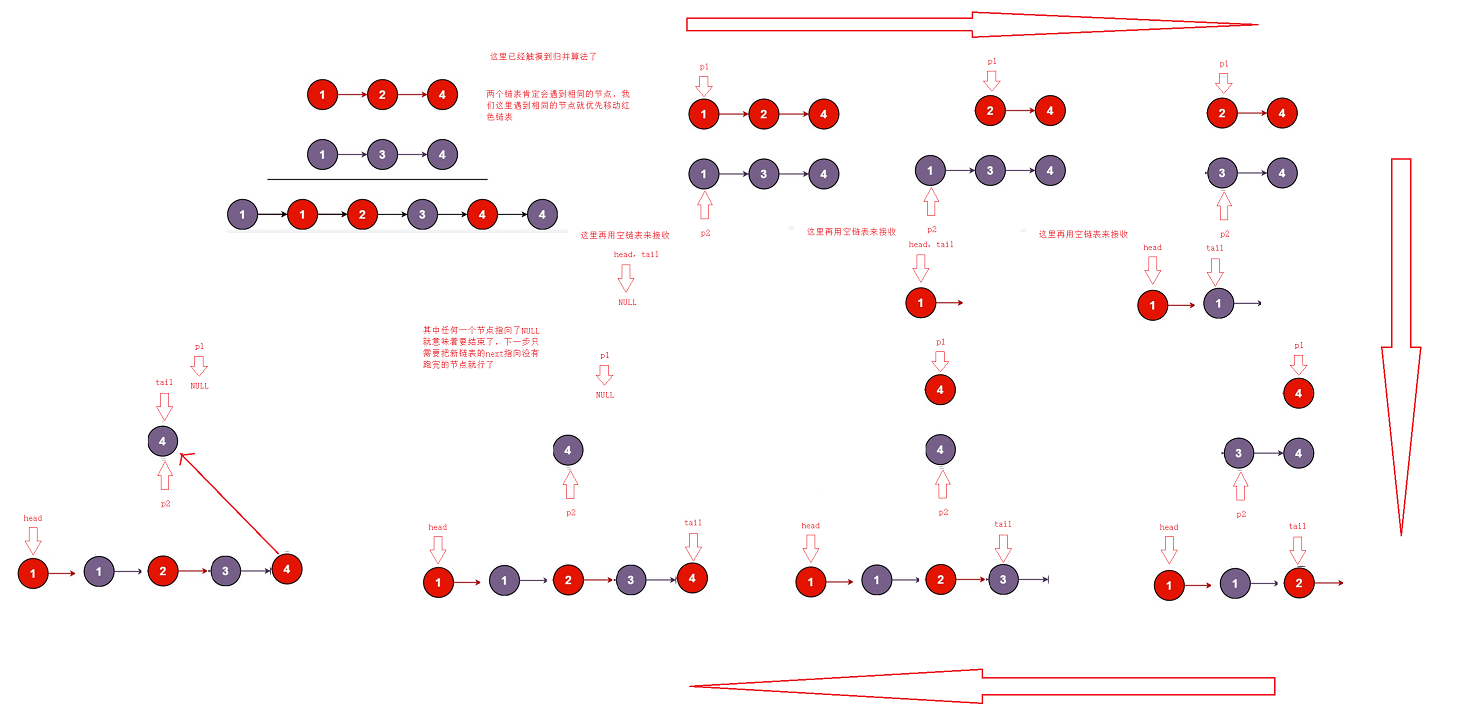
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
struct ListNode* head = NULL;
struct ListNode* tail = NULL;
if(!l1)
return l2;
if(!l2)
return l1;
while(l1&&l2)
{
if(l1->val <= l2->val)
{
if(!head)
{
head = tail = l1;
}
else
{
tail->next = l1;
tail = l1;
}
l1 = l1->next;
}
else
{
if(!head)
{
head = tail = l2;
}
else
{
tail->next = l2;
tail = l2;
}
l2 = l2->next;
}
}
tail->next = (l1 == NULL) ? l2 : l1;
return head;
}
6.链表分割

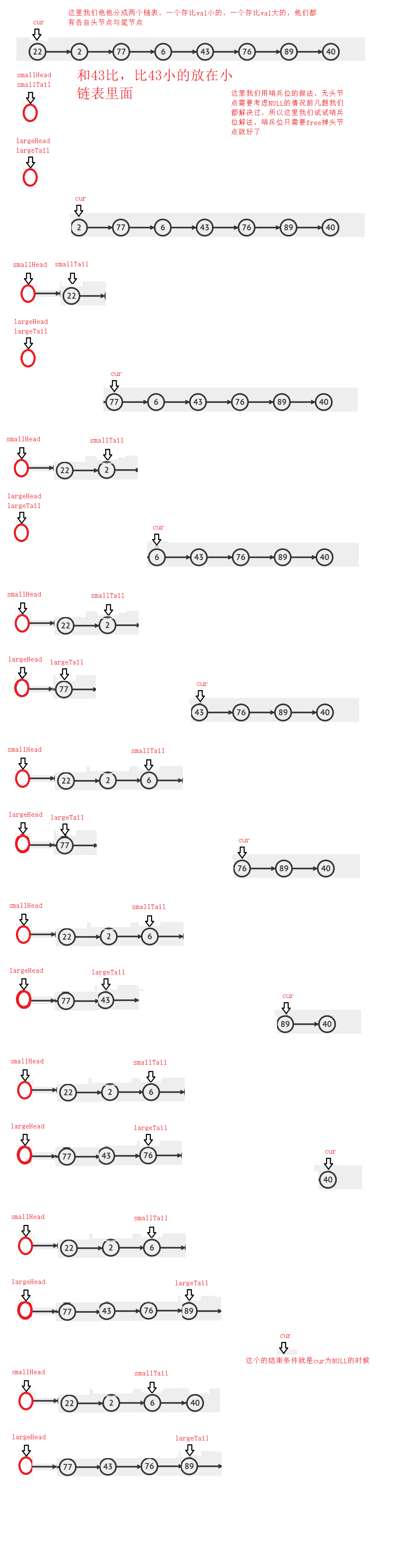
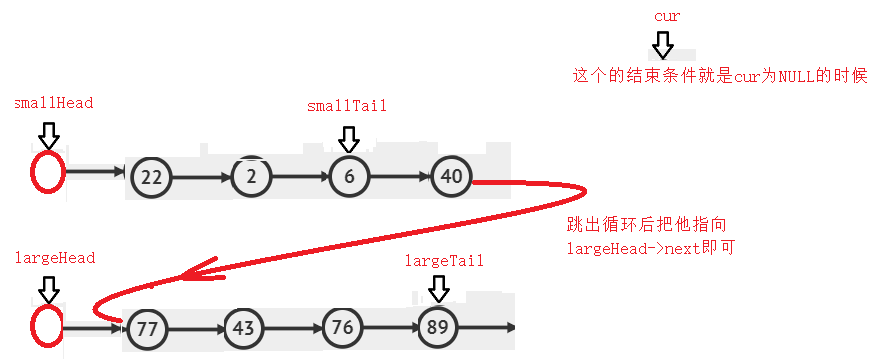
==跳出循环后==

class Partition {
public:
ListNode* partition(ListNode* pHead, int x) {
