从0到1打造正则表达式执行引擎(二) NFA转DFA

从0到1打造正则表达式执行引擎(一) https://github.com/xindoo/regex
DFA和NFA
我们已经多次提到了NFA和DFA,它俩究竟是啥?有啥区别?
首先,NFA和DFA都是有限状态机,都是有向图,用来描述状态和状态之间的关系。其中NFA全称是非确定性有限状态自动机(Nondeterministic finite automaton),DFA全称是确定性有限状态自动机(Deterministic finite automaton)。
二者的差异主要在于确定性和非确定性,何为确定性? 确定性是指面对同一输入,不会出现有多条可行的路径执行下一个节点。有点绕,看完图你就理解了。
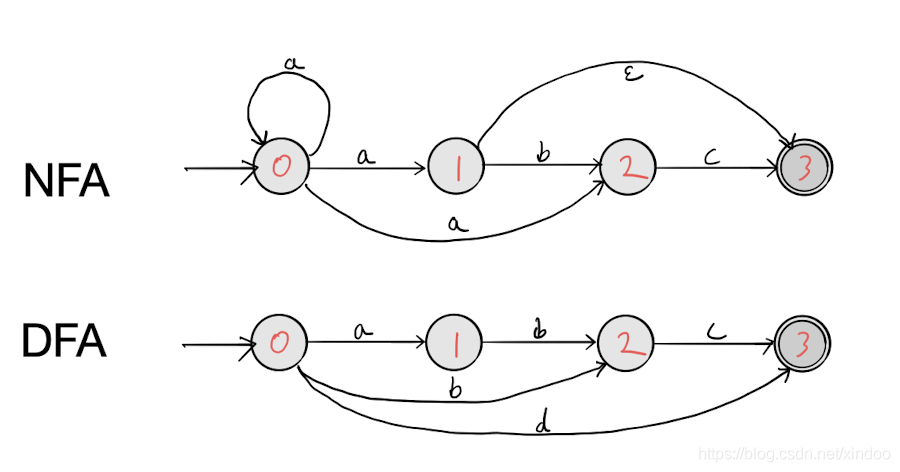
图示分别是一个NFA和DFA,上图之所以是NFA是因为它有节点具备不确定性,比如0节点,在输入"a"之后它分别可以到0 1 2 节点。还有,上图有 ϵ \epsilon ϵ边,它可以在没有输入的情况下跳到下一个节点,这也带来了不确定性。相反,下图DFA中,每个节点对某一特定的输入都只有最多一条边。
总结下NFA和DFA的区别就是,有ε边或者某个节点对同一输入对应多个状态的一定是NFA。
DFA和NFA存在等价性,也就是说任何NFA都可以转化为等价的DFA。由于NFA的非确定性,在面对一个输入的时候可能有多条可选的路径,所以在一条路径走不通的情况下,需要回溯到选择点去走另外一条路径。但DFA不同,在每个状态下,对每个输入不会存在多条路径,就不需要递归和回溯了,可以一条路走到黑。DFA的匹复杂度只有O(n),但因为要递归和回溯NFA的匹配复杂度达到了O(n^2)。 这也是为什么我们要将引擎中的NFA转化为DFA的主要原因。
NFA转DFA
算法
NFA转DFA的算法叫做子集构造法,其具体流程如下。
- 步骤1: NFA的初始节点和初始节点所有ε可达的节点共同构成DFA的初始节点,然后对初始DFA节点执行步骤2。
- 步骤2: 对当前DFA节点,找到其中所有NFA节点对输入符号X所有可达的NFA节点,这些节点沟通构成的DFA节点作为当前DFA节点对输入X可达的DFA节点。
- 步骤3: 如果步骤2中找到了新节点,就对新节点重复执行步骤2。
- 步骤4: 重复步骤2和步骤3直到找不DFA新节点为止。
- 步骤5: 把所有包含NFA终止节点的DFA节点标记为DFA的终止节点。
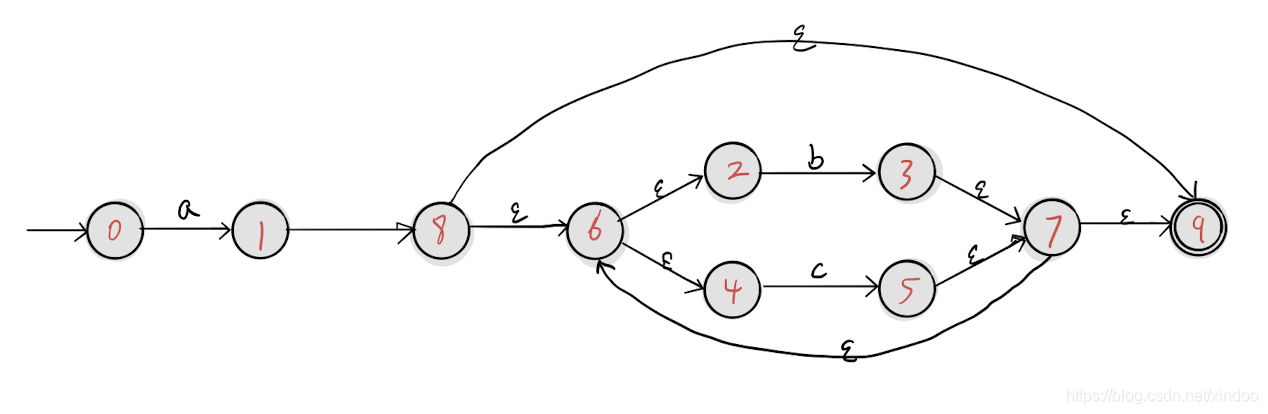
语言描述比较难理解,我们直接上例子。 我们已经拿上一篇网站中的正则表达式 a(b|c)* 为例,我在源码https://github.com/xindoo/regex中加入了NFA输出的代码, a(b|c)* 的NFA输出如下。
from to input
0-> 1 a
1-> 8 Epsilon
8-> 9 Epsilon
8-> 6 Epsilon
6-> 2 Epsilon
6-> 4 Epsilon
2-> 3 b
4-> 5 c
3-> 7 Epsilon
5-> 7 Epsilon