//创建两个链表的哨兵位
struct ListNode* smallHead = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* largeHead = (struct ListNode*)malloc(sizeof(struct ListNode));
struct ListNode* smallTail = smallHead;
struct ListNode* largeTail = largeHead;
struct ListNode* cur = pHead;
while(cur)
{
if(cur->val < x)
{
smallTail->next = cur;
smallTail = cur;
//既然都有这句就把他拿到下面
//cur = cur->next;
}
else
{
largeTail->next = cur;
largeTail = cur;
// cur = cur->next;
}
cur = cur->next;
}
//链接两个链表
smallTail->next = largeHead->next;
largeTail->next = NULL;
struct ListNode* newnode = smallHead->next;
//把哨兵位free掉
free(smallHead);
free(largeHead);
return newnode;
}
};
7.链表的回文结构
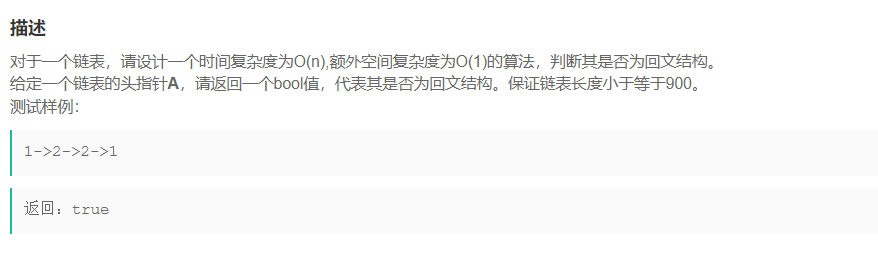
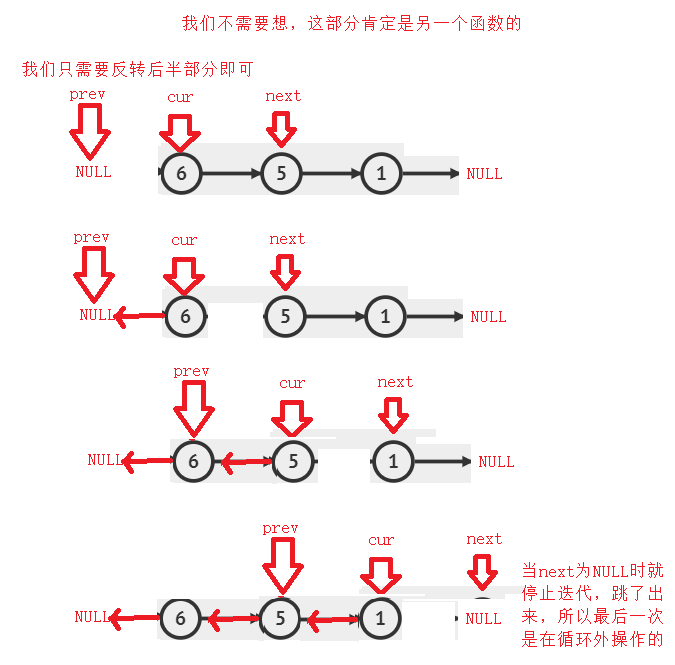
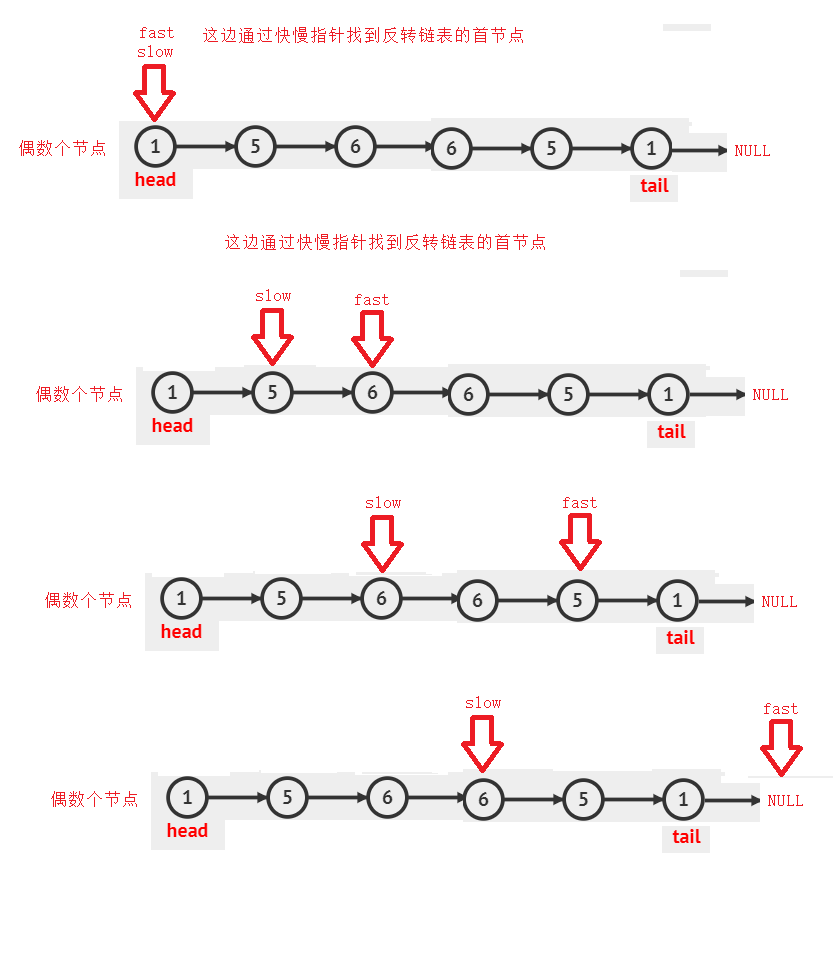
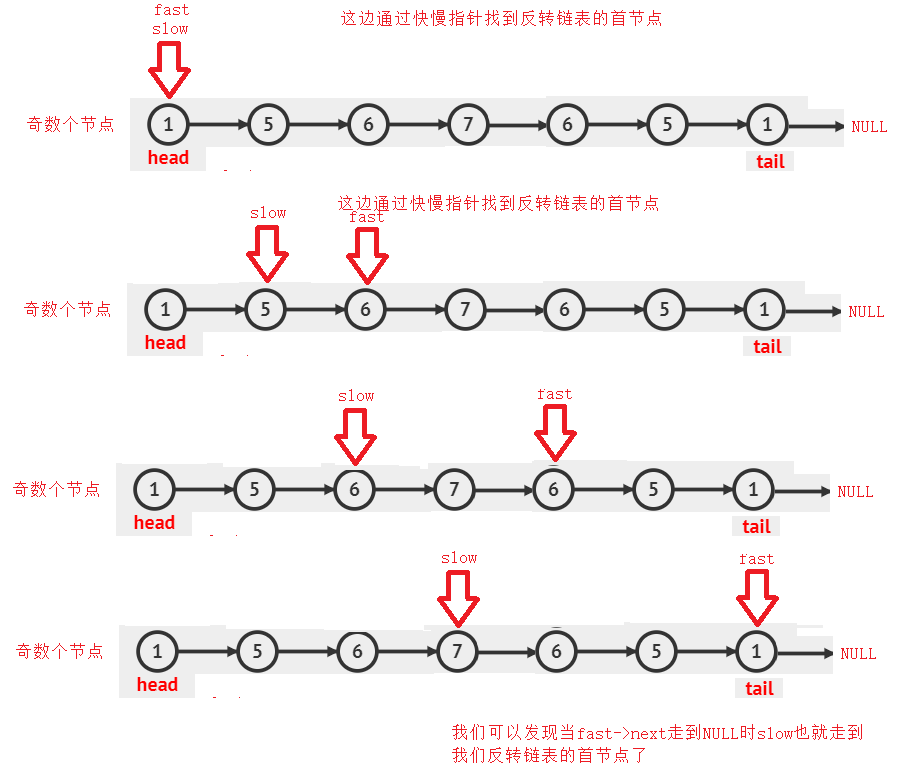
==所以我们先找到反转链表的首节点,然后反转,再看看是否是回纹链表==

struct ListNode* ReversalNode(struct ListNode* phead)
{
struct ListNode* prev = NULL;
struct ListNode* cur = phead;
if(!cur)
{
return cur;
}
else
{
struct ListNode* next = phead->next;
while(next)
{
cur->next = prev;
prev = cur;
cur = next;
next = next->next;
}
cur->next = prev;
return cur;
}
}
//找中间节点
struct ListNode* MidNode(struct ListNode* phead)
{
struct ListNode * fast,*slow;
fast = slow = phead;
while(fast && fast->next)
{