7-> 9 Epsilon
7-> 6 Epsilon
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
绘图如下:
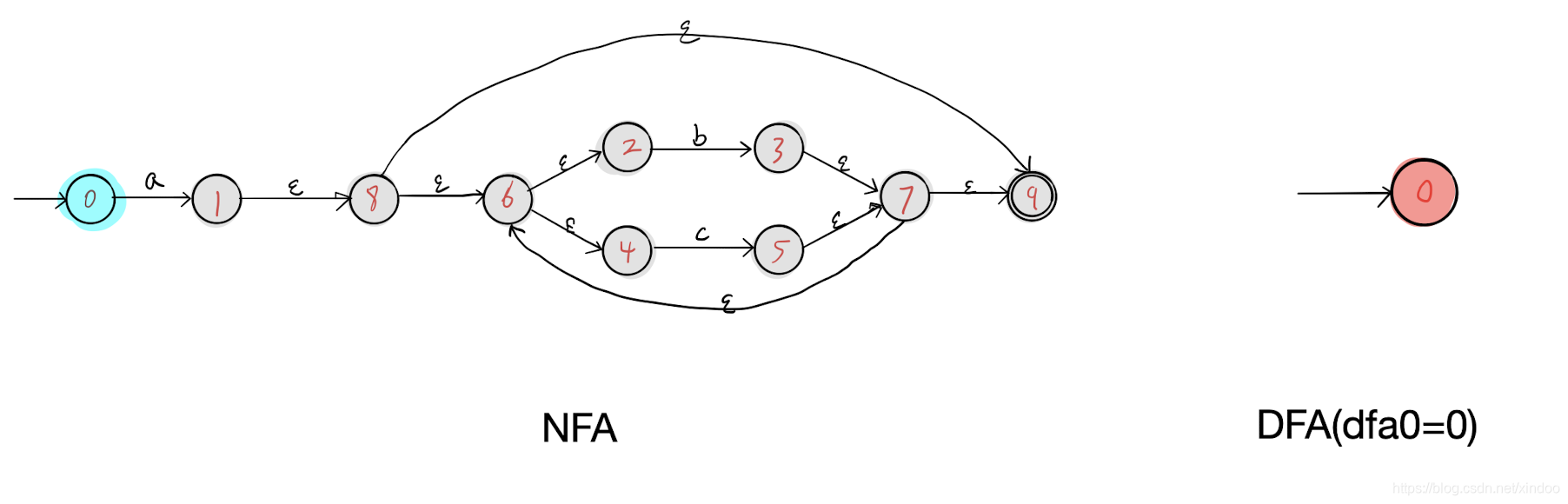
我们在上图的基础上执行步骤1 得到了节点0作为DFA的开始节点。
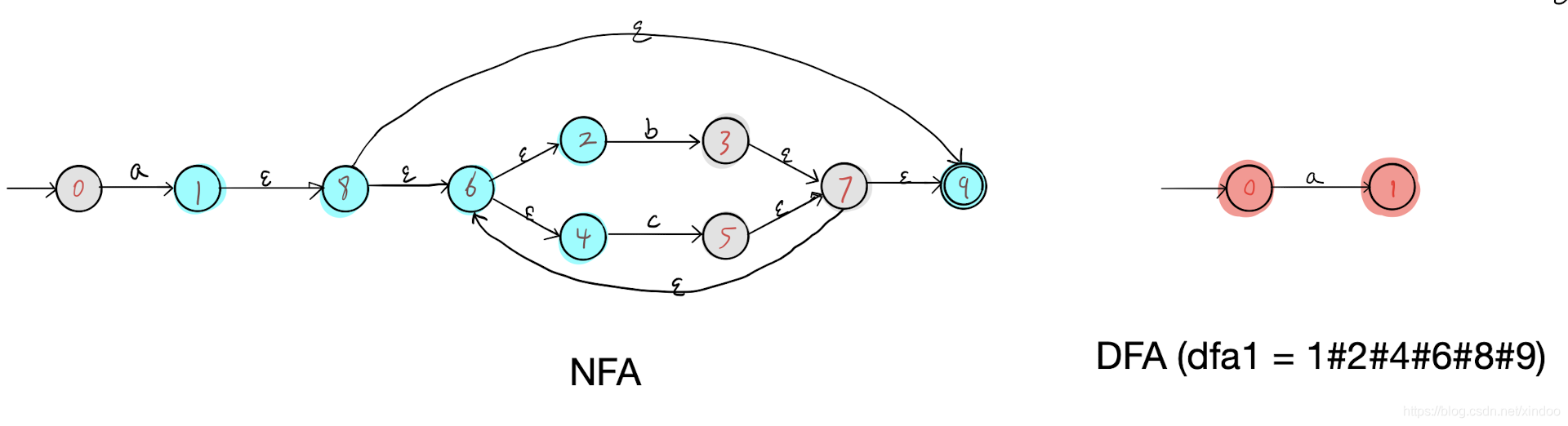
然后对DFA的节点0执行步骤1,找到NFA中所有a可达的NFA节点(1#2#4#6#8#9)构成NFA中的节点1,如下图。
我以dfa1为出发点,发现了a可达的所有NFA节点(2#3#4#6#7#9)和b可达的所有节点(2#4#5#6#7#9),分别构成了DFA中的dfa2和dfa3,如下图。
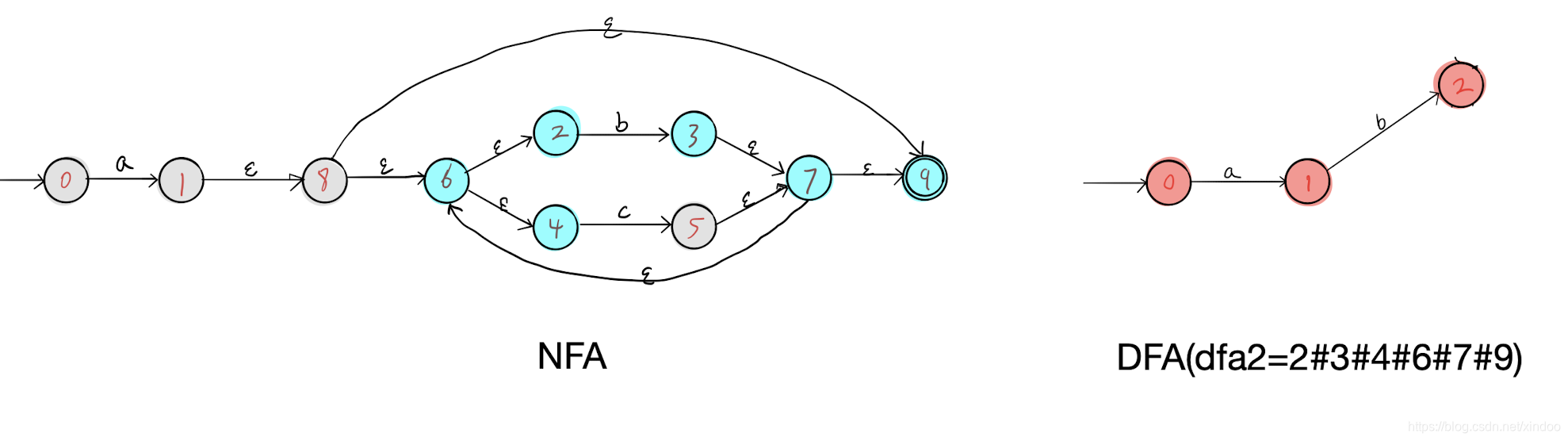
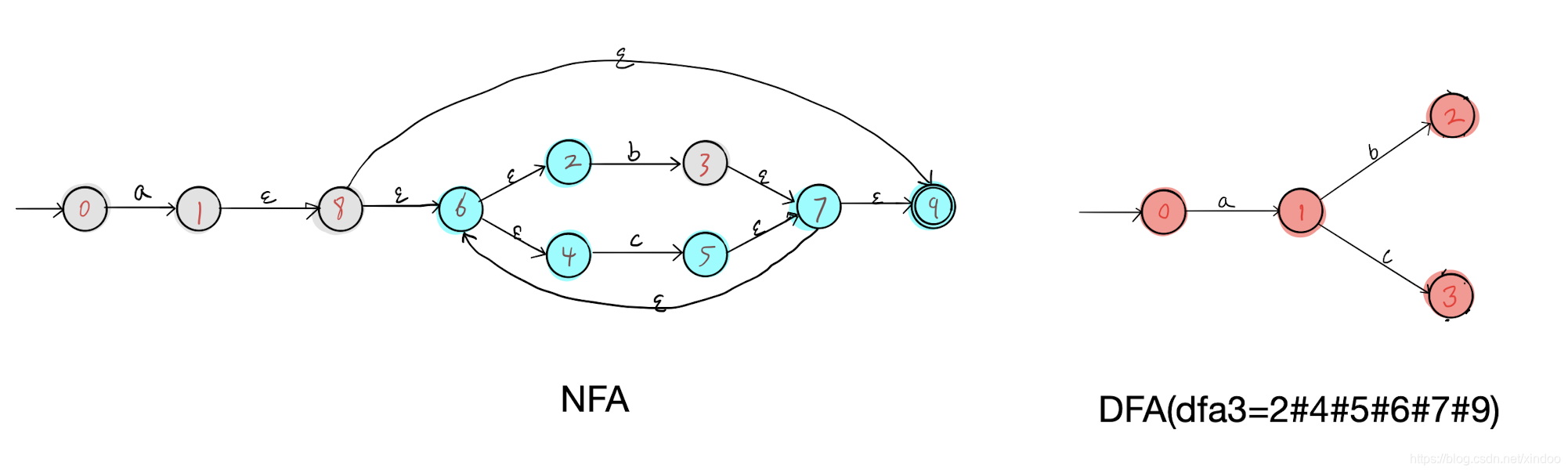
然后我们分别在dfa2 dfa3上执行步骤三,找不到新节点,但会找到几条新的边,补充如下,至此我们就完成了对 a(b|c)* 对应NFA到DFA的转化。
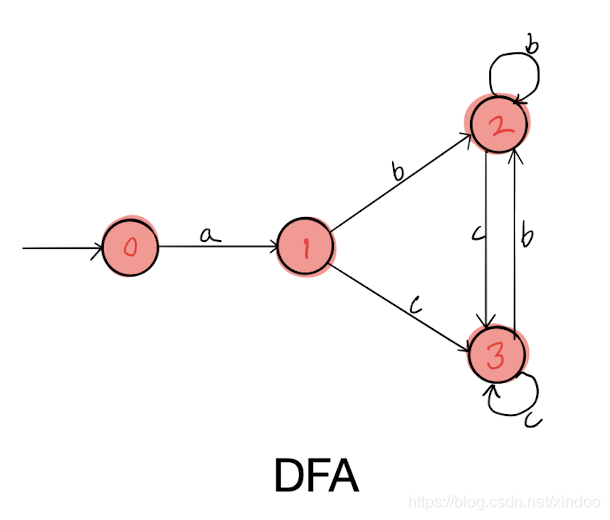
可以看出DFA图节点明显少于NFA,但NFA更容易看出其对应的正则表达式。之前我还写过DFA生成正则表达式的代码,详见文章https://blog.csdn.net/xindoo/article/details/102643270
代码实现
代码其实就是对上文流程的表述,更多细节见https://github.com/xindoo/regex。
/**
* 使用子集构造法把nfa转成dfa,具体可以参考博客 https://blog.csdn.net/xindoo/article/details/106458165
*/
private static DFAGraph convertNfa2Dfa(NFAGraph nfaGraph) {
DFAGraph dfaGraph = new DFAGraph();
Set<State> startStates = new HashSet<>();
// 用NFA图的起始节点构造DFA的起始节点
startStates.addAll(getNextEStates(nfaGraph.start, new HashSet<>()));
if (startStates.size() == 0) {
startStates.add(nfaGraph.start);
}
dfaGraph.start = dfaGraph.getOrBuild(startStates);
Queue<DFAState> queue = new LinkedList<>();
Set<DFAState> finishedStates = new HashSet<>();
// 如果BFS的方式从已找到的起始节点遍历并构建DFA
queue.add(dfaGraph.start);
while (!queue.isEmpty()) {
// 对当前节点已添加的边做去重,不放到queue和next里.
Set<DFAState> addedNextStates = new HashSet<>();
DFAState curState = queue.poll();
for (State nfaState : curState.nfaStates) {
Set<State> nextStates = new HashSet<>();
Set<String> finishedEdges = new HashSet<>();
finishedEdges.add(Constant.EPSILON);
for (String edge : nfaState.next.keySet()) {
if (finishedEdges.contains(edge)) {
continue;
}
finishedEdges.add(edge);
Set<State> efinishedState = new HashSet<>();
for (State state : curState.nfaStates) {
Set<State> edgeStates = state.next.getOrDefault(edge, Collections.emptySet());
nextStates.addAll(edgeStates);
for (State eState : edgeStates) {
// 添加E可达节点
if (efinishedState.contains(eState)) {
continue;
}
nextStates.addAll(getNextEStates(eState, efinishedState));
efinishedState.add(eState);
}
}
// 将NFA节点列表转化为DFA节点,如果已经有对应的DFA节点就返回,否则创建一个新的DFA节点
DFAState nextDFAstate = dfaGraph.getOrBuild(nextStates);
if (!finishedStates.contains(nextDFAstate) && !addedNextStates.contains(nextDFAstate)) {
queue.add(nextDFAstate);
addedNextStates.add(nextDFAstate); // 对queue里的数据做去重
curState.addNext(edge, nextDFAstate);
}
}
}
finishedStates.add(curState);
}
return dfaGraph;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
DFA引擎匹配过程
dfa引擎的匹配也可以完全复用NFA的匹配过程,所以对之前NFA的匹配代码,可以针对DFA模式取消回溯即可(不取消也没问题,但会有性能影响)。
private boolean isMatch(String text, int pos, State curState) {
if (pos == text.length()) {
if (curState.isEndState()) {
return true;
}
for (State nextState : curState.next.getOrDefault(Constant.EPSILON, Collections.emptySet())) {
if (isMatch(text, pos, nextState)) {
return true;
}
}
return false;
}
for (Map.Entry<String, Set<State>> entry : curState.next.entrySet()) {
String edge = entry.getKey();
// 如果是DFA模式,不会有EPSILON边
if (Constant.EPSILON.equals(edge)) {
for (State nextState : entry.getValue()) {
if (isMatch(text, pos, nextState)) {
return true;
}
}
} else {
MatchStrategy matchStrategy = MatchStrategyManager.getStrategy(edge);
if (!matchStrategy.isMatch(text.charAt(pos), edge)) {
continue;
}
// 遍历匹配策略
for (State nextState : entry.getValue()) {
// 如果是DFA匹配模式,entry.getValue()虽然是set,但里面只会有一个元素,所以不需要回溯
if (nextState instanceof DFAState) {
return isMatch(text, pos + 1, nextState);
}
if (isMatch(text, pos + 1, nextState)) {
return true;
}
}
}
}
return false;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
因为DFA的匹配不需要回溯,所以可以完全改成非递归代码。
private boolean isDfaMatch(String text, int pos, State startState) {
State curState = startState;
while (pos < text.length()) {
boolean canContinue = false;
for (Map.Entry<String, Set<State>> entry : curState.next.entrySet()) {
String edge = entry.getKey();
MatchStrategy matchStrategy = MatchStrategyManager.getStrategy(edge);
if (matchStrategy.isMatch(text.charAt(pos), edge)) {
curState = entry.getValue().stream().findFirst().orElse(null);
pos++;
canContinue = true;
break;
}
}
if (!canContinue) {
return false;
}
}
return curState.isEndState();
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
DFA和NFA引擎性能对比
我用jmh简单做了一个非严格的性能测试,随手做的 看看就好,结果如下:
Benchmark Mode Cnt Score Error Units
RegexTest.dfaNonRecursion thrpt 2 144462.917 ops/s
RegexTest.dfaRecursion thrpt 2 169022.239 ops/s
RegexTest.nfa thrpt 2 55320.181 ops/s
- 1
- 2
- 3
- 4
DFA的匹配性能远高于NFA,不过这里居然递归版还比非递归版快,有点出乎意料, 详细测试代码已传至Github https://github.com/xindoo/regex,欢迎查阅。
参考资料
文章来源: xindoo.blog.csdn.net,作者:xindoo,版权归原作者所有,如需转载,请联系作者。
原文链接:xindoo.blog.csdn.net/article/details/106458165

- 点赞
- 收藏
- 关注作者
评论(0)