slow = slow->next;
fast = fast->next->next;
}
return slow;
}
class PalindromeList {
public:
bool chkPalindrome(ListNode* A) {
struct ListNode* curA = A;
//这时再准备反转链表
struct ListNode* curR = ReversalNode(MidNode(A));
while(curR)
{
if(curA->val != curR->val)
return 0;
curA = curA->next;
curR = curR->next;
}
return true;
}
};
==什么时候你的代码能力就合格了:心里有思路,就能用代码实现出来==
==什么时候你的调试能力就合格了:你分析代码调试的时间超过了你写代码的时间==
8. 相交链表(这题力扣有点不严谨考虑NULL跑不过去,不考虑反而跑过去了)

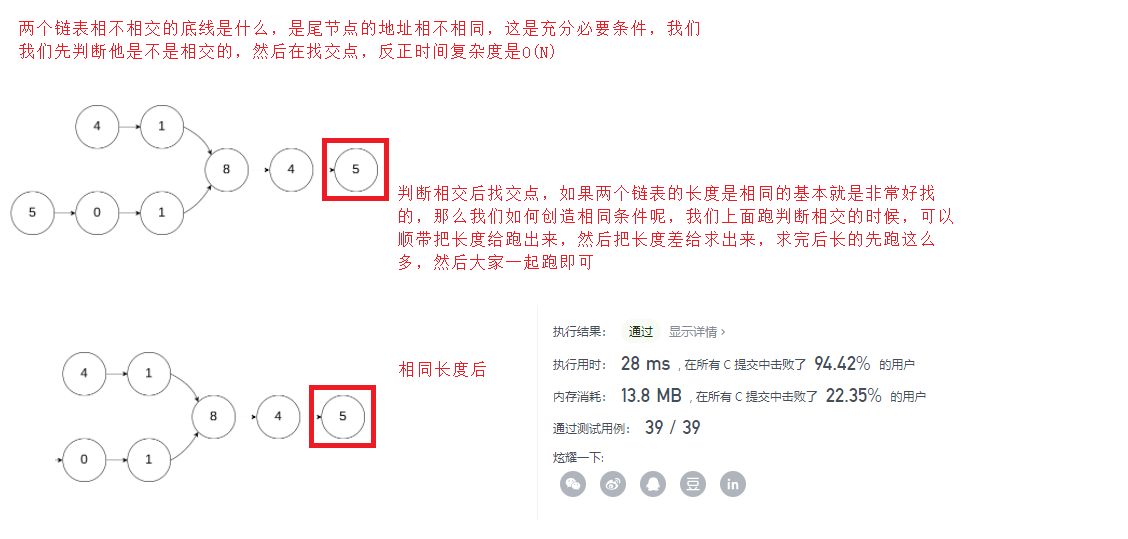
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) {
struct ListNode * tailA = headA;
struct ListNode * tailB = headB;
int lenA = 0;
int lenB = 0;
while(tailA->next)
{
tailA = tailA->next;
lenA++;
}
while(tailB->next)
{
tailB = tailB->next;
lenB++;
}
if(tailA != tailB)
return NULL;
int gap = lenA>lenB ? lenA-lenB : lenB-lenA;
//我们先假设A长B短
struct ListNode *longList = headA;
struct ListNode *smallList = headB;
//然后再判断一下,这样的好处是我们不需要写一模一样的函数了
if(lenB>lenA)
{
longList = headB;
smallList = headA;
}
while(gap--)
{
longList = longList->next;
}
while(longList != smallList)
{
longList = longList->next;
smallList = smallList->next;
}
return longList;
}

【版权声明】本文为华为云社区用户原创内容,未经允许不得转载,如需转载请自行联系原作者进行授权。如果您发现本社区中有涉嫌抄袭的内容,欢迎发送邮件进行举报,并提供相关证据,一经查实,本社区将立刻删除涉嫌侵权内容,举报邮箱:
cloudbbs@huaweicloud.com
- 点赞
- 收藏
- 关注作者
评论(0)